- The paper introduces ChordFormer, a novel conformer-based architecture that integrates CNNs and self-attention for improved large-vocabulary audio chord recognition.
- It employs a reweighted loss function and CRF decoding to mitigate class imbalance and produce coherent chord sequences.
- Evaluations demonstrate that ChordFormer outperforms CNN, CNN+BLSTM, and transformer models, achieving up to 6% higher class-wise accuracy on rare chord types.
Introduction
The paper "ChordFormer: A Conformer-Based Architecture for Large-Vocabulary Audio Chord Recognition" (2502.11840) introduces a novel conformer-based architecture designed to tackle large-vocabulary audio chord recognition. This task is critical for Music Information Retrieval (MIR) as it involves decoding audio into sequences of chord labels. Despite advancements in chord recognition systems for major/minor chords, recognizing chords in a large vocabulary presents challenges due to data imbalance and limited training samples for rare chord types. Previous methods combining convolutional neural networks (CNNs), bidirectional long short-term memory networks (BLSTMs), and transformers demonstrate limitations in capturing long-term dependencies necessary for complex chord structures, such as triads, bass, and sevenths.
Methodology
The ChordFormer architecture incorporates three key modules: a preprocessing module for converting audio signals into Constant-Q Transform (CQT) representations, a conformer block to process CQT features using convolutional layers and self-attention mechanisms, and a decoding model to interpret activations and generate chord sequences.
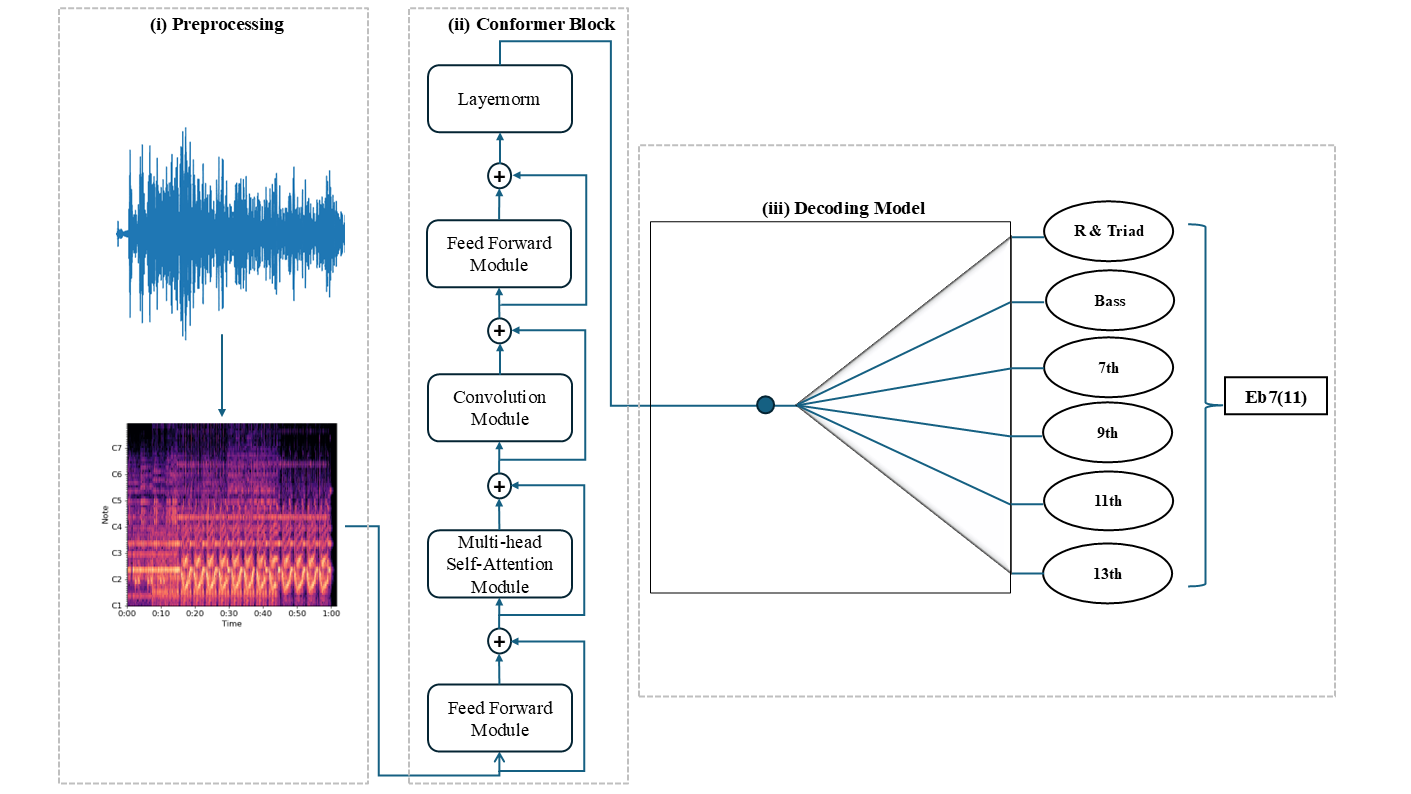
Figure 1: Overview of the ChordFormer Architecture.
