- The paper introduces MLDR-KD, which decouples class-wise and sample-wise relations to retain dark knowledge and bolster classification confidence.
- It employs DFRA and MSDF modules to align both logits and feature maps, enabling effective knowledge transfer across heterogeneous architectures.
- Experiments on CIFAR-100 and Tiny-ImageNet demonstrate up to 4.86% performance improvement on diverse model types.
Multi-Level Decoupled Relational Distillation for Heterogeneous Architectures
The paper "Multi-Level Decoupled Relational Distillation for Heterogeneous Architectures" (2502.06189) addresses the challenge of effectively transferring knowledge from teachers to students with differing architectures in the context of knowledge distillation (KD). The proposed Multi-Level Decoupled Relational Knowledge Distillation (MLDR-KD) framework introduces novel techniques for balancing dark knowledge and the confidence of correct categories across heterogeneous architectures.
Introduction to Heterogeneous Knowledge Distillation
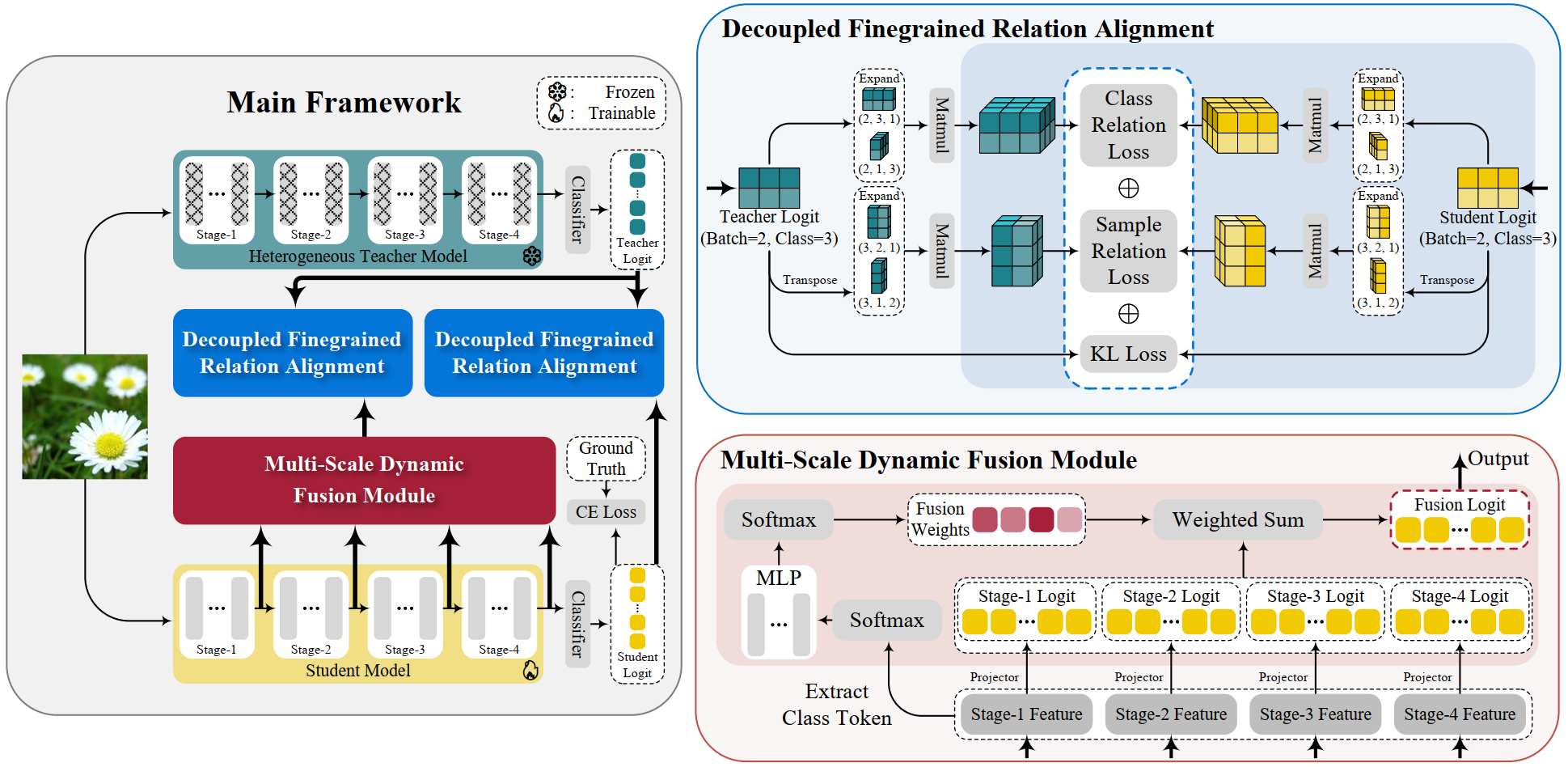
Traditional knowledge distillation focuses on homogeneous architectures, where both teacher and student models have similar structures. This paper expands on this by exploring KD across heterogeneous architectures. It proposes multi-level alignment between teacher and student models through Decoupled Finegrained Relation Alignment (DFRA) and Multi-Scale Dynamic Fusion (MSDF) modules.
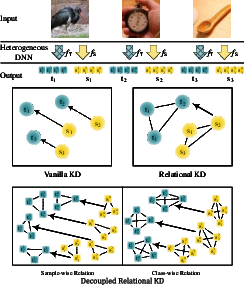
Figure 1: Conceptual comparisons of different knowledge distillation methods.
Many traditional KD methods fail with heterogeneous architectures due to differences in model structures and the potential loss of vital information termed "dark knowledge." The paper identifies limitations of previous methods that either fail to retain dark knowledge or reduce confidence in the correct classification category, affecting the student model's performance.
MLDR-KD Framework
The MLDR-KD framework consists of two key components designed to operate at both logit and feature levels: DFRA and MSDF.
Decoupled Finegrained Relation Alignment (DFRA)
