- The paper introduces a novel method that repurposes the masked language modeling head for generative classification, enabling zero-shot learning without extensive prompt engineering.
- It shows that ModernBERT-Large-Instruct achieves 93% of Llama3-1B performance with 60% fewer parameters on the MMLU benchmark, emphasizing efficiency.
- The approach facilitates fine-tuning across varied tasks such as textual entailment and sentiment analysis, challenging traditional classification methods.
It's All in The [MASK]: Simple Instruction-Tuning Enables BERT-like Masked LLMs As Generative Classifiers
Introduction
Transformer-based encoder-only models have been central to NLP since BERT's release in 2018. Despite the impressive performance of generative LLMs, encoder-only models like BERT are favored for their efficiency in real-world applications. Traditional classification with these models uses task-specific heads, which limit their capabilities in zero-shot and few-shot learning. This paper addresses these limitations by introducing ModernBERT-Large-Instruct, leveraging its masked language modeling (MLM) head for generative classification, thus enabling robust performance without extensive prompt engineering or architectural changes.
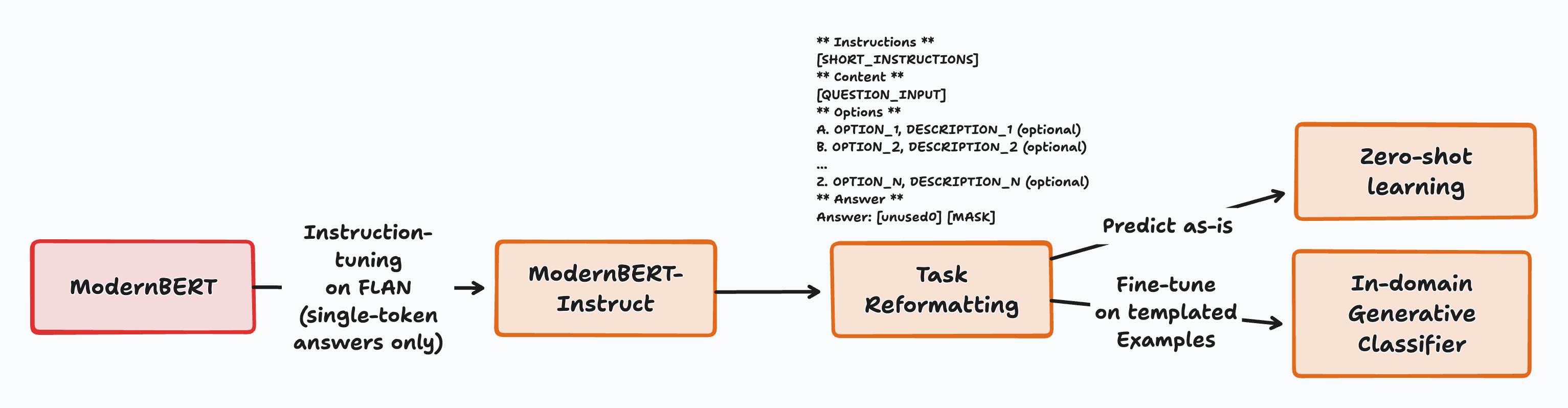
Figure 1: High level overview of the process.
Zero-Shot Capabilities
ModernBERT-Large-Instruct exhibits strong zero-shot performance, significantly outperforming similarly sized models like SmolLM2 on the MMLU benchmark, achieving 93% of Llama3-1B’s performance with 60% fewer parameters. This suggests that encoder models can excel in tasks demanding knowledge and reasoning if properly tuned. The model's generative approach matches or surpasses traditional methods, especially when trained on diverse, large-scale data.
Generative Classification Approach
The key novelty lies in using the MLM head for classification tasks. Traditionally an encoder model pools representations into a single vector for label assignment; instead, this work repurposes the MLM head generatively. Such an approach transforms zero-shot classification into Cloze-style questions, allowing the model to efficiently generate labels as single tokens. This method showcases substantial gains in generative capabilities, verified by zero-shot evaluation on various benchmarks.
