- The paper introduces DiffSampling, which leverages the discrete derivative of token probabilities to set a dynamic truncation boundary.
- Experimental results demonstrate that DiffSampling variants achieve superior accuracy and diversity in tasks like summarization, storytelling, and mathematical problem-solving.
- Applying temperature scaling after truncation preserves syntactic validity and mitigates the quality degradation seen with traditional high-temperature methods.
DiffSampling: A Derivative-Based Approach to Improve Diversity and Accuracy in Neural Text Generation
Introduction and Motivation
The paper "DiffSampling: Enhancing Diversity and Accuracy in Neural Text Generation" (2502.14037) introduces a novel family of decoding strategies for autoregressive neural LLMs. Standard decoding procedures such as greedy decoding, top-k, top-p (nucleus), and temperature-based sampling strike different trade-offs between output accuracy and diversity. Existing strategies are limited by their reliance on static thresholds or fixed heuristics, often resulting in syntactically inappropriate tokens or overly repetitive outputs. DiffSampling is proposed as a more principled, mathematically grounded alternative.
Methodology
DiffSampling leverages the discrete derivative (difference) of the sorted next-token probability distribution to drive token truncation decisions. The insight is that the magnitude of the largest drop between consecutive token probabilities (i.e., the minimum discrete derivative) often coincides with the boundary separating the set of contextually valid tokens (high-probability, "true" support) from the tail of the distribution induced by smoothing during model training. The paper proposes three related methods:
- DiffSampling-cut: Truncates the distribution immediately after the largest probability gap, keeping tokens to the left. This strategy aims to robustly exclude tokens assigned non-negligible mass solely due to the parametric smoothing required in maximum likelihood training.
- DiffSampling-lb: Introduces a soft lower bound on the retained probability mass. The cut point is shifted to ensure the included tokens sum to at least plb. This generalizes top-p, with derivative-aware correction.
- DiffSampling-minp: Truncates only among tokens below a dynamic threshold pmin⋅max(p), with the final boundary chosen according to the minimum discrete derivative. This corrects for min-p sampling's coarse thresholding.
Temperature scaling is applied after truncation, contrasting with traditional practice (where it precedes truncation), thus preserving the statistical properties underlying the method's justification.
Empirical Evaluation
The effectiveness of DiffSampling was rigorously evaluated across four tasks: mathematical problem-solving (GSM8K, MATH), extreme summarization (XSum), the Divergent Association Task (DAT) for creativity/divergence, and long-form story generation (WritingPrompts). Multiple LLMs—both pre-trained and RLHF-instructed—served as testbeds, and baselines included greedy, top-p, min-p, locally typical, and η-sampling.
Divergent Association Task (DAT)
DiffSampling-cut consistently generated more valid, highly divergent noun sets compared to both greedy and sampling baselines, particularly in models without instruction tuning.
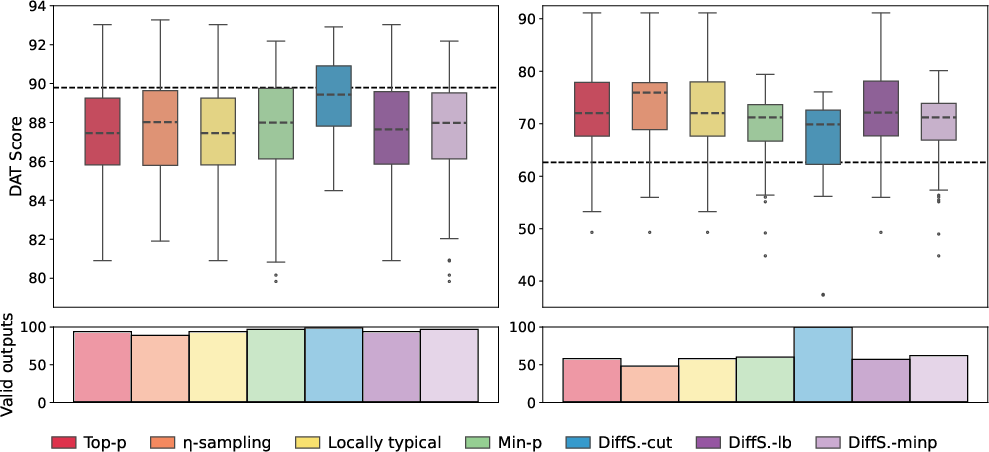
Figure 1: DAT scores for DiffSampling and baselines across instructed and pre-trained models; DiffSampling-cut yields consistently high scores and near-perfect validity.
