Stochastic Forward-Backward Deconvolution: Training Diffusion Models with Finite Noisy Datasets
Published 8 Feb 2025 in cs.LG | (2502.05446v2)
Abstract: Recent diffusion-based generative models achieve remarkable results by training on massive datasets, yet this practice raises concerns about memorization and copyright infringement. A proposed remedy is to train exclusively on noisy data with potential copyright issues, ensuring the model never observes original content. However, through the lens of deconvolution theory, we show that although it is theoretically feasible to learn the data distribution from noisy samples, the practical challenge of collecting sufficient samples makes successful learning nearly unattainable. To overcome this limitation, we propose to pretrain the model with a small fraction of clean data to guide the deconvolution process. Combined with our Stochastic Forward--Backward Deconvolution (SFBD) method, we attain FID 6.31 on CIFAR-10 with just 4% clean images (and 3.58 with 10%). We also provide theoretical guarantees that SFBD learns the true data distribution. These results underscore the value of limited clean pretraining, or pretraining on similar datasets. Empirical studies further validate and enrich our findings.
The paper presents SFBD, which combines limited clean-data pretraining with iterative forward-backward deconvolution to overcome training challenges on noisy datasets.
It establishes theoretical limits by showing that deconvolution from Gaussian noise is ill-conditioned, degrading convergence rates feasible in clean-data scenarios.
Empirical results on CIFAR-10 and CelebA demonstrate that SFBD outperforms prior methods, ensuring robust performance and enhanced privacy guarantees.
Stochastic Forward-Backward Deconvolution: Training Diffusion Models with Finite Noisy Datasets
Motivation and Theoretical Foundations
This paper addresses a central challenge in diffusion modeling: training high-fidelity generative models when only finite, strongly corrupted datasets are available, as motivated by requirements such as copyright compliance and privacy. Standard diffusion models, although powerful, are known to memorize training data and can inadvertently reproduce copyrighted content. To mitigate privacy and copyright risks, several recent works advocate training exclusively on irreversibly corrupted data, e.g., through additive Gaussian noise, ensuring models never access original, sensitive samples.
The authors present a rigorous deconvolution-theoretic analysis of this ambient noise training regime. They establish that, while it is theoretically possible to recover the original data distribution from noisy samples (by virtue of the convolution relationship between clean and noisy data distributions), in practice, deconvolution from Gaussian noise is highly ill-conditioned, requiring sample sizes exponential in the target density's resolution for accurate recovery. Specifically, they prove optimal convergence rates for mean integrated squared error (MISE) in density estimation degrade from O(n−4/5) in the clean case to O((logn)−2) under moderate Gaussian noise. Thus, training high-quality diffusion models directly from only noisy samples is fundamentally infeasible in practical regimes.
SFBD Algorithm
To resolve the denoising bottleneck, the authors propose Stochastic Forward-Backward Deconvolution (SFBD), which exploits a small fraction of clean, copyright-free data for initialization and leverages noisy data for the bulk of model training. The process consists of two main operational phases:
Clean Data Pretraining: The model is first pretrained via standard EDM [KarrasAAL22] loss on a small set of clean samples to anchor the parameterization near the support of the target distribution.
Iterative Forward-Backward Optimization:
The main training alternates the following:
- Backward Sampling: Sample noisy data are stochastically denoised via the backward SDE (using the current denoiser as the score function estimator), generating a pseudo-clean dataset.
- Denoiser Update: The denoiser is finetuned via score-matching/denoising loss on the generated pseudo-clean data, iteratively improving the score estimator.
This forward-backward process is guaranteed (in the idealized infinite-data limit) to converge toward the true data distribution at rate O(1/K) (in characteristic function distance), with improvement directly dependent on the quality of pretraining.
Empirical Evaluation
The paper presents a comprehensive empirical analysis on CIFAR-10 and CelebA, evaluating SFBD in scenarios with as little as 4% clean data and substantial noise corruption on the remaining samples. FID is used as the primary metric.
Key findings:
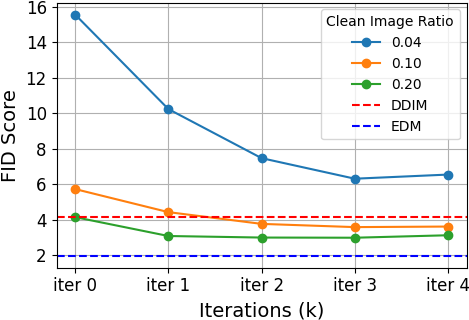
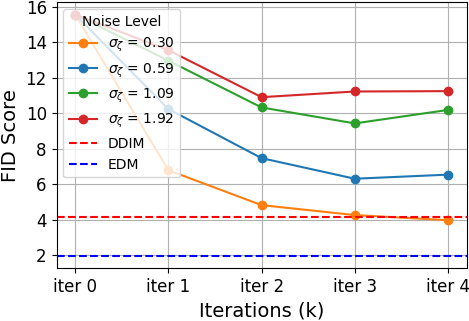
With 4% clean data and heavy corruption (σζ=0.59), SFBD achieves FID 6.31 on CIFAR-10, outperforming all prior approaches trained under similar noise, and even surpassing DDIM [SongME2021] models trained on 10% clean data.
