- The paper introduces a novel six-way NLI scheme to model the full reasoning spectrum, covering both rapid (System 1) and deliberative (System 2) responses.
- It employs personality-based prompting combined with genetic algorithm optimization to achieve distributional human-likeness without fine-tuning.
- Open-source LLMs outperform larger GPT models in mimicking human response variability, challenging assumptions about size and alignment.
Personality-Based Prompting and the Full Reasoning Spectrum of LLMs
Recent advances in LLMs have fueled renewed attention to the question of whether and how such models can emulate the broad spectrum of human reasoning, including both intuitive (System 1) and deliberative (System 2) processes as described by dual-process theory. "Giving AI Personalities Leads to More Human-Like Reasoning" addresses fundamental limitations of prior AI research that focused almost exclusively on normative correctness and averaged population responses, neglecting the high inter-individual and context-dependent variability that characterizes real human reasoning. This paper introduces new benchmarks, a novel six-way granular partitioning of the Natural Language Inference (NLI) task, and an empirical framework for eliciting, modeling, and evaluating the entire distributional landscape of human and model reasoning behaviors, with a particular focus on the impact of "personality-based prompting" and genetic algorithm-driven optimization.
Modeling the Human Reasoning Spectrum
Dual-process theory distinguishes between rapid, heuristic, and intuitive System 1 processes, and slower, rule-based, and deliberative System 2 processes. The paper demonstrates that attempting to model only the modal or majority human response—ignoring the distribution of plausible "wrong" answers, how they are reached, and their relationship to psychological and contextual factors—yields an incomplete and often misleading approximation of authentic human-like reasoning. Instead, the "full reasoning spectrum problem" is introduced as a desideratum: to consider an AI system successful only to the extent that it models the entire distribution of naturalistic behaviors over a target task.
To enable such broad evaluations, the authors create a custom NLI-style dataset covering a broad landscape of reasoning structures (syllogisms, fallacies, belief biases, stereotyping, causal judgments, primacy/recency effects), avoiding data contamination by generating all items with LLMs and not duplicating any existing NLI public datasets. Central to their proposal is a new six-way NLI scheme: A (absolutely must be false), B (more likely to be false), C (strong reasons to be true and false), D (no clear evidence either way), E (more likely to be true), F (absolutely must be true), thus addressing longstanding critiques of underspecification and lack of granularity in classic three-way NLI.
Human Data Collection and Experimental Paradigm
Human label distributions are collected in two phases using a crowd-sourced Qualtrics survey, employing the two-response paradigm: average participants provide one rapid, distraction-loaded "intuitive" response (System 1) and, after a break, a second deliberative response (System 2) per item. Careful attention checks, adapting the time limits based on participant pacing, and exclusion of noncompliant data result in high-quality, well-calibrated distributions. Empirical analysis demonstrates systematic shifts from System 1 to System 2 (e.g., reductions in selection of likely-but-not-absolutely-true responses), as well as large differences in the shapes of the response distributions by item type.
Multi-Dimensional Evaluation of Model–Human Alignment
Three core evaluation axes are considered for alignment between LLMs (and baseline ML models) and human distributions:
1. Gold Label Prediction (Majority Vote)
- Classical ML classifiers (SGD, decision trees, Random Forest, feed-forward NNs) with hand-engineered features can predict the "majority vote" (mode) better than the chance baseline, but improvement is marginal, and accuracy drops for more granular schemes and for System 2 (deliberative) responses.
- LLMs closely match (and sometimes outperform) classical models here, especially when using personality-based prompts rather than only the base prompt, suggesting that increased granularity and diversity in prompting can render human reasoning more predictable for LLMs.
2. Predicting Variance among Responses
- ML models can (barely) predict variance above the baseline in human response distributions, but LLMs without fine-tuning fail to match observed variance patterns. This reveals the difficulty of capturing distributional spread, especially in higher-dimensional labeling schemes.
3. Full Distributional Similarity (Earth Mover's Distance/Similarity)
- The primary innovation is directly predicting the entire human response distribution for a given item, measured via normalized Earth Mover’s Similarity (EMS). LLMs significantly outperform the best classical models and baselines for distributional prediction, especially when personality-based prompting and genetic algorithm weight optimization are used.
Personality-Based Prompting and Genetic Algorithms
Personality-based prompting leverages the Big Five (OCEAN) model, yielding ten distinct system prompts (e.g., "You're open to new experiences," "You're reserved, quiet..."). Each such prompt elicits a sub-distribution of responses intended to model reasoning styles associated with that trait. The final predicted distribution is obtained by optimizing non-uniform weights over these prompts using a genetic algorithm, trained via K-fold cross-validation. This method outperforms both uniform personality weights and base prompting across all EMS metrics.