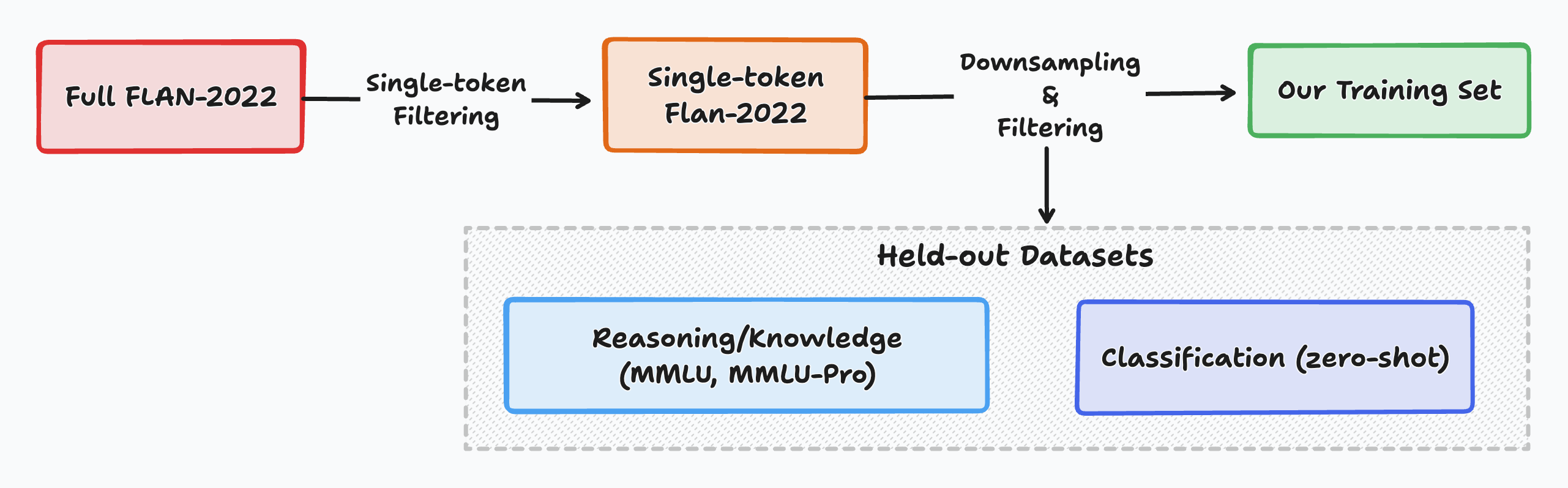
Figure 2: High level overview of our data processing pipeline.
Impact of Model Architecture
The study emphasizes that ModernBERT's superiority is contingent upon its architecture and training on diverse data. Older models like RoBERTa and GTE-en-MLM-Large showed reduced performance with similar settings. Thus, effectiveness seems to be an emergent property of training with modern architectures and significant data diversity, hinting at new directions in designing smaller yet powerful models.
Fine-Tuning and Versatility
Further exploration confirms that generative classification with the MLM head offers advantages in fine-tuned settings across diverse domains such as textual entailment and sentiment analysis. The generative head not only maintains efficient zero-shot performance but also, when fine-tuned, competes closely with dedicated classification heads.
Conclusion
This paper establishes a significant step in generative classification with encoder-only models, particularly using the MLM head without complex modifications. The approach challenges traditional classification paradigms, suggesting generative methods could be better suited for future implementations, enhancing both zero-shot and domain-specific tasks. While yielding promising results, it underscores the need for further research into instruction tuning and model design that could potentially leverage masked LLMs more effectively.
The implications for NLP are substantial, promoting exploration into more efficient model designs and training datasets, aiming to further blur the lines between encoder and decoder capabilities while maintaining computational efficiency. Future work may involve refining instruction sets, improving few-shot learning, and exploring in-context learning paradigms with similar architectures.