The core of ChordFormer is the conformer block, which integrates CNNs and self-attention mechanisms to balance local pattern recognition and global dependency modeling. The multi-head self-attention (MHSA) module offers advantages in dynamically adjusting its focus on relevant frames, capturing long-range dependencies more effectively than traditional RNNs or CNNs. A convolution module captures local feature information, and a feedforward block enhances expressive capacity using Swish activation and residual connections for better gradient flow.
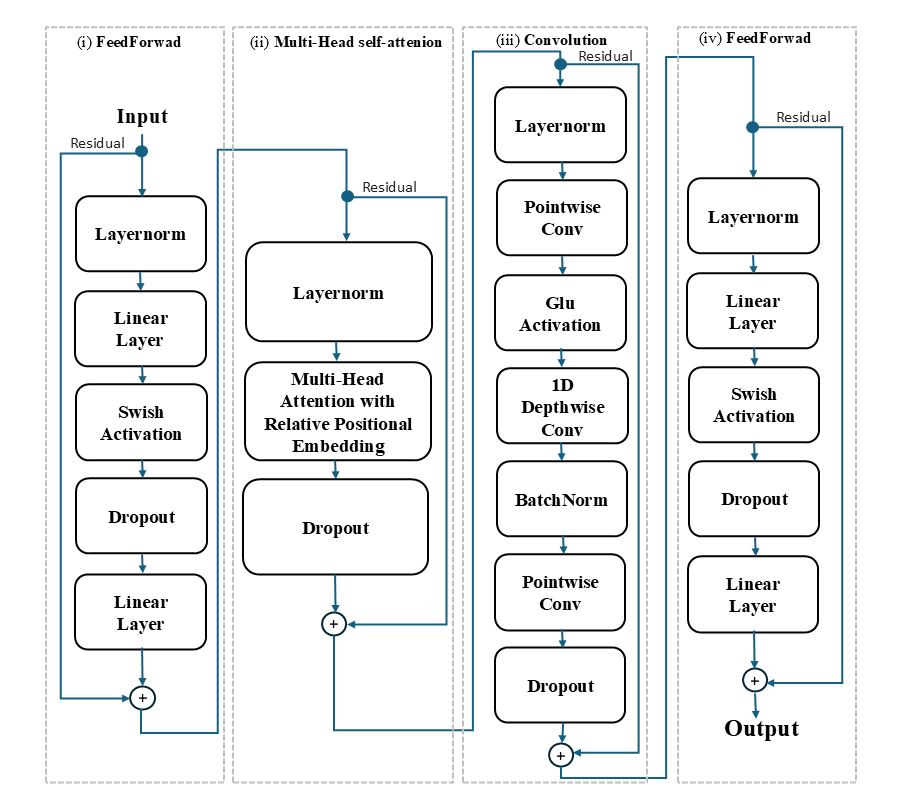
Figure 2: Architecture Overview of Key Modules in ChordFormer Model.
Loss Function and Class Imbalance
To tackle class imbalance, ChordFormer employs a reweighted loss function, assigning higher weights to underrepresented chord classes. This approach ensures balanced learning across a wide range of chords, enhancing recognition of rare chord types.
Chord Sequence Decoding
ChordFormer utilizes Conditional Random Field (CRF) decoding to produce coherent chord sequences, penalizing excessive transitions and enabling control over output chord vocabulary. This improves temporal smoothness and accuracy in predictions.
Results
Evaluation Metrics
ChordFormer was evaluated using various metrics, including Weighted Chord Symbol Recall (WCSR), frame-wise accuracy ($acc_{\text{frame}$), and class-wise accuracy ($acc_{\text{class}$). The model achieves significant improvements with a 2% increase in frame-wise accuracy and a 6% increase in class-wise accuracy on large-vocabulary datasets. Notably, ChordFormer excels in recognizing rare chord types and demonstrates superior performance on large-vocabulary tasks.
