- The paper demonstrates that APD effectively decomposes neural network parameters into components that are faithful representations of underlying mechanisms.
- It employs gradient-based attributions to ensure minimal and simple parameter usage while preserving overall network functionality.
- Experiments on toy models show APD accurately identifies superposed and distributed representations, offering a parameter-centric view of interpretability.
Interpretability in Parameter Space: Minimizing Mechanistic Description Length with Attribution-based Parameter Decomposition
Introduction
The paper "Interpretability in Parameter Space: Minimizing Mechanistic Description Length with Attribution-based Parameter Decomposition" (2501.14926) focuses on enhancing the interpretability of neural networks by decomposing their parameters into understandable components. The authors introduce Attribution-based Parameter Decomposition (APD), a method designed to break down a network's parameters into vectors representing distinct mechanisms. This approach strives to ensure that these components are faithful to the original network, require minimal usage for any input, and remain simple.
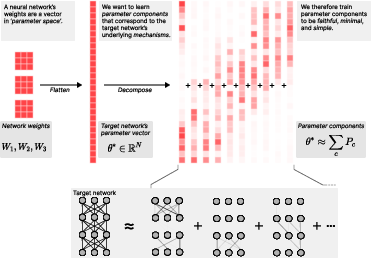
Figure 1: Decomposing a target network's parameters into parameter components that are faithful, minimal, and simple.
Methodology
APD operates by processing the parameter vector of a neural network into a sum of parameter components optimized for minimal description length. The method does this by:
- Faithfulness: Ensuring that the sum of parameter components equals the network's original parameters.
- Minimality: Reducing the number of active components needed to process an input effectively.
- Simplicity: Decomposing components to span minimal directions in activation space.
The procedure employs gradient-based attributions to determine which components are active for particular inputs, utilizing a top-k approach where the most significant contributors are selected for forward operations. This minimizes the computational footprint by reducing active parameters based on their attributions.
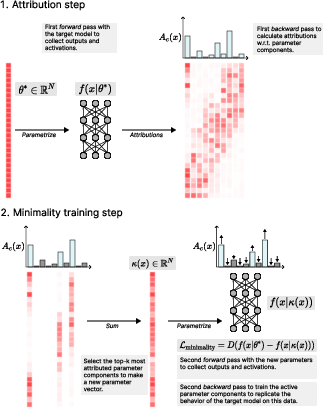
Figure 2: Top: Step 1: Calculating parameter component attributions Ac(x). Bottom: Step 2: Optimizing minimality loss L′.
Experiments
The efficacy of APD is demonstrated through several toy models:
- Toy Model of Superposition: APD successfully identifies ground truth mechanisms corresponding to different input features represented in superposition within the hidden layers of the network. The parameter components learned closely align with the columns of the original weight matrix, indicating robust decomposition.
- Toy Model of Compressed Computation: In a scenario where a model computes more functions than it has neurons, APD effectively learns components that accurately map the individual functions. This scenario highlights APD's ability to capture complex, nonlinear computations distributed over fewer computational resources.
- Cross-Layer Distributed Representations: Extending the compressed computation task to multiple layers demonstrates APD's capability to identify mechanisms spanning across layers, maintaining a high degree of fidelity and simplicity in parameter decomposition.
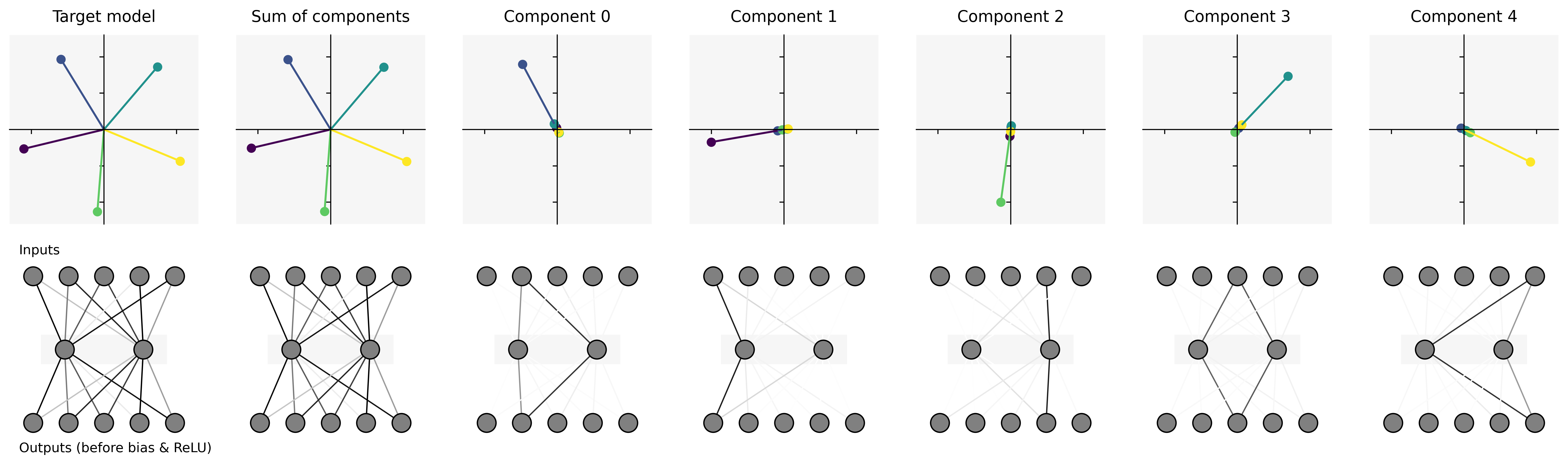
Figure 3: Results of running APD on TMS. Top row: Plot of the columns of the weight matrix of the target model, the sum of the APD parameter components, and each individual parameter component. Each parameter component corresponds to one mechanism, which in this model each correspond to one `feature' in activation space.
Discussion
APD stands out by offering a parameter-centric approach to interpretability, which contrasts with the activation-centric methods like sparse dictionary learning. The paper addresses several challenges inherent in traditional approaches:
- Canonical Unit Identification: APD provides a robust framework for identifying minimal circuits in superposition, overcoming limitations encountered in previous methods due to feature splitting and reconstruction errors.
- Conceptual Clarity: By proposing a new definition of features as properties activating specific mechanisms, APD offers a fresh lens for understanding feature geometry.
- Architecture-Agnostic: The method's ability to operate across different neural network architectures without modification empowers a more generalized approach to interpretability.
Conclusion
This research introduces a novel methodology for mechanistic interpretability that emphasizes parameter space decomposition, offering promising results even in toy settings. The approach not only fosters a deeper understanding of AI systems' internal mechanics but also opens avenues for future research aiming to apply these principles to more complex models. APD's framework is poised to enhance explainability in AI, particularly as systems increase in complexity and versatility.