- The paper introduces UltraIF, a two-phase method decomposing and synthesizing instructions for enhanced LLM instruction following.
- It employs evaluation questions and Iterative Direct Preference Optimization to verify response correctness and improve alignment.
- Experiments using LLaMA-3.1-8B show significant performance gains on benchmarks like IFEval and MultiIF, demonstrating robust scalability.
Overview of "UltraIF: Advancing Instruction Following from the Wild"
The paper "UltraIF: Advancing Instruction Following from the Wild" proposes UltraIF, a method for enhancing the instruction-following capabilities of LLMs using open-source data. This approach addresses the disparity between community-developed models and those trained by industry leaders by providing a scalable technique for aligning models with complex user instructions.
UltraIF Framework
UltraIF operates through a two-phase process. Initially, it decomposes user instructions into simpler prompts, each with constraints and evaluation questions. The UltraComposer model then synthesizes these into complex instructions while ensuring response correctness through these evaluation questions.
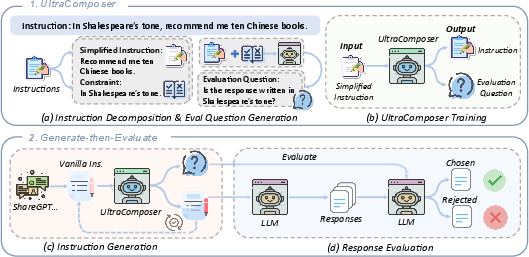
Figure 1: The framework of UltraIF. Specifically, UltraIF begins by training the UltraComposer, which decomposes real-world user instructions and evaluation questions.
Instruction Decomposition and UltraComposer
- Decomposition: The process starts with breaking down complex prompts into basic queries and constraints. This provides a foundation to model real-world instruction distribution effectively.
- Evaluation Question Generation: For each constraint, a corresponding evaluation question is generated. This enables the verification of responses for correctness.
- UltraComposer Training: This model constructs complex instructions with embedded evaluation questions, enhancing synthesis of diverse, complex queries.
Generate-then-Evaluate Process
UltraIF utilizes a Generate-then-Evaluate methodology, supporting both Supervised Fine-tuning (SFT) and Preference Learning. This involves collecting user instructions, refining them using the UltraComposer, and employing evaluation questions for sampling quality responses.
Experimental Evaluation
The effectiveness of UltraIF was validated across several instruction-following benchmarks, including IFEval and Multi-IF. The evaluations were conducted using the LLaMA-3.1-8B model, demonstrating significant improvements in alignment and instruction-following abilities.
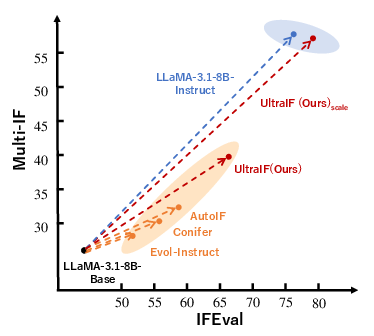
Figure 2: Instruction-following performance comparison of UltraIF against baselines on IFEval and MultiIF.
Main Results
- Performance: UltraIF significantly outperformed previous methods in various settings, indicating its robustness in handling complex instructions.
- Iterative DPO: The Iterative Direct Preference Optimization process enhanced alignment, particularly benefiting complex instruction tasks.
- Scalability: UltraIF exhibited impressive scalability with larger datasets, achieving strong results compared to the LLaMA-3.1-8B-Instruct model.
Analysis of UltraIF
UltraIF's ability to adjust instructions iteratively and its efficient use of evaluation questions mark significant improvements over traditional methods. The iterative DPO process and the incorporation of multi-turn data during training further optimized model performance.
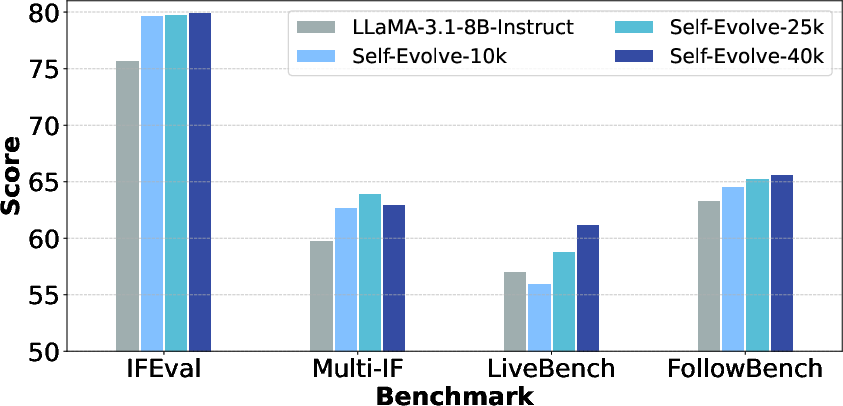
Figure 3: The performance of exploring the potentiality of UltraIF on self-alignment.
Conclusion
UltraIF presents a scalable method for augmenting instruction-following capabilities of LLMs by bridging the gap with industry models. Through its comprehensive framework and efficient processes, UltraIF achieves enhanced alignment, scalability, and generality, offering a notable contribution to the development and democratization of advanced LLMs.