Temperature Scaling Analysis
Contrasting with baselines, applying temperature after DiffSampling truncation maintained output quality even at high temperatures, while min-p and top-p degrade rapidly with increased temperature.
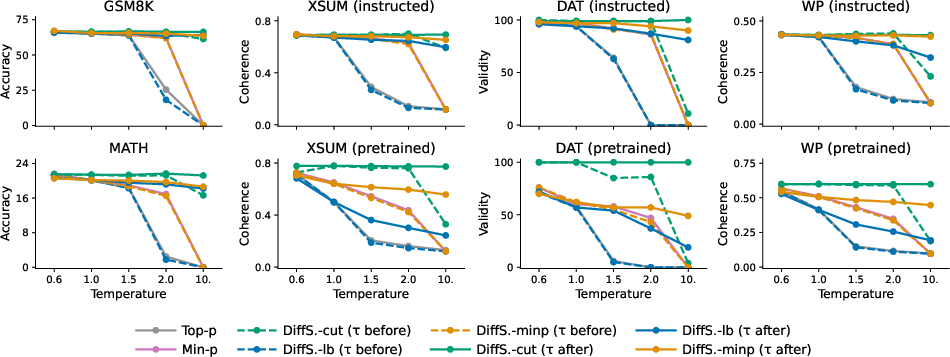
Figure 2: Output quality as a function of temperature for top-p, min-p, and DiffSampling methods; post-truncation temperature scaling in DiffSampling maintains quality, in contrast to baseline degradation.
Model and Task Diversity
DiffSampling variants produced more favorable quality-diversity tradeoffs across all major tasks. In mathematical problem solving and summarization, DiffSampling-cut matched or surpassed greedy decoding's accuracy, while DiffSampling-lb and DiffSampling-minp corrected baseline methods without additional computational overhead. Notably, in long-form story generation, DiffSampling minimized repetitive pathologies typical of greedy decoding, yielding more diverse narratives.
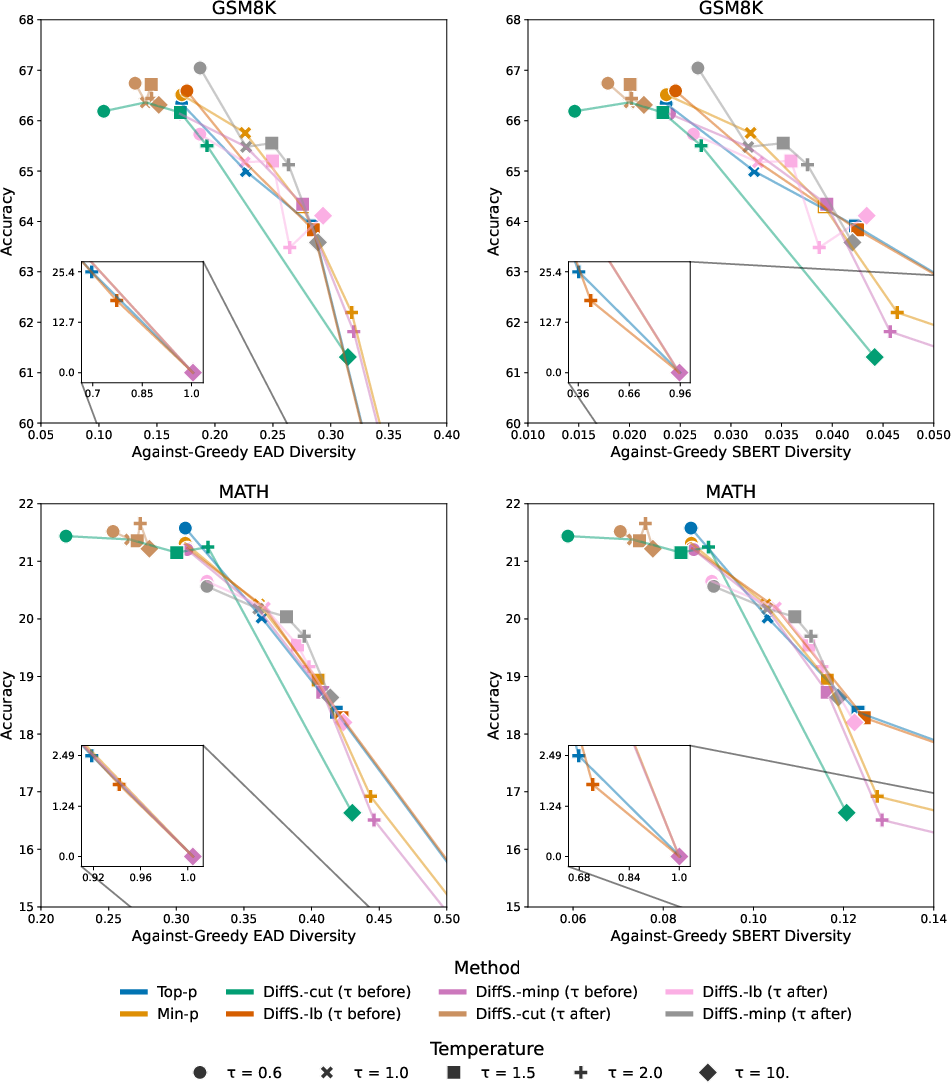
Figure 3: Quality-diversity comparisons on GSM8K and MATH: DiffSampling methods achieve superior or comparable accuracy while increasing diversity over baselines.
