- The paper demonstrates that microbenchmarking uncovers Hopper’s innovations in tensor cores and memory hierarchies, achieving notable improvements in computational throughput.
- It utilizes fine-grained benchmarks to highlight results such as a 1.5× speedup in matrix multiplication and a 13× gain in dynamic programming tasks.
- The study underscores the importance of tailored configuration and asynchronous execution to optimize energy efficiency and overall system performance.
Analysis of the NVIDIA Hopper Architecture: A Microbenchmarking Perspective
The paper presents a detailed analysis of the NVIDIA Hopper GPU architecture through microbenchmarking and multi-level performance evaluation. The study provides insights into the enhancements of the Hopper architecture over its predecessors and offers recommendations for optimizing its use in various computational workloads.
Architecture Overview
The NVIDIA Hopper architecture introduces several key advancements over previous GPU architectures like Ampere and Ada Lovelace. Notably, Hopper features improved tensor cores which now support FP8 precision and asynchronous execution via wgmma instructions, enhancing its capability for AI and scientific computations that require high throughput and efficiency.
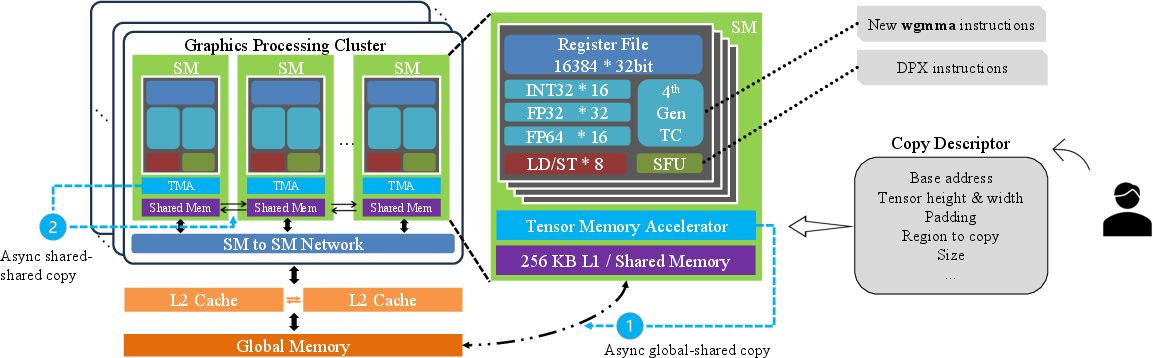
Figure 1: Hopper architecture and new features
Memory Subsystem
Latency and Throughput
Hopper improves memory latency and throughput, crucial for compute-intensive workloads. The partitioned L2 cache design offers distinct latency benefits, reducing access latencies significantly compared to earlier architectures. Through fine-grained microbenchmarks, the study demonstrates that using vectorized memory access (e.g., FP32.v4) can substantially boost throughput across L1, L2, and global memory, highlighting the architectural efficiency of Hopper.
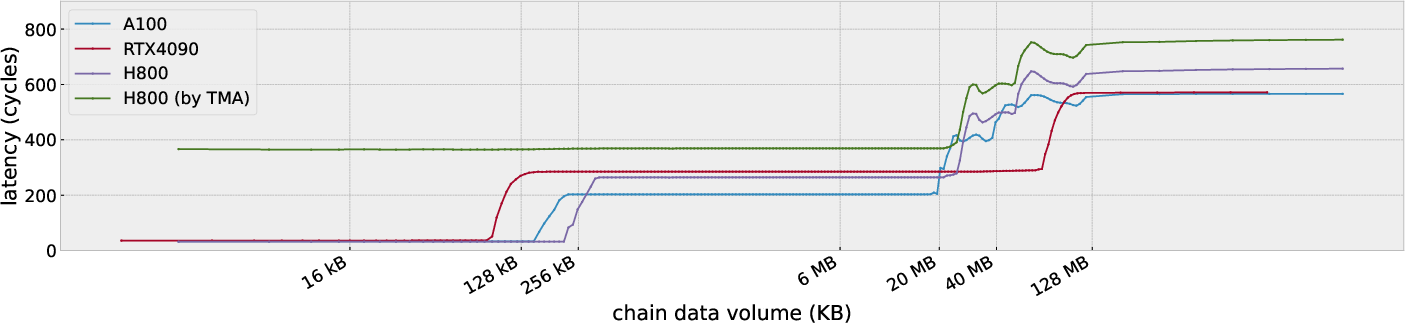
Figure 2: Latency clocks of different memory scopes
Tensor Memory Accelerator
Asynchronous Execution
The Tensor Memory Accelerator (TMA) in Hopper enables efficient asynchronous data transfers, reducing the overhead associated with traditional memory movements. The novel design allows for automated address and data handling, providing a significant performance gain in matrix operations, notably achieving a 1.5× speedup in matrix multiplication tasks.
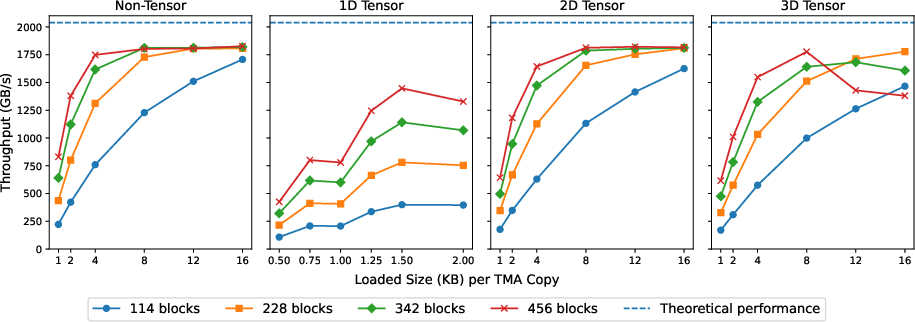
Figure 3: Global memory throughput of different combinations of block numbers and TMA load sizes
For maximum efficacy, configuring the TMA load shapes appropriately is critical. Utilizing load shapes with a sufficiently large x-axis dimension ensures peak performance, especially when integrated with asynchronous computational pipelines.
