Connector-S: A Survey of Connectors in Multi-modal Large Language Models
Abstract: With the rapid advancements in multi-modal LLMs (MLLMs), connectors play a pivotal role in bridging diverse modalities and enhancing model performance. However, the design and evolution of connectors have not been comprehensively analyzed, leaving gaps in understanding how these components function and hindering the development of more powerful connectors. In this survey, we systematically review the current progress of connectors in MLLMs and present a structured taxonomy that categorizes connectors into atomic operations (mapping, compression, mixture of experts) and holistic designs (multi-layer, multi-encoder, multi-modal scenarios), highlighting their technical contributions and advancements. Furthermore, we discuss several promising research frontiers and challenges, including high-resolution input, dynamic compression, guide information selection, combination strategy, and interpretability. This survey is intended to serve as a foundational reference and a clear roadmap for researchers, providing valuable insights into the design and optimization of next-generation connectors to enhance the performance and adaptability of MLLMs.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper is a “survey,” which means it reviews and explains what other researchers have already done. Its topic is connectors in multi‑modal LLMs (MLLMs). Multi‑modal just means the model can handle different kinds of data—like pictures, sound, video, or 3D objects—together with text. A connector is the small but crucial part that helps these different kinds of data “talk” to the LLM.
Think of the whole system like this:
- A modality encoder is like a camera or microphone that turns raw images or audio into numbers a computer can work with.
- The connector is like an adapter or translator that reshapes those numbers into the kind of “word pieces” (tokens) the LLM understands.
- The LLM is the “language brain” that reads those tokens and produces answers.
- Sometimes there’s a generator for making outputs beyond text (like images or audio).
The paper organizes and explains different kinds of connectors, how they’ve evolved, and where the field is heading.
Main questions the paper asks
In simple terms, the authors ask:
- How do different connectors work to bridge images, audio, and other data with a LLM?
- What are the main “building blocks” of connectors, and how can we group them?
- How do connectors handle more complex situations, like using features from many layers, many encoders, or many data types at once?
- What challenges are still open, and what should researchers improve next?
How the authors studied it
This is not an experiment paper; it’s a map of the field. The authors:
- Read many recent MLLM papers and pulled out the connector designs.
- Built a taxonomy (a clean, organized “family tree”) to classify connectors in two big ways:
- Atomic operations (basic building blocks)
- Holistic designs (how to combine and use information in complex setups)
They explain each category in everyday terms and show how different designs try to solve practical problems, like keeping inputs short but informative, or picking the right kind of processing for different tasks.
To make ideas concrete, here are the main terms explained with simple analogies:
- Modality: a type of input (picture, sound, video). Like different “languages” (English, Music, Images).
- Token: a small piece of data the LLM reads (similar to a word piece).
- Mapping: translating data into the same format as text tokens.
- Compression: summarizing data so it’s shorter but still useful (like packing a suitcase smartly).
- Mixture of Experts (MoE): a panel of specialists (experts) and a “router” that picks which specialist to ask for each piece of input.
- Multi‑layer: using features from different depths of a vision model, from edges and textures (shallow) to objects and scenes (deep).
- Multi‑encoder: using multiple “cameras”/encoders trained differently to get complementary views of the same input.
- Fusion: ways to blend information (stacking, averaging, or “paying attention” to the most relevant parts).
What the paper found (the taxonomy) and why it matters
The authors propose a clear, two‑part taxonomy:
A. Atomic connector operations (the basic building blocks)
These are small, simple pieces you can combine:
- Mapping: turns non‑text features into text‑like tokens.
- Linear: a simple, straight-line translation. Fast and light, but limited.
- MLP (multi‑layer perceptron): a slightly smarter translator that can handle curves, not just straight lines.
- Compression: keeps important info and removes redundancy so the LLM doesn’t get overwhelmed.
- Spatial relation methods: summarize nearby regions (like pooling or small CNNs). Fast and simple.
- Semantic perception methods: pick the most meaningful parts using attention‑like modules (e.g., Q-Former or Resampler). Smarter but heavier.
- Mixture of Experts (MoE): a flexible system with many specialist modules and a router that chooses which specialists to use.
- Vanilla MoE: the router picks experts by looking at each token.
- X-guided MoE: the router also looks at extra guidance (which modality it is, the text instruction, or the specific task).
- Variant MoE: experts can be different types (e.g., one is a simple mapper, another is a smart resampler), and the system switches between them.
Why this matters:
- Mapping keeps it simple and fast.
- Compression keeps inputs short while preserving what matters.
- MoE adapts to different tasks or inputs by “asking the right expert.”
B. Holistic connector designs (for complex, real‑world setups)
These handle richer information and harder scenarios:
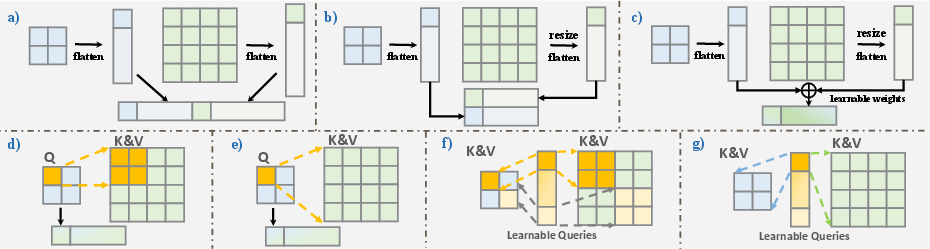
- Multi‑layer scenario: combine features from different layers of a vision model (details + concepts). Fusion can be:
- Stacking tokens, averaging/weighting channels, or using attention to pick what’s relevant.
- Multi‑encoder scenario: combine features from different encoders (e.g., one great at text‑image matching, another great at object details).
- Fusion again varies: stacking, averaging with learned weights, or attention with learnable query tokens.
- Multi‑modal scenario: handle images, audio, video, etc., together.
- Early fusion: use a powerful “unified encoder” first, then a simple connector.
- Intermediate fusion: each modality has its own encoder; the connector fuses them.
- Late fusion: each modality has its own connector; then outputs are combined.
Why this matters:
- Real tasks need both fine details and big-picture meaning.
- Combining multiple views (encoders) often improves understanding.
- Handling many modalities safely (without them interfering) is essential for general‑purpose AI.
Future directions and key challenges
The paper highlights five big areas to improve:
- High‑resolution input: How to keep fine details without breaking spatial relationships.
- Dynamic compression: Adjust the summary length based on how complex the input is (not one-size-fits-all).
- Guide information selection: Use helpful hints (like the user’s instruction) to focus on relevant parts.
- Combination strategy: Better ways to blend multi-layer/multi-encoder info without wasting compute.
- Interpretability: Make connectors more “explainable” so we understand what they keep or discard.
Why this is important
Connectors might look small, but they strongly affect how well an MLLM understands images, audio, and other inputs—and how fast and efficient it is. Better connectors mean:
- More accurate, detailed answers (because important info is preserved and aligned well).
- Faster models (because unnecessary tokens are filtered out).
- More flexible systems that can handle many tasks and data types.
Bottom line
This survey gives researchers a clear roadmap for building and improving connectors:
- It organizes existing designs into understandable categories (mapping, compression, MoE; plus multi-layer, multi-encoder, multi-modal).
- It explains the trade-offs between simple and advanced methods.
- It points to practical, exciting challenges for the next generation of multi‑modal AI.
For a young learner: think of the connector as the smart adapter that lets different gadgets (images, audio, video) plug into the language brain smoothly. The better the adapter, the better the whole system works.
Collections
Sign up for free to add this paper to one or more collections.