- The paper introduces the Min-MaxEnt framework that uses entropy constraints to mitigate overfitting and improve data efficiency in generative AI.
- The methodology fuses theoretical insights from physics and information theory with deep learning, establishing a formal link between PCA and entropy-based approaches.
- Benchmark results show superior generative performance and controlled output, particularly in image generation and bias adjustment tasks.
A New Pathway to Generative Artificial Intelligence by Minimizing the Maximum Entropy
This paper introduces a paradigm shift in generative artificial intelligence (GenAI) by proposing a novel method based on the minimal maximum entropy (Min-MaxEnt) principle. The approach aims to address the limitations of current GenAI models, such as data inefficiency, overfitting, and difficulty in directing the generative process. Through theoretical developments and empirical results, the paper presents a robust framework that integrates theoretical rigor from physics and information theory with innovative applications in generative modeling.
Motivation and Limitations of Current GenAI
The paper begins by highlighting existing challenges within GenAI, which includes LLMs and image generators. These models, although widely successful, require enormous datasets and often suffer from overfitting. Furthermore, directing the generation process typically needs multiple manual adjustments, reducing their professional applicability. These issues underscore the need for a GenAI model that functions efficiently with limited data and offers more control over the generative outcomes.
Minimal Maximum Entropy Principle
At the core of the proposed approach is the Min-MaxEnt principle, which diverges from traditional methods by not fitting data directly. Instead, it compresses the information in the training set through a latent representation. The model assigns a probability distribution that maximizes entropy given specific constraints, ensuring unbiased inference consistent with the observations (Figure 1).
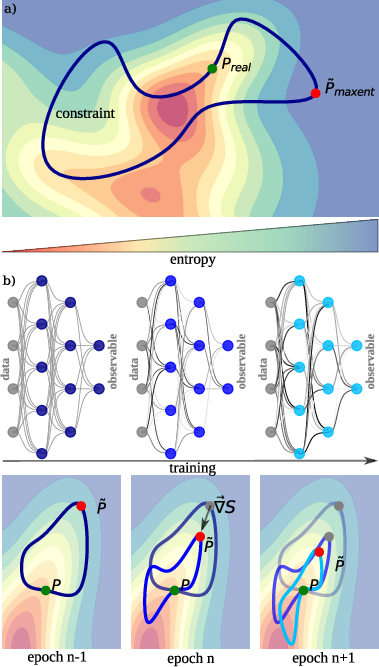
Figure 1: Illustration of the minimal maximum entropy principle with reaction coordinates, highlighting entropy landscapes and neural network-derived constraints.
The Min-MaxEnt approach inherently prevents overfitting by maintaining high entropy distributions, adjusted according to constraints defined via neural network outputs. This balance allows significant data compression while retaining the capacity to generalize from limited or undersampled datasets.
Principal Component Analysis as a Special Case
The paper draws a formal connection between PCA and Min-MaxEnt, showing that PCA emerges naturally from this principle when constraining the variance of linear combinations of variables. This result is significant because it provides analytical insight and positions PCA within a broader class of entropy-based statistical methods (Figure 2).
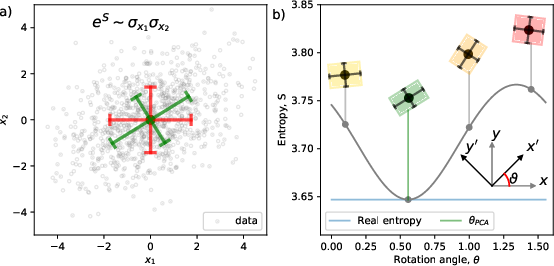
Figure 2: Demonstration of principal component analysis as a specific application of the Min-MaxEnt solution, with variance constraints in rotated bases.
Benchmarking and Comparisons
Extensive benchmarking of the Min-MaxEnt model is provided, including a comparison with variational autoencoders (VAEs) on bimodal distribution datasets. The results indicate superior performance of Min-MaxEnt in capturing distributions and preventing the common issue of VAEs producing blurry samples (Figure 3).
