- The paper introduces a dual-autoregressive neural network framework that combines historical data and predicted outputs for long-horizon robotic simulation.
- It employs a self-supervised training paradigm to mitigate error accumulation, enhancing robustness under noise and varied robotic tasks.
- The framework bridges the sim-to-real gap by optimizing policies using simulated rollouts, achieving successful transfer on real hardware like ANYmal D.
Robotic World Model: A Neural Network Simulator for Robust Policy Optimization in Robotics
Introduction
The paper "Robotic World Model: A Neural Network Simulator for Robust Policy Optimization in Robotics" introduces a new framework for developing world models in robotics. The focus is on achieving reliable long-horizon predictions without relying on domain-specific inductive biases. The proposed framework employs a dual-autoregressive mechanism and self-supervised training to enhance robustness and adaptability across diverse robotic tasks. The researchers effectively bridge the gap between data-driven modeling and real-world deployment by leveraging a novel policy optimization framework that allows seamless deployment across various systems, including real-world robotic hardware.
Dual-Autoregressive Mechanism
At the core of this framework is the dual-autoregressive mechanism, which enhances the model's capacity to make accurate long-horizon predictions by combining both historical context and future predictions. The architecture employs a GRU-based model that processes historical observations and actions in sequence, thereby updating the hidden state with each step (Figure 1).
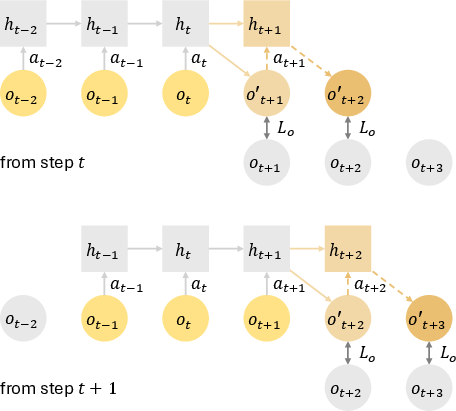
Figure 1: Dual-autoregressive mechanism employed in RWM. Inner autoregression updates GRU hidden states after each historical step within the context horizon, while outer autoregression feeds predicted observations from the forecast horizon back into the network. The dashed arrows denote the sequential autoregressive prediction steps, highlighting robustness to long-term dependencies and transitions.
Self-supervised Autoregressive Training
The training methodology emphasizes a self-supervised autoregressive paradigm in which the model predicts future observations based on both past data and its own predictive outputs. This is iteratively performed over a defined forecast horizon, reducing errors typically compounded in long-horizon predictions. By using historical data, the model mitigates error accumulation effectively compared to more traditional training frameworks like teacher-forcing (Figure 2).
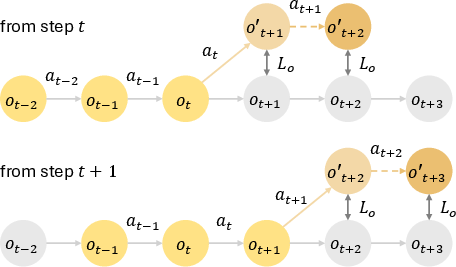
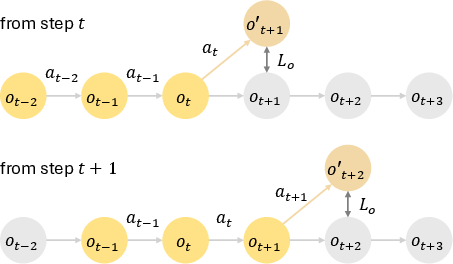
Figure 2: Autoregressive training.
Policy Optimization with Learned World Models
The researchers incorporate a policy optimization strategy inspired by Model-Based Policy Optimization (MBPO). Using a replay buffer to store real environment interactions, the framework couples direct environment sampling with simulation rollouts using the learned world model. This approach leverages simulated data to refine policies iteratively, bridging the sim-to-real gap. MBPO-PPO, a tailored implementation of Proximal Policy Optimization, demonstrates superior robustness and efficiency in policy learning, outperforming existing frameworks such as Dreamer and SHAC.
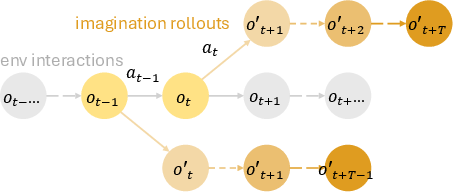
Figure 3: Model-Based Policy Optimization with learned world models. The framework combines real environment interactions with simulated rollouts for efficient policy optimization. Observation and action pairs from the environment are stored in a replay buffer and used to train the autoregressive world model. Imagination rollouts using the learned model predict future states over a horizon of T, providing trajectories for policy updates through reinforcement learning algorithms.
Experimental Results
Comprehensive experiments demonstrate the effectiveness of RWM across diverse robotic settings. Key outcomes include:
- Autoregressive Trajectory Prediction: RWM exhibits minimal deviation from ground truth trajectories, highlighting its robustness and error mitigation capabilities compared to alternative baselines (Figure 4).
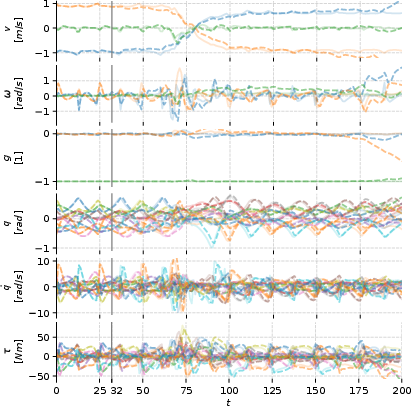
Figure 4: Autoregressive trajectory prediction by RWM. Solid lines represent ground truth trajectories, while dashed lines denote predicted state evolution. The control frequency of the robot is at 50\,Hz. The model is trained with history horizon M = 32 and forecast horizon N = 8. Predictions commence at t = 32 using historical observations, with future observations predicted autoregressively by feeding prior predictions back into the model.
- Robustness Under Noise: RWM maintains lower prediction errors under noise perturbations compared to MLP-based baselines, showcasing improved resilience (Figure 5).
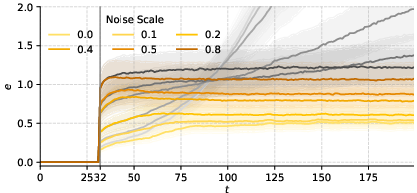
Figure 5: Autoregressive trajectory prediction error under Gaussian noise. Yellow curves denote RWM at varying noise levels, demonstrating consistent robustness and lower error accumulation across forecast steps. Grey curves represent the MLP baseline, which exhibits significantly higher error accumulation and reduced robustness to noise.
- Policy Learning and Hardware Transfer: Policies optimized using RWM are successfully deployed in a zero-shot transfer to ANYmal\,D hardware, overcoming significant challenges associated with sim-to-real performance loss.
Limitations
The trade-offs between computational efficiency and prediction accuracy are notable, as extending both history and forecast horizons improves performance but incurs increased training times. Furthermore, improved continual adaptation in dynamic real-world scenarios remains an open challenge, requiring further exploration into robust learning under uncertainty.
Conclusion
The introduction of Robotic World Model contributes significantly to model-based reinforcement learning by offering a robust, scalable framework capable of tackling the challenges of sim-to-real transfer, error accumulation, and long-horizon prediction in robotics. The framework's adaptability across diverse tasks underscores its potential to drive advancements in efficient, real-world robotic applications, paving the way for more intelligent and adaptive robotic systems.