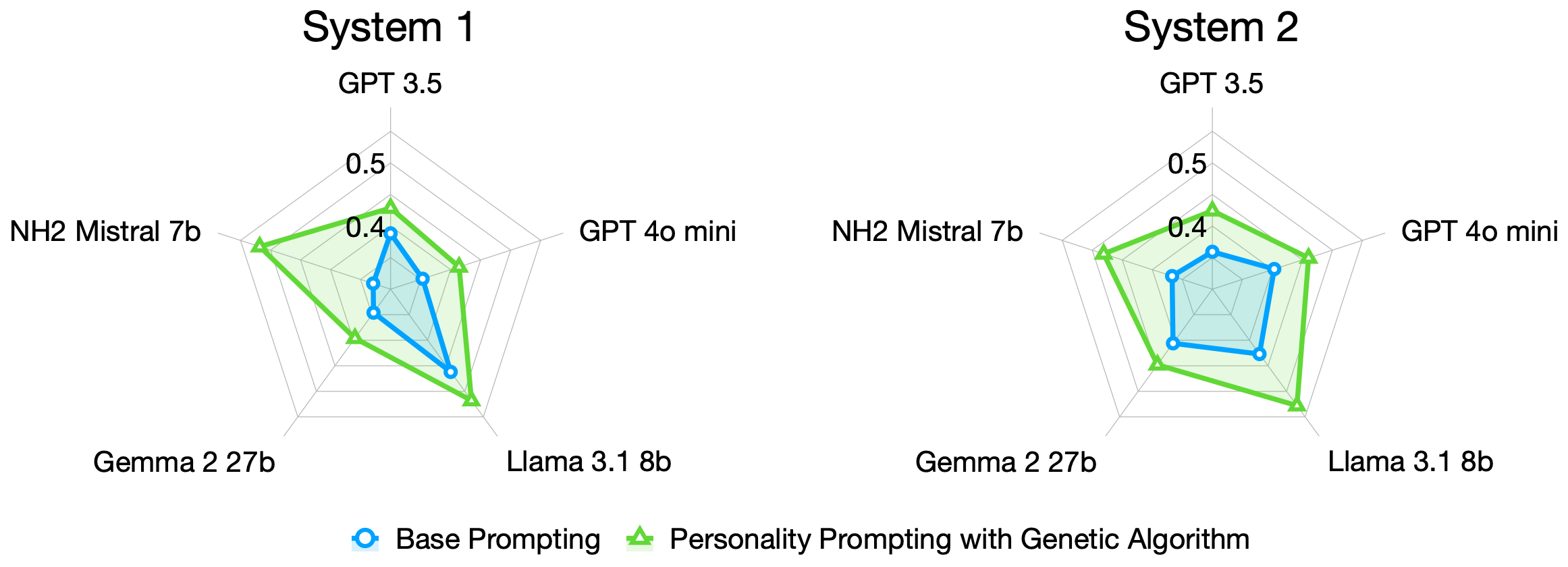
Figure 1: Personality-based prompting and genetic algorithm optimization yield closer alignment between LLMs and human NLI reasoning behaviors.
Notably, this approach achieves distributional human-likeness without any fine-tuning of LLMs—a highly resource- and data-efficient solution compared to traditional parameter-efficient transfer.
Model Comparison and Claims about Open- vs. Closed-Source LLMs
Unexpectedly, open-source models (Llama and Mistral) outperform closed-source GPT architectures in approximating human reasoning distributions both for majority-vote and full-spectrum similarity (EMS), despite the conventional wisdom that larger parameter count and proprietary alignment yield more human-like responses. This is robust under multiple evaluation conditions and with/without personality optimization.
- Resource requirements: The method relies on N repeated prompt invocations (N~10-100 per item for full distribution control), but requires no gradient updates or model fine-tuning—making it suitable for environments without GPU resources and for low-data regimes. The genetic algorithm is relatively inexpensive.
- Scaling: Since the methodology is data- and computation-light, it is easily extensible to larger datasets or additional personality axes, covering broader populations with minimal cost.
- Practical implications: Personality-based prompting + genetic optimization yields richer, more variable and realistic human–AI interaction models. AI output becomes increasingly "human-like" not by further reducing error but by better replicating individual and population-level idiosyncrasies and diversities—including the right distribution of "suboptimal" behaviors.
Broader Theoretical and Practical Implications
This work has several significant implications:
- Modeling Human-Like Reasoning: A system that predicts only the "correct" or modal human answer neglects the reality that human responses are often varied, sometimes systematically "wrong," and are deeply shaped by personality and context. AI, in seeking to model or interact with human populations realistically, must model the full spectrum of possible reasoning pathways, including incorrect and minority outcomes.
- Prompt Engineering as Cognitive Modeling: Prompt engineering can serve as a powerful, low-cost tool for cognitive modeling, not just for steering LLMs for utility tasks. Automated optimization of prompt distributions can recover fine-grained patterns of human reasoning, even in new reasoning domains.
- Critique of Size-Equal-Performance Assumption: The finding that open-source, smaller/sparser or less aligned LLMs match the distribution of human reasoning better than much larger, more heavily aligned GPT models challenges the assumption that increasing model size or human-feedback-alignment necessarily yields greater human-ness in reasoning distribution.
- Methodological Contributions: The six-way NLI categorization and custom datasets enable fine-grained, robust evaluation of both accuracy and spread, avoiding artefactual performance due to data contamination. The use of crowd-sourced, repeated-judgment data for both System 1 and System 2 phases provides rich empirical ground for benchmarking.
- New Directions in Benchmarking and Cognitive AI: The framework suggests new metrics (variance, EMS/EMD, multi-phase response collection) for AI–human benchmarking. Focusing on modeling individual differences and distributional diversity, rather than only central tendency, opens pathways for more sophisticated, robust, and fair AI-human co-systems.
Conclusion
This study introduces a new paradigm in computational cognitive modeling and evaluation, challenging the AI field to move beyond accuracy-centric, majority-vote approximate modeling. By leveraging personality-based prompting and genetic algorithms, LLMs can replicate not just normative, but naturalistic and distributional patterns of human reasoning across both rapidly intuitive and deliberative conditions. The results suggest prompt engineering and distributional modeling are powerful, underexplored tools for bridging the gap between AI and genuinely human-like reasoning. The implication is that the path to truly human-like AI lies not only in further optimizing accuracy, but in capturing (and understanding) the complex, often suboptimal, and profoundly diverse reasoning processes that characterize human populations.