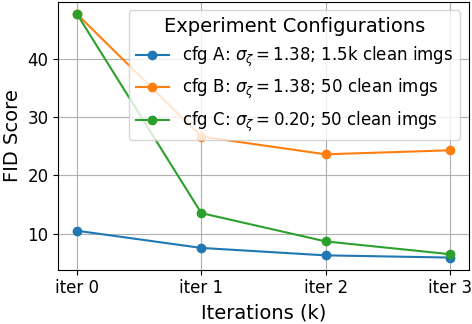
On CelebA, SFBD achieves FID 6.49 with strong sample diversity even when nearly all information is destroyed in the training set (high noise regime), provided a modest increase in clean data (1.5k samples, still <1% of the dataset).
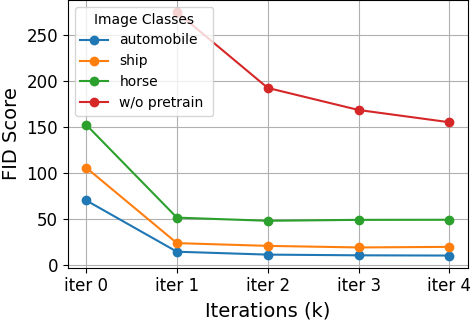
Performance is robust to pretraining on similar but not identical clean data, as shown by cross-class experiments.
SFBD decisively outperforms classical denoisers (e.g., Restormer [ZamirAKHKY2022]) as a pseudo-clean data generator; standard denoising yields much higher FID, indicating that task-adapted model-based denoising is critical.
As the clean image ratio increases, gains become marginal past a low threshold, supporting the theoretical claim that the main utility of clean data is to anchor the initial score function.
Increasing noise level degrades performance, consistent with the theoretical deconvolution lower bound.
Figure 1: SFBD performance on CIFAR-10 as a function of clean image ratio, noise level, and the distributional similarity of pretraining data to the noisy data.
Figure 2: Visualization of noisy images generated with increasing σζ, illustrating loss of recoverable information.
Figure 3: SFBD's denoising process on CelebA under various noise/pretraining configurations; displays FID improvements and denoised samples over optimization.
Comparison with Consistency-Based Deconvolution
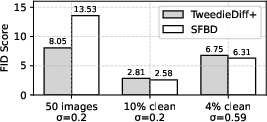
The work benchmarks against contemporaneous approaches, particularly those using consistency constraints (TweedieDiff, TweedieDiff+), ambient score-matching, and SURE-based training. SFBD outperforms these methods under equal clean data availability and noise regimes. Notably:
Consistency losses, while theoretically compelling, are ineffective when training from scratch and fail to close the optimization gap in the high-noise regime, with training rapidly degenerating post-pretraining.
TweedieDiff+ improves on the original TweedieDiff by simplifying the loss, but still underperforms SFBD once a moderate amount of pretraining data is available.
SFBD's key advantage is that it sidesteps the necessity of accurate score function estimation below the corruption threshold, instead leveraging the generative model's own iterative improvement over pseudo-inverse samples.
Figure 4: Comparative FID performance of TweedieDiff+ and SFBD on CIFAR-10 as a function of clean data ratio.
Theoretical Guarantees and Algorithmic Properties
A primary theoretical contribution is the convergence analysis of SFBD in characteristic function space, effectively quantifying how the quality of pretraining and the number of forward-backward cycles determine approximation to the true data distribution. The guarantee is robust to arbitrary initial parameterizations as long as some nontrivial pretraining is performed, and provides a monotonic improvement with iteration.
Another insight is the connection between score-based denoising and the enforcement of consistency constraints: the denoiser loss at t=0 is equivalent to the r=0 consistency loss, and the iterative process can be seen as enforcing global consistency between all time pairs via self-consistency of the generated pseudo-clean set.
