- The paper introduces an innovative compiler-based quantization method that avoids retraining by using local metrics for layer-specific precision selection.
- The paper achieves linear computational complexity and reports up to a 10.28% increase in accuracy and a 12.52% boost in speed on various deep learning models.
- The paper employs operator fusion and optimized metric analysis to drastically reduce sensitivity list generation time, enhancing practical deployment on embedded devices.
QuantuneV2: Compiler-Based Local Metric-Driven Mixed Precision Quantization
Introduction
The rapid growth of deep learning model sizes, driven by improvements in performance with extensive architectures, necessitates efficient deployment methods on resource-constrained devices. Quantization is a prominent solution, converting model parameters from high-precision floating-point to lower bit-widths, thus decreasing computational demands and power consumption while maintaining accuracy. QuantuneV2 addresses significant limitations in traditional mixed-precision quantization methods, which typically require retraining and overlook computational overhead from frequent quantization operations. QuantuneV2 offers a compiler-based strategy to execute mixed-precision quantization efficiently at the compiler level, enhancing practical applicability.
Methodology
QuantuneV2 operates with a computational complexity of O(n), which scales linearly with the number of model parameters. This contrasts with traditional methods that necessitate comprehensive searches across large bit-width configuration spaces. The efficiency arises from a two-inference process, performed once pre-quantization and once post-quantization. This approach substantially improves speed and throughput compared to retraining-dependent strategies. Local metrics such as weights, activations, Signal-to-Quantization-Noise Ratio (SQNR), and Mean Squared Error (MSE) are employed to stabilize sensitivity analysis, providing robust criteria for layer-specific precision selection.
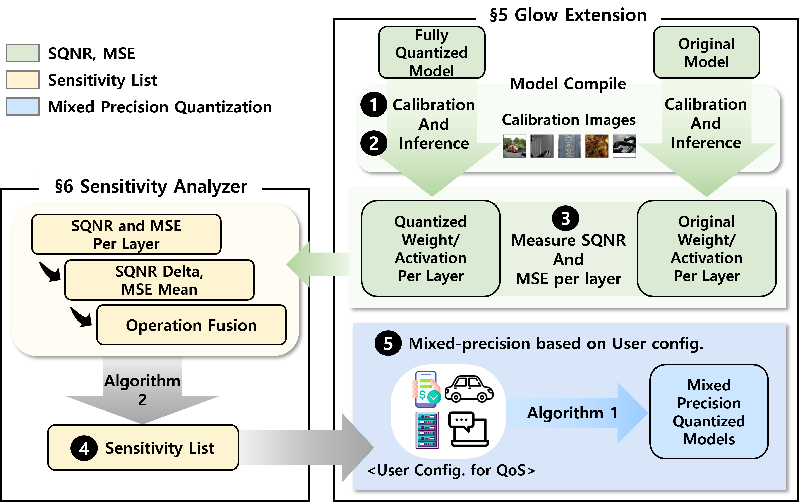
Figure 1: Overview of QuantuneV2.
To address the high inference latency common in traditional quantization, QuantuneV2 integrates operator fusion strategies, reducing run-time computational overhead. It combines precision scaling with operator fusion to attain optimal intermediate representations essential for efficient embedded application deployment.
Results
QuantuneV2 demonstrated a substantial improvement over existing quantization methods. Evaluated on models such as ResNet18v1, ResNet50v1, SqueezeNetv1, VGGNet, and MobileNetv2, QuantuneV2 achieved up to a 10.28% increase in inference accuracy and a 12.52% hike in speed. These results underscore its capability to maintain or improve accuracy while significantly reducing computational demands.