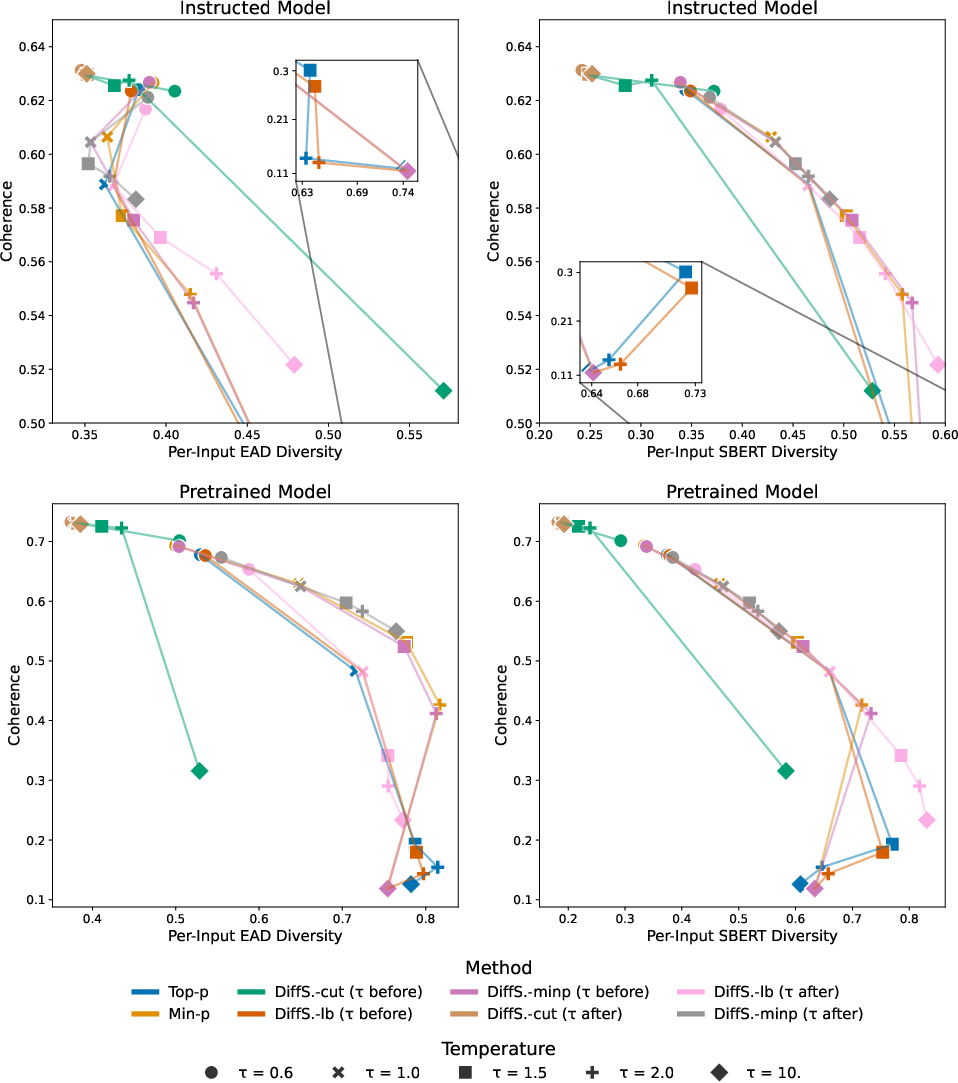
Figure 4: Quality-diversity profiles on the XSum summarization task, demonstrating robustness of DiffSampling tradeoffs compared to classical strategies.
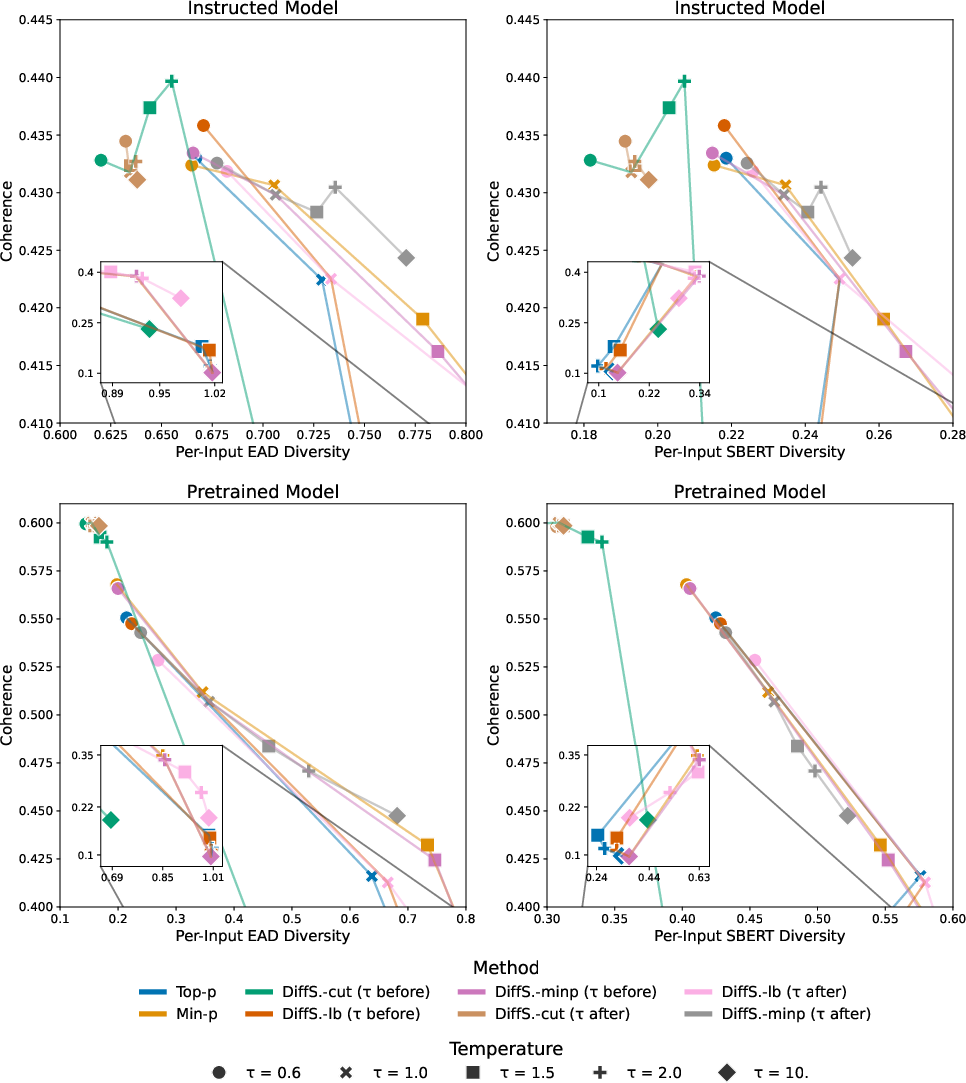
Figure 5: Story generation via WritingPrompts shows significant diversity gains for DiffSampling cut/minp/lb, particularly with post-truncation temperature adjustment.
Analysis and Interpretation
The principal claim, validated empirically and by formal analysis, is that the position of the maximum probability gap often aligns with the boundary between tokens that the model deems contextually valid and those introduced by smoothing. Unlike prior methods (e.g., top-p or locally typical sampling) that set thresholds globally or based on distributional entropy, the discrete derivative offers an instance-specific, data-driven cutoff with strong correlates to both syntactic validity and semantic appropriateness.
DiffSampling-cut consistently matches or exceeds the performance of greedy decoding on accuracy metrics, while exploring a demonstrably larger valid output space. DiffSampling-lb and DiffSampling-minp serve as drop-in improvements over nucleus and min-p sampling, respectively—empirically correcting edge-case misclassifications with essentially no added inference cost.