Tensor Cores and Computation
Synchronous vs. Asynchronous Instructions
Hopper introduces the wgmma instruction set, which supports asynchronous execution by a warp-group. When appropriately utilized, wgmma can achieve near-peak theoretical performance, particularly with larger matrix sizes (N ≥ 64), underscoring the importance of these instructions for optimizing computational throughput.

Figure 4: The mma and wgmma instructions that perform D=A×B+C and D=A×B{+D}, respectively.
Energy Efficiency and Precision
Despite achieving high performance, the wgmma instructions approach the power wall constraints on Hopper, which can lead to reduced operational frequency during power-intensive loads. While FP8 format supports higher throughput for large-scale operations, the conversion overhead for small matrices reduces its effectiveness, necessitating careful precision selection aligned with workload characteristics.
Distributed Shared Memory (DSM)
DSM in Hopper facilitates direct inter-SM communication, significantly reducing communication latency by 6.1× compared to previous architectures. However, the performance gains are closely tied to the access patterns and scheduling strategies employed, requiring careful optimization to maximize throughput in systems with high shared memory demand.
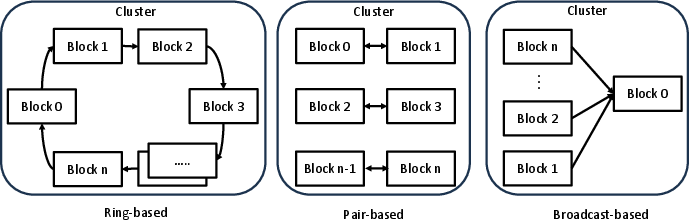
Figure 5: Scenarios for DSM throughput testing
Dynamic Programming Instructions
Hopper's hardware-accelerated DPX instructions considerably boost performance for dynamic programming algorithms, demonstrating up to a 13× improvement over software emulation in the instruction-level analysis. The Smith-Waterman algorithm, a representative biological computation, benefits substantially from these improvements, achieving a 4.75× speedup on H800 using 16-bit integer DPX instructions.
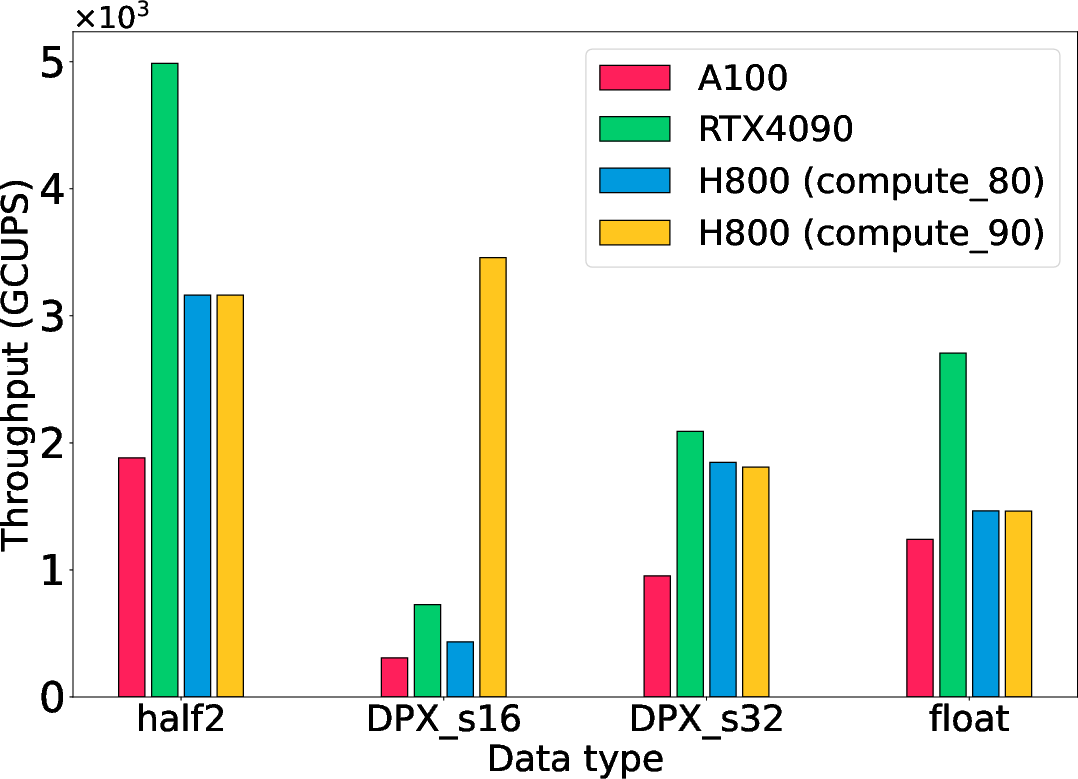
Figure 6: Performance of the Smith-Waterman algorithm across various data types
Conclusion
The comprehensive analysis of the NVIDIA Hopper architecture showcases its significant advancements in memory hierarchy, tensor core capabilities, and specialized hardware instructions. While Hopper excels in dense computational tasks, achieving the highest performance requires strategic use of its asynchronous capabilities and careful configuration of computational workloads to mitigate power constraints. Future research should explore fully leveraging DSM, optimizing DPX-related transformations, and integrating emerging asynchronous strategies across diverse applications in AI, scientific computing, and dynamic programming.