Advancing Reasoning in Large Language Models: Promising Methods and Approaches
Abstract: LLMs have succeeded remarkably in various NLP tasks, yet their reasoning capabilities remain a fundamental challenge. While LLMs exhibit impressive fluency and factual recall, their ability to perform complex reasoning-spanning logical deduction, mathematical problem-solving, commonsense inference, and multi-step reasoning-often falls short of human expectations. This survey provides a comprehensive review of emerging techniques enhancing reasoning in LLMs. We categorize existing methods into key approaches, including prompting strategies (e.g., Chain-of-Thought reasoning, Self-Consistency, and Tree-of-Thought reasoning), architectural innovations (e.g., retrieval-augmented models, modular reasoning networks, and neuro-symbolic integration), and learning paradigms (e.g., fine-tuning with reasoning-specific datasets, reinforcement learning, and self-supervised reasoning objectives). Additionally, we explore evaluation frameworks used to assess reasoning in LLMs and highlight open challenges, such as hallucinations, robustness, and reasoning generalization across diverse tasks. By synthesizing recent advancements, this survey aims to provide insights into promising directions for future research and practical applications of reasoning-augmented LLMs.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is a survey. That means the author read lots of recent studies and summed them up. The topic is how to help LLMs—AI systems that read and write text—get better at “reasoning.” Reasoning here means doing step-by-step thinking, like solving math problems, following logic, using common sense, and planning over several steps (not just recalling facts).
What questions does the paper ask?
The paper looks at simple, clear questions:
- What kinds of reasoning do we want AI to do (like deductive logic, common sense, math)?
- Which methods help LLMs think more clearly and make fewer mistakes?
- How do researchers test whether an AI is really reasoning and not just guessing or repeating?
- What problems still get in the way (like “hallucinations,” where the AI makes things up), and how can we fix them?
How do they study it? (Methods and approaches, with simple analogies)
Because this is a survey, the author organizes many ideas from other papers into three big groups. Here they are, explained with everyday examples:
1) Prompting strategies: guiding the AI with better instructions
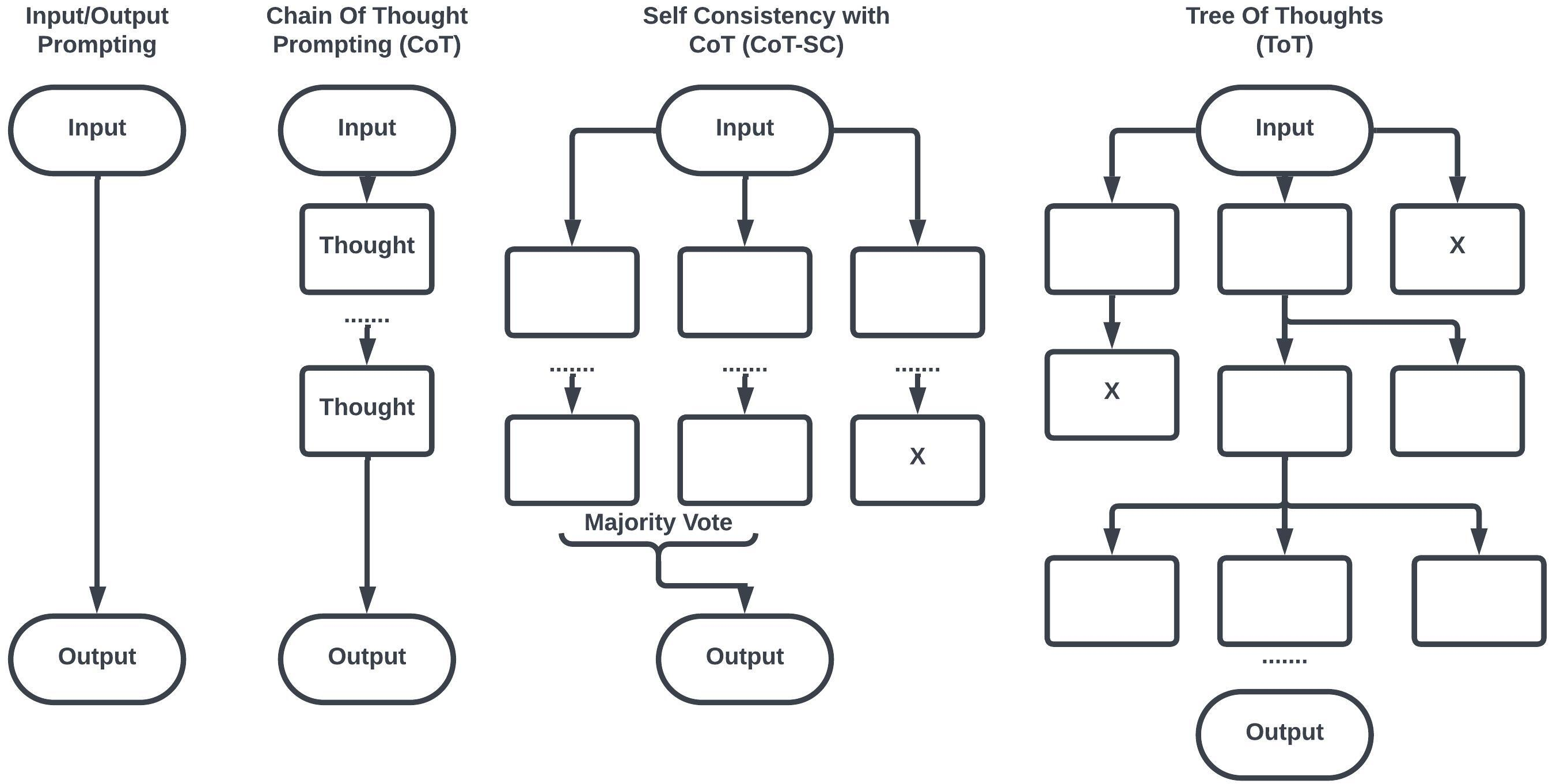
- Chain-of-Thought (CoT): Like “show your work” in math class. The model writes out steps instead of jumping to the answer.