Comparisons and Class Recall
Experimental results indicate that ChordFormer outperforms baseline models, including CNN, CNN+BLSTM, and traditional transformer models across multiple metrics. Class recall evaluations reveal improved accuracy for rare chord classes under varying re-weighting strategies.
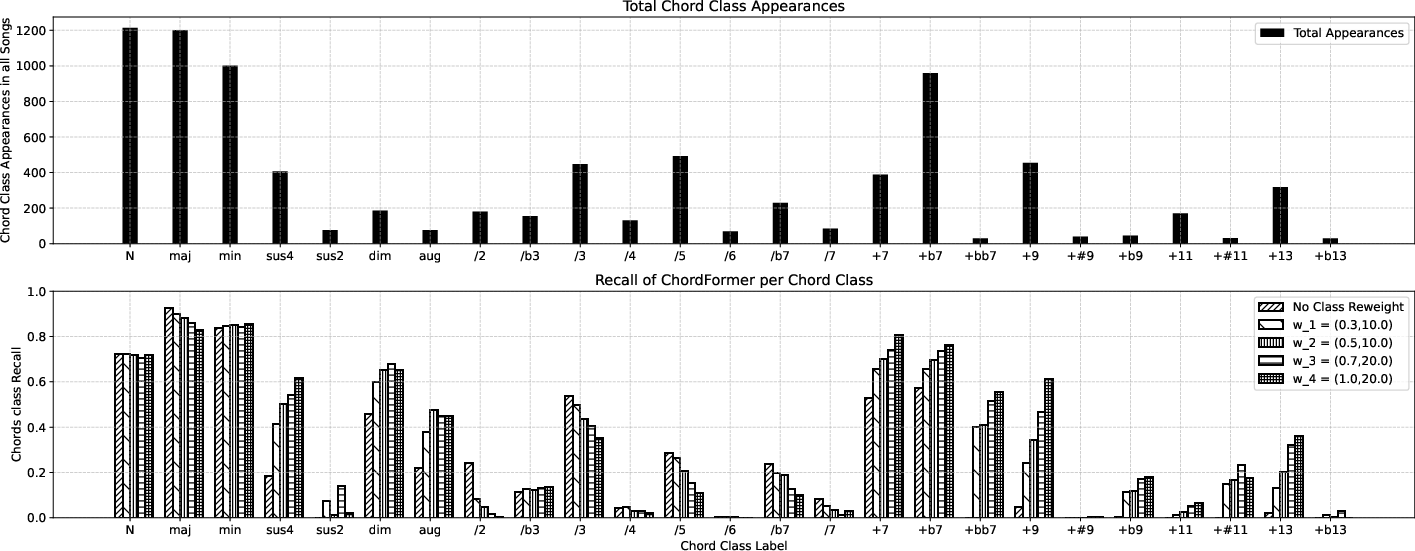
Figure 3: Top: chord class appearance in song dataset; Bottom: ChordFormer recall values for each chord class under varying re-weight factors.
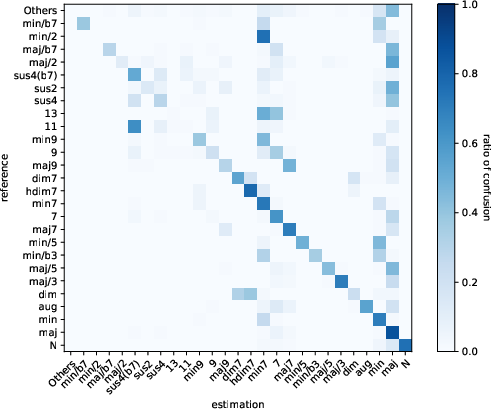
Figure 4: Confusion matrix of ChordFormer with re-weighting factors ($\gamma = 0.5, w_{\text{max}$).
Conclusion
ChordFormer marks a substantial advancement in automatic chord recognition by effectively integrating convolutional layers and self-attention mechanisms within a conformer framework. It successfully addresses large-vocabulary recognition challenges, offering enhanced performance especially for rare chord types through innovative reweighting strategies and structured chord representations. Future research directions may explore adaptive reweighting techniques and self-supervised learning to further optimize performance and expand the applicability of chord recognition systems in real-world MIR applications. Overall, ChordFormer provides a robust foundation for future developments in automatic chord recognition, highlighting its applicability in diverse musical contexts.