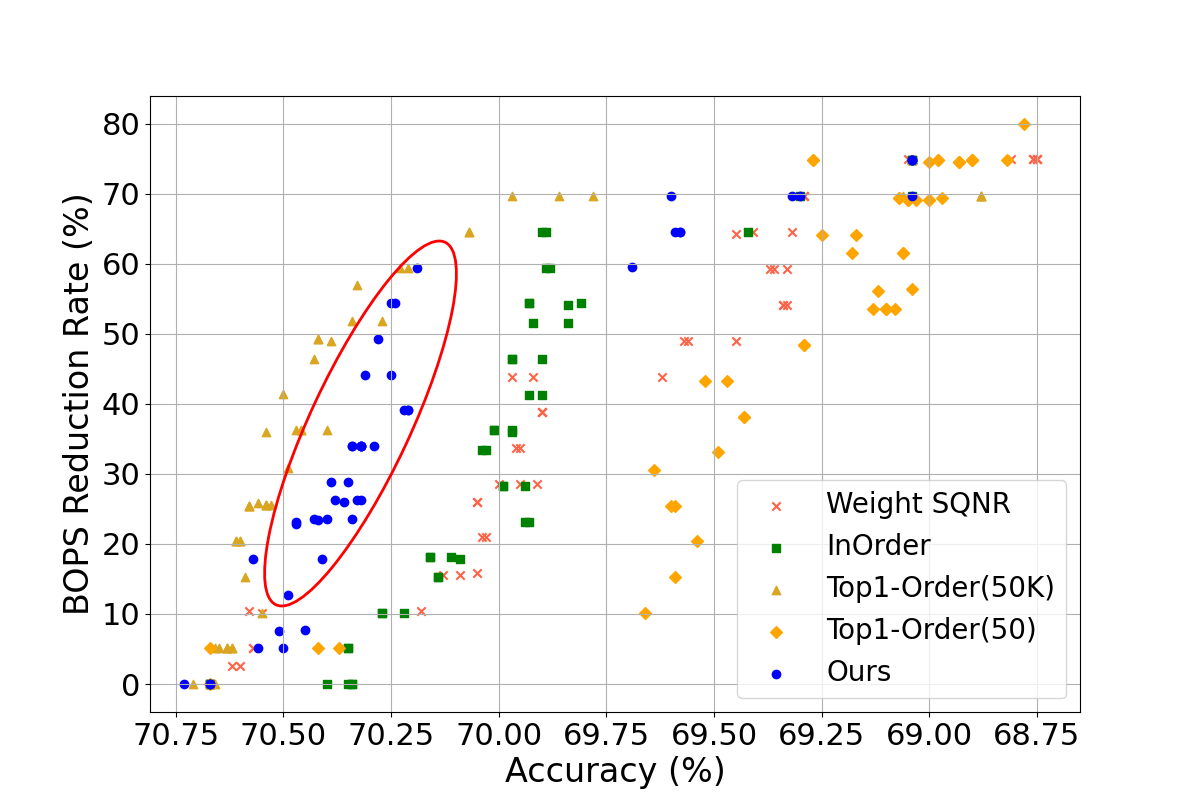
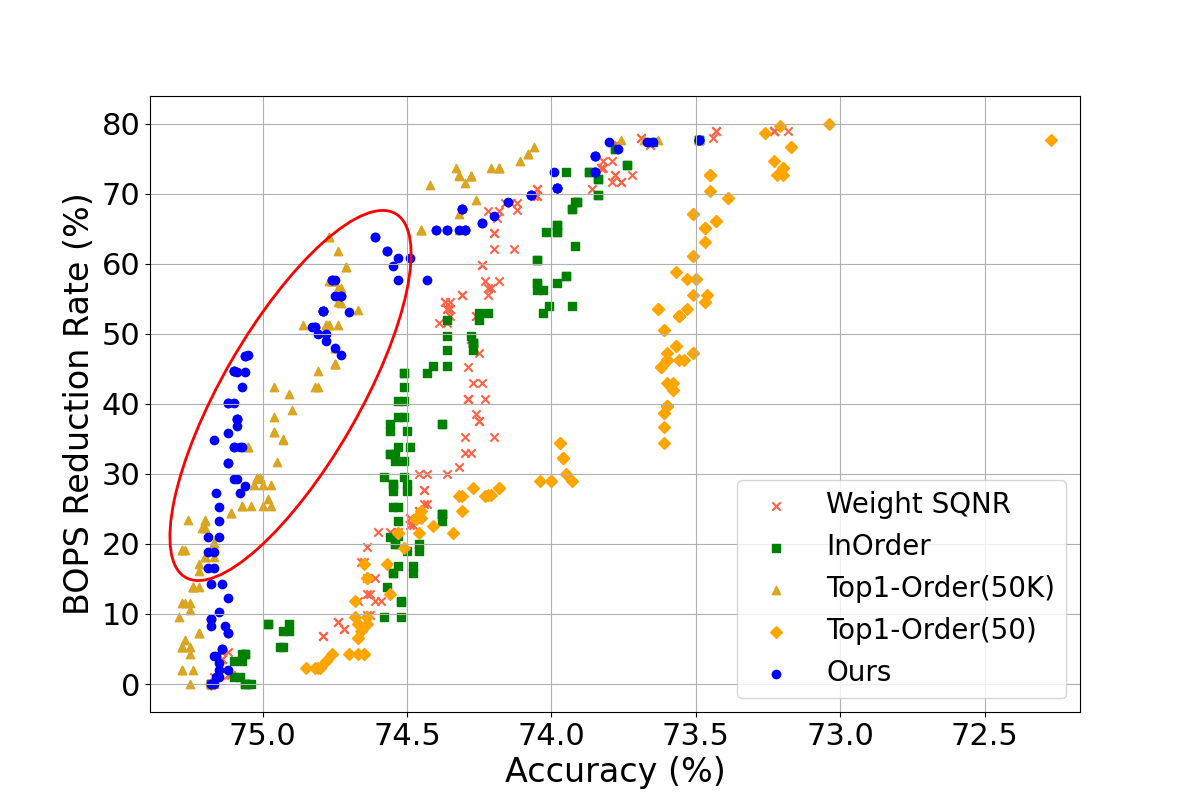
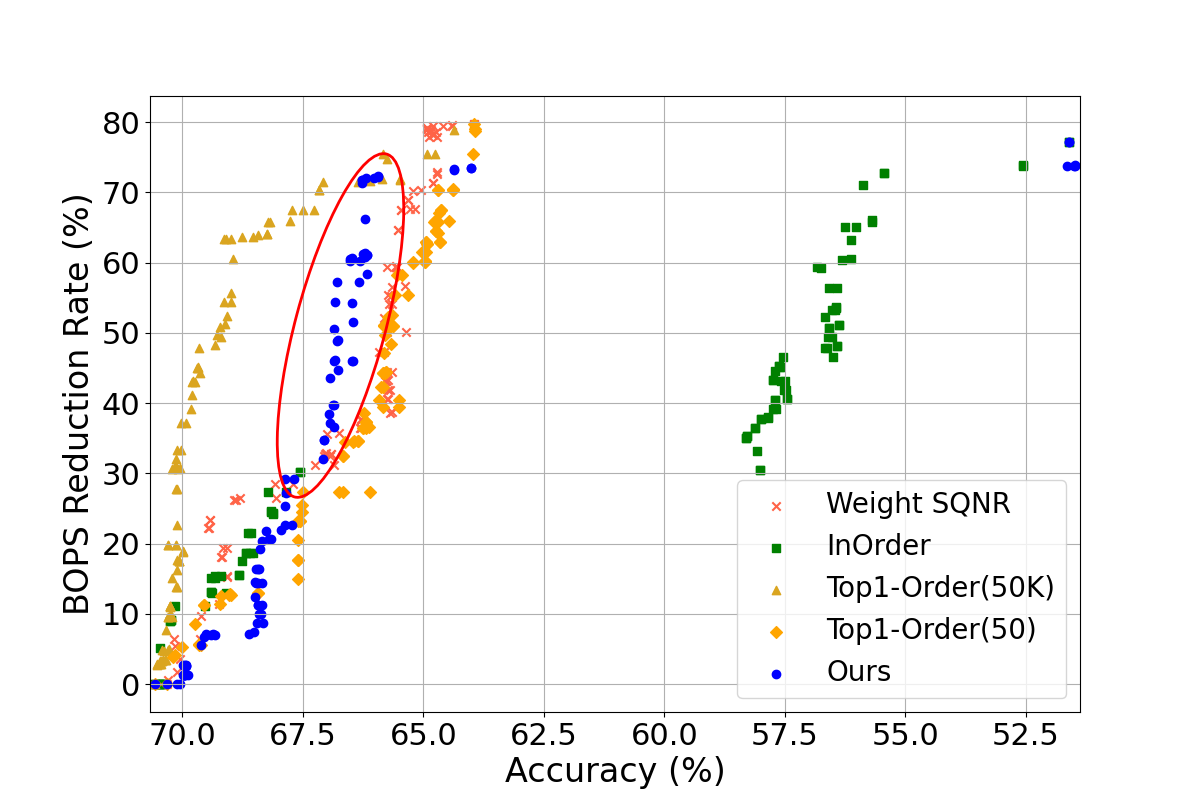
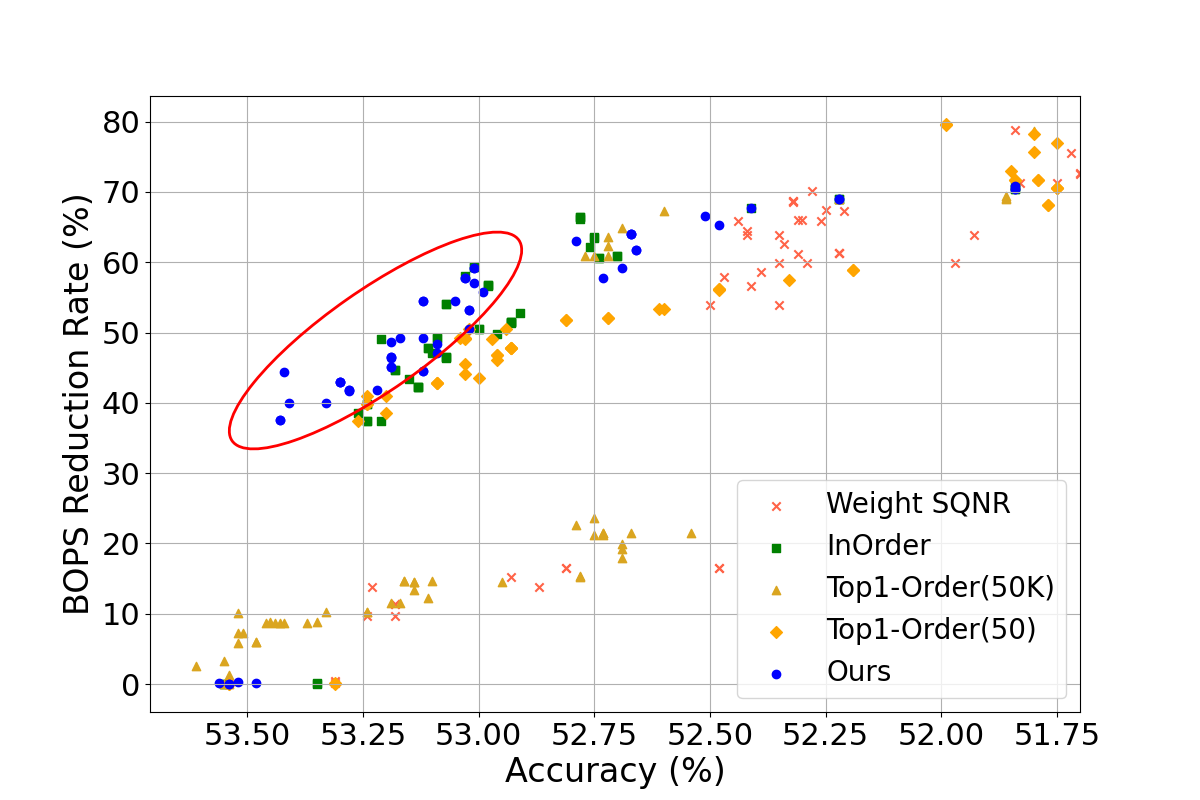
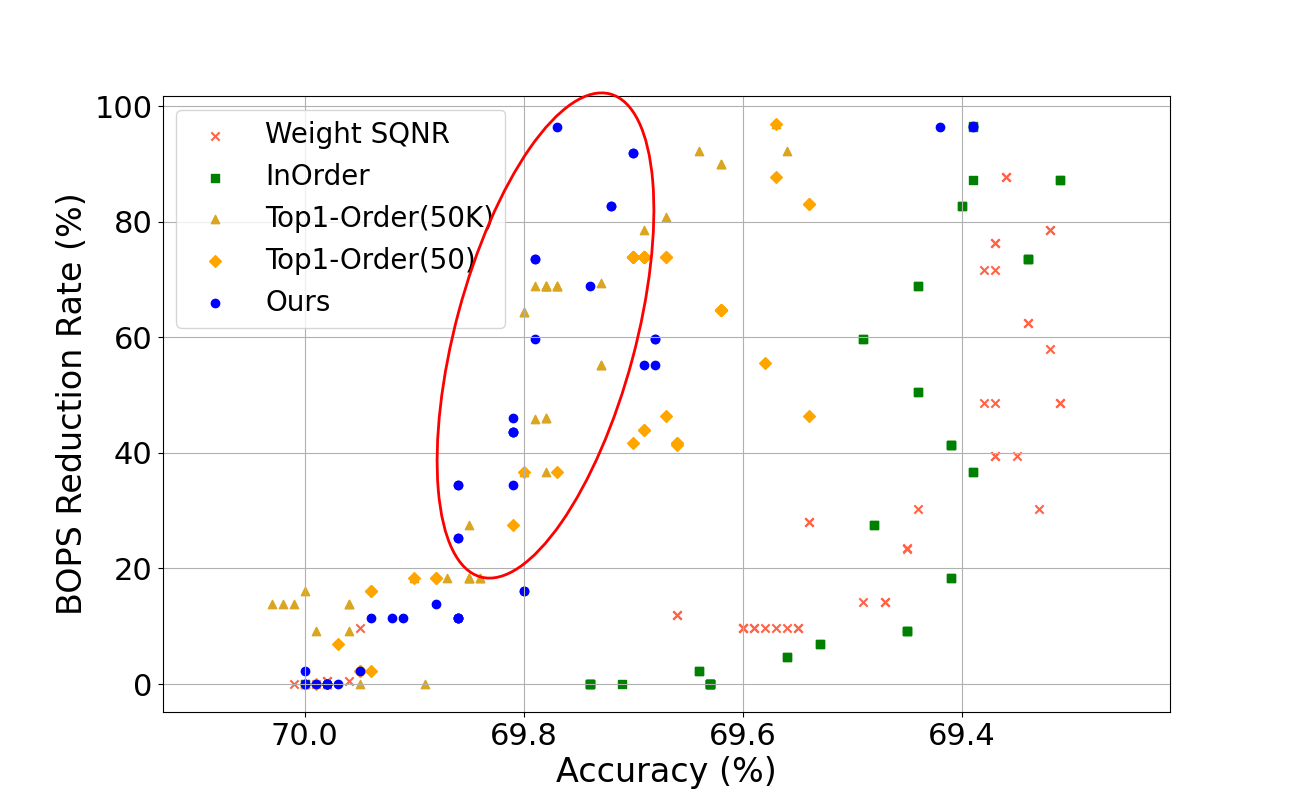
Figure 2: Comparison of model accuracy according to BOPs reduction rate of DNN models (BOPs reduction rate 0\%: original model, 100\%: fully quantized model).
Through optimized local metric application and compiler-level implementation, QuantuneV2 notably accelerates sensitivity list generation—99.99% faster than some existing methods—demonstrating remarkable efficacy in rapid deployment contexts.
Discussion and Implications
The development of QuantuneV2 revolutionizes the mixed-precision quantization domain by aligning model precision with the inherent deployment constraints of embedded AI environments. This approach promotes efficiency without the typical accuracy trade-offs associated with quantization. Its implications extend beyond active deployment, stimulating future explorations in compiler-level optimizations and fine-grained precision tuning. Additionally, the methodology offers a scalable framework for applying precision adjustments to larger and more complex neural networks, paving the way for advancements in scalable AI solutions.
QuantuneV2's framework hints at potentially broader applications in a variety of hardware platforms, including those with limited computational resources. Future research could investigate adaptive quantization mechanisms that further streamline inference processes and integrate non-linear optimization techniques for enhanced bit-width distributions.
Conclusion
QuantuneV2 provides a substantial leap forward in embed AI applications via compiler-based mixed-precision quantization, showcasing significant gains in efficiency and performance with measurable benefits across a range of deep learning models. Its pioneering approach demonstrates the feasibility of avoiding retraining while achieving high accuracy and operational speed, ensuring its role as a cornerstone methodology in the evolving landscape of deep learning deployment strategies.