Privacy, Memorization, and Security Considerations
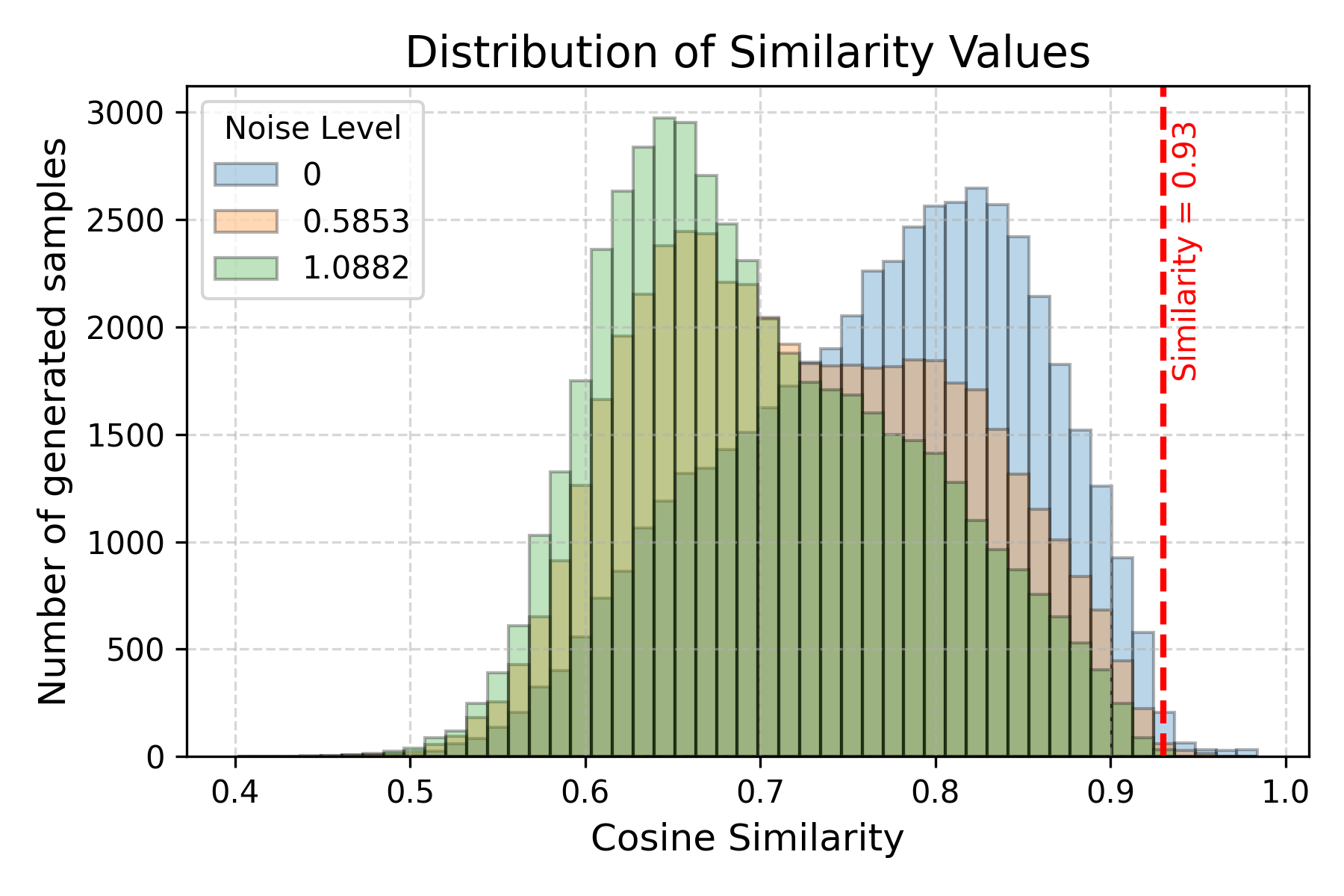
SFBD, by design, never exposes the model to more than one irreversibly noised version of any sensitive input. Extensive empirical analysis with DINOv2-based nearest neighbor searches on generated samples and training data demonstrates no measurable memorization of privileged or copyrighted images. Increasing noise levels further reduce leakage risk, at the costing of reconstruction quality, thus providing a natural privacy-utility tradeoff.
Figure 5: Distribution of maximum DINOv2 similarity scores between generated samples and sensitive training images under varying noise regimes—showing minimal memorization.
Practical Implications and Future Directions
The introduction of SFBD provides concrete guidelines for deploying diffusion models in privacy- or copyright-sensitive arenas:
A modest amount of clean, copyright-free data suffices for practical training; it is not necessary that this data be identical to the target distribution, merely sharing some support structure.
Large-scale training on web-scraped or user-contributed datasets can be made privacy compliant by pre-corrupting all but the small clean subset, with minor cost in downstream sample quality.
Models can be safely released or shared, supported by empirical and theoretical privacy guarantees.
The work encourages further research into memory-efficient pseudo-inverse algorithms, noise-aware score estimation, and improved backward SDE solvers as avenues for relaxing clean data requirements further.
Conclusion
"Stochastic Forward-Backward Deconvolution: Training Diffusion Models with Finite Noisy Datasets" establishes the statistical and algorithmic limits of distribution learning from finite, irreversibly corrupted data. It demonstrates, both theoretically and empirically, that the deconvolution bottleneck can be overcome by leveraging even minimal clean pretraining, and introduces SFBD as a stable, superior solution to practical, copyright-sensitive generative modeling with rigorous privacy guarantees. Its empirical results set a new benchmark for training diffusion models under severe data corruption constraints, and its analysis offers valuable insights for the broader generative modeling and responsible AI community.