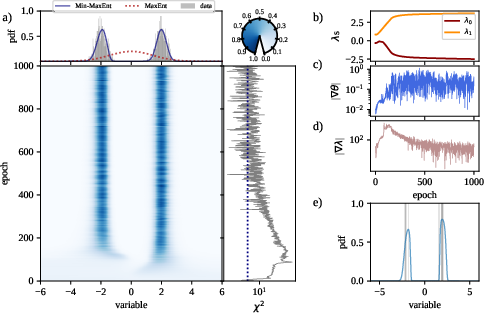
Figure 3: Inference of bimodal normal distribution using Min-MaxEnt versus VAEs, with performance metrics across training epochs.
Additionally, the method's competitive edge is pronounced when handling sparse data or data with rare but significant events. These scenarios showcase the Min-MaxEnt model's robustness against overfitting and its capability to preserve data characteristics over smaller sample sizes.
Image Generation Applications
The paper demonstrates the Min-MaxEnt model's generative capabilities using the MNIST dataset. It reveals that this approach can efficiently generate realistic images from limited data through a deep neural network architecture, further enhanced by adversarial training strategies (Figure 4).
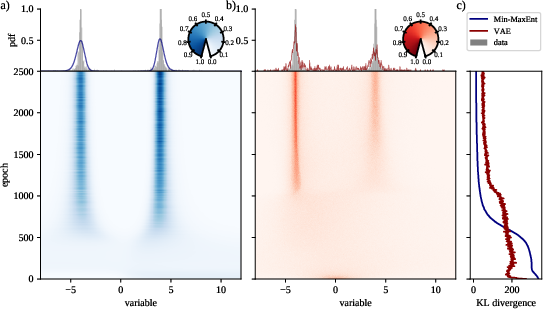
Figure 4: Example of the Min-MaxEnt generative capacity with MNIST images, illustrating the entropy reduction and generation quality improvement over epochs.
Adversarial networks are employed to refine image quality and ensure that the generated samples become indistinguishable from real ones. This is done without requiring retraining of the Min-MaxEnt model, instead leveraging biases introduced by discriminator networks.
Controlled Generative Processes
The Min-MaxEnt framework is extended to incorporate controlled generation by using learned energy landscapes. The methodology allows the incorporation of additional biases into the generative process, enabling user-directed outcomes in a systematic manner. The results highlight the ability to guide the Min-MaxEnt-generated content using pre-trained classifiers, without altering the core generative architecture (Figure 5).
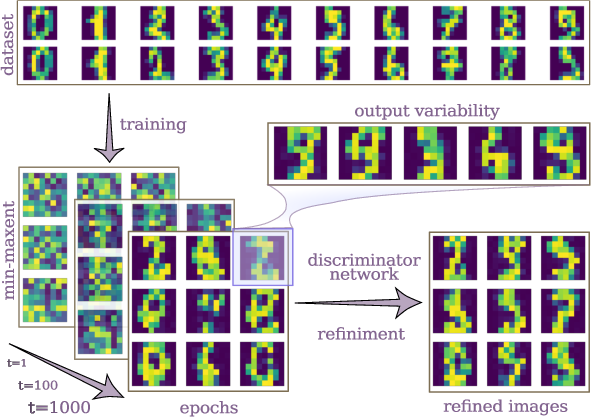
Figure 5: Visualization of biased generation in the Min-MaxEnt process using strategic energy manipulations for targeted sample outcomes.
Conclusion
The Min-MaxEnt principle provides a comprehensive framework for addressing fundamental limitations in existing GenAI models. By ensuring a high degree of data efficiency and minimizing overfitting through entropy-based techniques, this approach opens new avenues for controlled and theoretically grounded generative modeling. While practical implementations must consider ethical implications and the potential misuse of biases in generative processes, Min-MaxEnt represents a promising direction for advancing GenAI's applicability and robustness.