DFRA tackles the key challenge of aligning relationships within the student and teacher logits. It decouples these relationships into Class-Wise Relation and Sample-Wise Relation for improved alignment.
- Class-Wise Relation Decoupling: It compares similarities across different categories, helping the student capture nuanced inter-category knowledge from the teacher.
- Sample-Wise Relation Decoupling: It focuses on intra-category information, allowing the student to infer subtle differences among samples of the same category.
These decoupled relationships are aligned via Kullback-Leibler divergence, enhancing both the confidence in correct classifications and the retention of dark knowledge.
Multi-Scale Dynamic Fusion (MSDF)
MSDF further refines the student's understanding by dynamically fusing feature maps across different stages of the student model. This process involves:
Experimental Results
Extensive experiments on CIFAR-100 and Tiny-ImageNet datasets demonstrated the efficacy of MLDR-KD, with enhancements across CNNs, Transformers, MLPs, and Mambas architectures. Key findings include:
- On CIFAR-100, MLDR-KD outperformed baseline methods, with improvements up to 4.86% on Transformers.
- On Tiny-ImageNet, significant accuracy improvements were observed, especially in larger student models, with increases up to 2.78%.
The ablation studies confirmed the critical role of DFRA and MSDF components in enhancing performance metrics. The method also demonstrated robustness in transferring knowledge from heterogeneous architectures, exhibiting improved focus on target information in feature visualizations.

Figure 3: Comparisons of feature visualizations between OFA-KD and our MLDR-KD.
Conclusion
The MLDR-KD approach introduces significant advancements in the field of heterogeneous distillation by proposing fine-grained relation alignments and dynamic fusion techniques that bolster both dark knowledge transfer and classification confidence. The framework demonstrates generality and robustness across various architectures and datasets, marking an essential step towards generalized application of knowledge distillation across diverse model types.
Future research directions include optimizing feature-level knowledge transfer for further improving the distillation process across heterogeneous architectures.