- The paper proposes a novel hybrid Halley-bisection algorithm that accelerates the computation of α-entmax-based adaptive sparse attention.
- It implements custom GPU-optimized Triton kernels to effectively reduce runtime and memory usage during long-context tasks.
- Experimental results show that AdaSplash outperforms existing methods like FlashAttention-2 in both speed and efficiency for transformer models.
AdaSplash: Adaptive Sparse Flash Attention
This essay provides a comprehensive and detailed exploration of the paper "AdaSplash: Adaptive Sparse Flash Attention." The paper addresses the computational inefficiencies associated with using α-entmax attention mechanisms in transformers, particularly within the context of handling long-context tasks. Adaptive sparsity offers a theoretically advantageous alternative to the ubiquitous softmax-based attention, but prior implementations failed to capitalize on its inherent sparsity to achieve runtime and memory efficiency gains. AdaSplash emerges as a solution, combining efficient GPU-optimized algorithms with sparse attention benefits.
Introduction to AdaSplash
The motivation behind AdaSplash is rooted in the desire to improve the efficiency of attention mechanisms utilized in transformers—algorithms integral to understanding context and attention within long sequences. Traditional softmax attention has a tendency to distribute attention scores across many tokens, leading to unnecessary computational burden when processing long-context tasks. Instead, adaptive sparsity, exemplified by α-entmax attention, focuses on assigning greater significance to a subset of relevant tokens while assigning zero probability to others, theoretically optimizing both memory and computational resources.
Leveraging Adaptive Sparsity
AdaSplash capitalizes on the adaptive nature of α-entmax by utilizing a novel hybrid algorithm—a Halley-bisection method—tailored to compute the transformation with significantly reduced iterations compared to traditional methods. This approach is particularly advantageous for dynamic, data-dependent sparsity scenarios, allowing AdaSplash to outperform other algorithms like FlashAttention-2 (Figure 1).
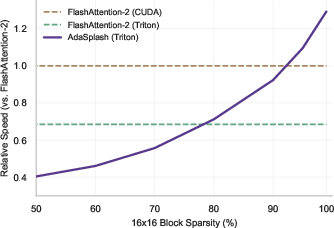
Figure 1: Runtime (Fwd+Bwd) as a function of input sparsity for non-causal attention. While the highly-optimized FlashAttention-2 maintains a constant runtime across varying levels of sparsity, AdaSplash effectively leverages sparsity to obtain speed-ups, eventually outperforming FlashAttention-2 as sparsity grows.
Implementation Details
Hybrid Halley-Bisection Algorithm
At the core of AdaSplash's methodological innovation is the hybrid Halley-bisection algorithm. This algorithm enhances convergence speed by utilizing both first and second derivatives of the transformation function. During each iteration, the algorithm adjusts the threshold τ based on the error and its derivatives, capturing the central point of distribution more rapidly than existing bisection methods.
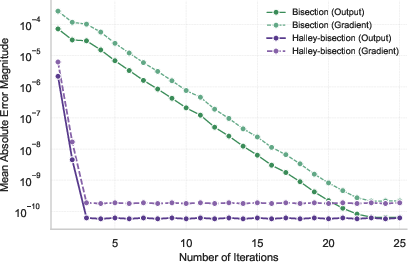
Figure 2: Comparison of mean absolute error magnitudes between Halley-bisection and Torch's bisection methods across iterations, measured against the exact solution for alpha=1.5.
Custom Triton Kernels
To harness the computational benefits of GPUs, AdaSplash employs custom Triton kernels, which are critical for handling both forward and backward passes of α-entmax efficiently. The kernels are designed to exploit the adaptive sparsity in the attention matrix, reducing GPU memory load by selectively processing non-zero blocks—a notable enhancement over traditional FlashAttention methods.
Experimental Evaluation
Through rigorous experimentation involving RoBERTa, ModernBERT, and GPT-2 models, AdaSplash demonstrates substantial improvements over prior α-entmax implementations. The model exhibits superior runtime and memory efficiency, facilitating long-context training without compromising task performance. Notably, AdaSplash surpasses GPT-2 and maintains high sparsity levels, which are effectively leveraged for computational savings (Figure 3).

Figure 3: Efficiency of algorithms for computing non-causal attention in terms of the average training step time for increasingly longer sequence lengths. We use alpha = 1.5 for alpha-entmax-based methods (Bisection and AdaSplash).
AdaSplash's task performance remains competitive across a range of applications, including language understanding and document classification. In particular, the integration of adaptive sparse attention in retrieval tasks within the BEIR benchmark highlights instances where ModernBERT equipped with AdaSplash (α=1.5) surpasses its counterparts, illustrating the practical benefits of adaptive sparseness in real-world scenarios (Figure 4).
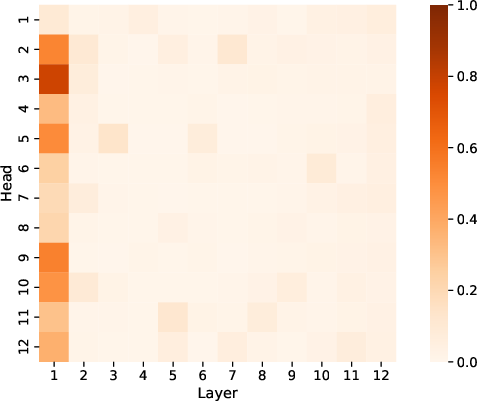
Figure 4: Ratio of non-zero attention scores for GPT-2 (α=1.5).
Conclusion
AdaSplash represents a significant step in bridging the efficiency gap in transformer models by leveraging adaptive sparse attention mechanisms. Its hybrid algorithm and custom kernel implementations collectively ensure substantial improvements in runtime and memory efficiency, making long-context tasks more feasible. The advancements introduced by AdaSplash set new precedents in attention mechanism design within transformers, with promising implications for continued exploration and development in AI. The success of AdaSplash underscores the potential for increasingly sophisticated and computationally efficient attention models in the evolving landscape of natural language processing and beyond.