When DiffSampling temperature scaling is applied after truncation, the adverse effects of higher temperatures (e.g., invalid output, degraded coherence) are significantly mitigated. The method is robust to hyperparameter settings and demonstrates strong performance even on small- and medium-sized LLMs, with initial evidence extending to larger models.
Implications and Future Directions
Practically, these findings suggest that derivative-based truncation offers a theoretically grounded and computationally efficient path to improved decoding strategies for autoregressive LMs, especially where both accuracy and diversity are critical (e.g., creative applications, data augmentation, or content generation requiring minimal hallucination risk). DiffSampling is well-suited for "in the wild" use—requiring no model retraining or auxiliary classifiers, unlike selective or contrastive decoding schemes.
Theoretically, DiffSampling opens a program of investigation into distributional characteristics of neural LM outputs, with connections to entropy-based regularization and probabilistic modeling of the "true" versus "smoothing" distribution. Moreover, its empirical robustness across model types and tasks foregrounds the need for decoding methods to be adapted to model calibration and downstream application semantics.
Potential extensions include integrating DiffSampling with post-hoc reranking, context-specific adaptive thresholds, or reinforcement learning objectives. The approach could also be investigated for its applicability in code, dialogue, and multimodal generation scenarios.
Conclusion
DiffSampling introduces a principled family of decoding strategies, unifying accuracy and diversity through a derivative-based analysis of the token probability distribution. Extensive empirical evaluation demonstrates strong and consistent advantages over prevailing methods, particularly in tasks demanding both correctness and output novelty. Its computational efficiency, hyperparameter robustness, and flexibility for use with diverse foundation models make it an attractive candidate for broad adoption in neural text generation pipelines (2502.14037).

