- The paper introduces the MVGD architecture that uses diffusion-based modeling to directly generate novel images and depth maps.
- It leverages scene scale normalization and learnable task embeddings to ensure consistent, scale-aware predictions across diverse datasets.
- Experiments demonstrate state-of-the-art performance in PSNR, SSIM, and LPIPS metrics on benchmark datasets like RealEstate10k and ScanNet.
Multi-View Geometric Diffusion for Zero-Shot Novel View and Depth Synthesis
Overview
"Zero-Shot Novel View and Depth Synthesis with Multi-View Geometric Diffusion" presents a novel architecture named Multi-View Geometric Diffusion (MVGD). This architecture aims to directly generate images and depth maps from new perspectives using a diffusion-based model. The framework is designed to eliminate the need for intermediate 3D representations, which are typically employed in novel view synthesis tasks. The key innovation involves using a diffusion process with scene scale normalization, learnable task embeddings, and novel conditioning methodologies to achieve scale-aware and consistent predictions across different viewpoints.
Methodology
MVGD Architecture
MVGD is a diffusion-based model that learns a distribution to generate novel images and depth maps given a set of input views and camera parameters. The model employs Recurrent Interface Networks (RIN) to optimize computation, allowing it to manage multiple conditioning views efficiently. The emphasis is on direct pixel-level generation, avoiding reliance on auto-encoders found in traditional latent diffusion models.
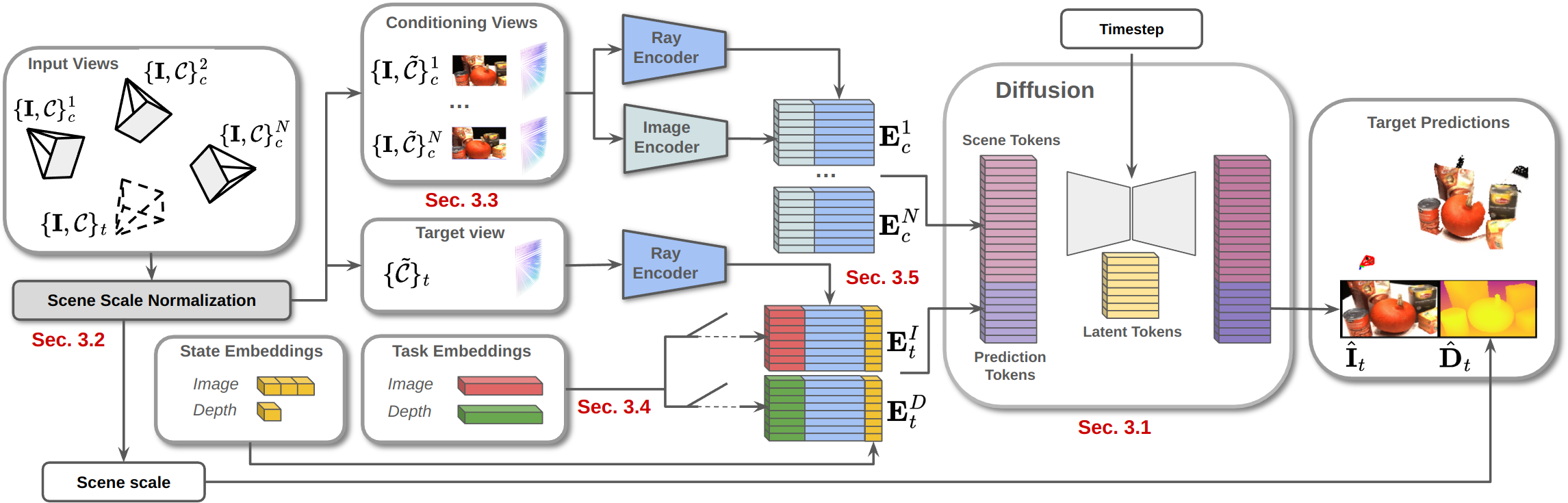
Figure 1: Diagram of our proposed Multi-View Geometric Diffusion (MVGD) framework, at inference time.
Task Embeddings and Scene Scale Normalization
The architecture employs learnable task embeddings to guide the generation towards specific modalities, allowing joint training for both image and depth synthesis. Scene Scale Normalization (SSN) is introduced to handle scale differences across diverse datasets, ensuring that generated depth maps maintain consistency with the conditioning cameras' scale.
Training Strategy
The model is trained on a vast dataset of over 60 million multi-view samples from a variety of sources, ensuring robust performance across diverse scenes. Techniques such as learnable task embeddings and SSN enable consistent learning from heterogeneous data. Additionally, an incremental fine-tuning strategy is proposed, allowing for efficient scaling of model complexity without extensive retraining.
Experiments and Results
The paper conducts extensive experiments showcasing the state-of-the-art performance of MVGD in both novel view synthesis and multi-view stereo depth estimation. Key results highlight its superior performance in PSNR, SSIM, and LPIPS metrics across several benchmarks, including RealEstate10k and ScanNet. MVGD demonstrates strong generalization capabilities, effectively handling zero-shot novel view synthesis tasks.
- Novel View Synthesis: MVGD outperforms previous methods significantly with fewer conditioning views due to its implicit geometric reasoning.
- Depth Estimation: The model's performance in stereo and video depth estimation benchmarks indicates its ability to predict depth maps accurately, even when trained with diverse and sometimes sparse datasets.



Figure 2: MVGD novel view and depth synthesis results, demonstrating its capability to generate scale-consistent predictions.
Limitations and Future Work
While MVGD shows remarkable performance, certain limitations exist, such as the model's inability to handle dynamic scenes explicitly. The introduction of temporal embeddings and motion tokens could enhance its capabilities in this area. Furthermore, the current version of MVGD requires individual generation cycles for multiple viewpoints due to its scene scale normalization approach, suggesting a potential area for efficiency improvements.
Conclusion
This research introduces MVGD, emphasizing its novel approach to direct image and depth generation without relying on intermediate 3D representations. By leveraging a large-scale dataset and innovative training techniques, MVGD achieves impressive results in novel view synthesis and depth estimation, setting a new standard for zero-shot tasks in these domains. Future advances may focus on optimizing computational efficiency and expanding capabilities to dynamic environments.