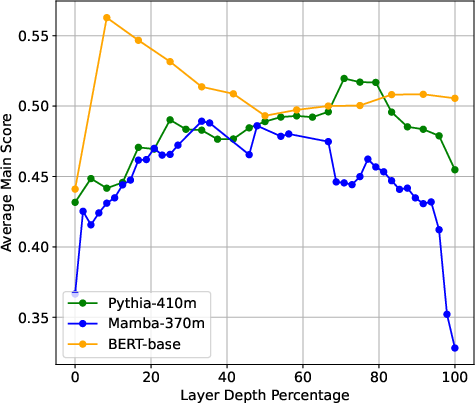
- The paper demonstrates that intermediate layers in language models can improve downstream task accuracy by up to 16% compared to final layers.
- The authors propose a robust framework combining information theory, geometric analysis, and input invariance to assess layer-wise representation quality.
- Empirical analysis across various architectures shows that training objectives significantly influence the distribution of semantic information across layers.
Uncovering Hidden Representations in LLMs
The paper "Layer by Layer: Uncovering Hidden Representations in LLMs" explores the rich and often underutilized information encoded in the intermediate layers of LLMs. Traditionally, it is assumed that the final layers of these models yield the most effective representations for downstream tasks due to their close alignment with output tasks. However, this investigation highlights that intermediate layers can, in fact, be more potent, offering a marked improvement in performance across various tasks when their embeddings are utilized instead.
This conclusion challenges the conventional focus solely on final-layer embeddings, proposing instead that intermediate layers possess unique and valuable features that are inherently overlooked. The authors propose a robust and unified framework of representation quality metrics founded on information theory, geometric analysis, and invariance principles to thoroughly assess and quantify the properties of these hidden layers.
Framework and Methodology
The authors propose a comprehensive framework that brings together three distinct perspectives to understand the representation quality across model layers:
- Information-Theoretic Aspect: This examines how layers compress or retain semantic information. This is crucial for understanding the balance between data compression for efficiency and retention for task-specific details.
- Geometric Analysis: By studying the high-dimensional organization of token embeddings, this perspective sheds light on the structural properties of different layers, providing insight into how embeddings unfold within model space.
- Invariance to Input Perturbations: Evaluating the robustness of embeddings to small input changes helps ascertain the stability and preservation of meaningful features within the layers.
The comprehensive approach unifies these perspectives under a single lens, attributing specific metrics to each, such as prompt entropy, effective rank, curvature, and several augmentation invariance measures like InfoNCE, LiDAR, and DiME.
Empirical Findings
The study involved extensive experiments across various LLM architectures, including Transformers, State Space Models (SSMs), and BERTs, with parameter scales extending from millions to billions. Here are the primary empirical observations:
Theoretical Implications
At the theoretical level, the analysis highlights a key convergence of seemingly disparate metrics into a cohesive framework utilizing matrix-based entropy. Here, the consideration of eigenvalues of Gram matrices informs on representation "spread" or "compression," providing a measure of both local and global data characteristics.
A critical contribution here involves connecting representation metrics such as entropy and curvature with task performance metrics, establishing robust relationships and providing a quantifiable rationale for layer-wise utility in downstream AI applications.
Practical and Future Directions
The practical implications of leveraging mid-layer representations are profound. This study promotes rethinking approaches to model fine-tuning and synthesis of task-specific embeddings, steering towards more efficient, robust, and accurate AI applications. Equally, this insight into intermediate layer efficacy encourages further development of tools and methodologies to strategically exploit these underutilized layers for optimal model performance.
Considering future directions, a potential area of exploration is the effect of different input perturbations on model robustness, expanded cross-domain analysis, and further refinement of training objectives to harness the full potential of intermediate representations.
Conclusion
The paper underscores the transformative potential of mid-layer representations in LLMs, evidencing their superior utility over the final layers for a wide array of tasks. This paradigm shift from the conventional focus on final layers towards embracing the intricate and rich feature sets provided by intermediate layers sets a new course for improving model interpretability, accuracy, and robustness in future AI systems.