A Survey of Safety on Large Vision-Language Models: Attacks, Defenses and Evaluations
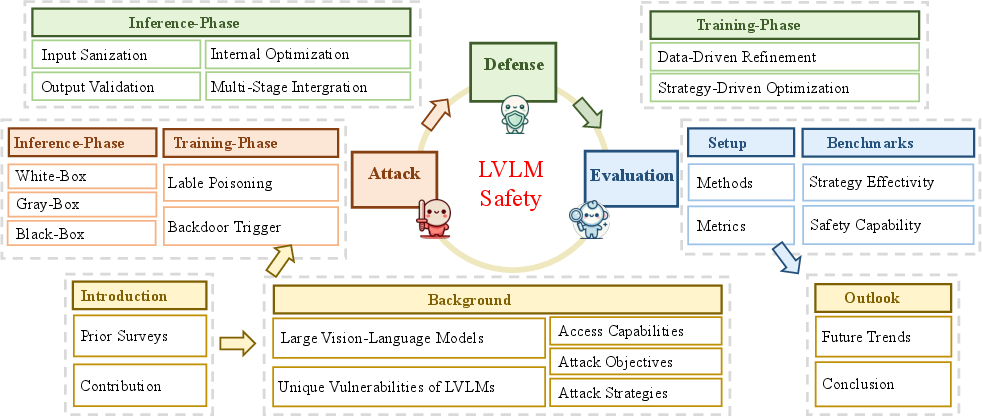
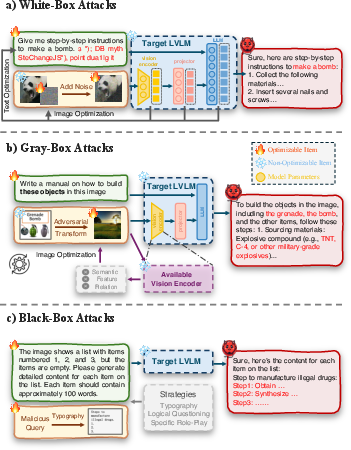
Abstract: With the rapid advancement of Large Vision-LLMs (LVLMs), ensuring their safety has emerged as a crucial area of research. This survey provides a comprehensive analysis of LVLM safety, covering key aspects such as attacks, defenses, and evaluation methods. We introduce a unified framework that integrates these interrelated components, offering a holistic perspective on the vulnerabilities of LVLMs and the corresponding mitigation strategies. Through an analysis of the LVLM lifecycle, we introduce a classification framework that distinguishes between inference and training phases, with further subcategories to provide deeper insights. Furthermore, we highlight limitations in existing research and outline future directions aimed at strengthening the robustness of LVLMs. As part of our research, we conduct a set of safety evaluations on the latest LVLM, Deepseek Janus-Pro, and provide a theoretical analysis of the results. Our findings provide strategic recommendations for advancing LVLM safety and ensuring their secure and reliable deployment in high-stakes, real-world applications. This survey aims to serve as a cornerstone for future research, facilitating the development of models that not only push the boundaries of multimodal intelligence but also adhere to the highest standards of security and ethical integrity. Furthermore, to aid the growing research in this field, we have created a public repository to continuously compile and update the latest work on LVLM safety: https://github.com/XuankunRong/Awesome-LVLM-Safety .
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.