- Self-Consistency: Like solving the same problem several times in different ways and picking the answer most people agree on.
- Tree-of-Thought (ToT): Like a choose-your-own-adventure book. The model explores different branches of reasoning, then picks the best path.
- Program-Aided LLMs (PAL): Like asking a calculator or running a small program to double-check math or logic.
2) Architectural innovations: adding parts that help the model think
- Retrieval-Augmented Generation (RAG): Like looking things up in a library while you write, so you don’t rely only on memory.
- Neuro-Symbolic methods: A team-up: one teammate is great at patterns (neural networks), the other follows strict rules and logic (symbols).
- Memory-augmented models: Like keeping a notebook of important facts you can read and update, so you don’t forget.
- Graph Neural Networks and Knowledge Graphs: Like a city map of facts (places are ideas; roads are relationships) that helps the model reason across connections.
- Tool use and APIs: Like calling a weather app or a calculator when you need exact, up-to-date information.
3) Learning paradigms: training the model to reason better
- Supervised fine-tuning on reasoning data: Like extra practice worksheets for math, logic, and science questions.
- Reinforcement Learning from Human Feedback (RLHF): Like a coach who scores your answers and encourages better thinking over time.
- Self-supervised and contrastive learning: Like “spot the difference” exercises that teach the model to prefer correct reasoning over faulty reasoning.
- Automated verifiers and critics: Like a checker that reviews the model’s steps and flags mistakes, or a proof assistant that confirms logic.
The paper also mentions a recent model, DeepSeek-R1, as an example that uses reinforcement learning to strengthen multi-step reasoning in math and coding.
What did the survey find, and why does it matter?
Here are the main takeaways, stated simply:
- Better prompts lead to better thinking: Asking the model to show steps (CoT), try multiple approaches (Self-Consistency), or explore branches (ToT) often boosts accuracy on math and logic.
- New model designs help: Looking up facts (RAG), combining pattern learning with strict logic (neuro-symbolic), and using external tools reduce mistakes and “hallucinations.”
- Training matters a lot: Practice on reasoning-focused datasets, feedback from humans, and self-checking methods all make the model more reliable.
- Testing is improving: Researchers use benchmarks (like GSM8K for grade-school math or MATH for harder problems) to check if models are genuinely reasoning, not just guessing.
- Challenges remain: Models can still make things up, struggle with long multi-step problems, get confused by tricky wording, and have trouble moving their skills from one domain (say, law) to another (say, science).
Why it matters: If AI can reason more clearly, it becomes safer and more useful in real-world areas like education, research, law, and medicine—places where being right and explaining why really count.
How do researchers test reasoning?
They use standardized “quizzes” and scoreboards:
- Math and logic tests (e.g., GSM8K, MATH, LogiQA)
- Multi-step reading and question answering (e.g., HotpotQA, ARC)
- Coding tasks (e.g., HumanEval) They measure things like accuracy, whether the steps make sense, and if the model gives the same correct answer across multiple tries.
What are the big challenges?
- Hallucinations: The model may write confident but untrue steps or facts.
- Generalization: Doing well in one area (like math) doesn’t always transfer to others (like law).
- Adversarial prompts: Small changes in a question can throw the model off.
- Logic vs. patterns: Pure pattern learning struggles with strict logical proofs; combining symbolic logic and neural nets is promising but hard.
- Explainability: We want models that not only get the right answer but can explain their reasoning faithfully.
What could this research change in the future?
- More trustworthy AI assistants: Better reasoning means fewer made-up facts and clearer explanations.
- Stronger tools for learning and problem-solving: Students, teachers, scientists, and programmers could rely on AI for step-by-step help.
- Safer use in serious fields: If models can reason accurately and show their work, they can be used more in medicine, law, and engineering.
- New hybrid AI designs: Mixing memory, tools, logic, and learning could produce AI that thinks more like careful humans—checking facts, planning steps, and verifying results before answering.
In short, this survey maps out how to help AI not just talk well, but think better—so it can solve harder problems more reliably and explain how it got there.
Collections
Sign up for free to add this paper to one or more collections.