- The paper’s main contribution is its novel integration of reinforcement learning with supervised fine-tuning to achieve high schema adherence.
- It employs synthetic data generation and custom reward functions to optimize structured outputs, ensuring compliance in regulated environments.
- Evaluation shows superior performance against existing methods, achieving high match percentages and minimal noise in JSON outputs.
Think Inside the JSON: Reinforcement Strategy for Strict LLM Schema Adherence
Introduction
Ensuring schema adherence in LLM-generated outputs is of paramount importance, particularly in regulated sectors such as biomanufacturing. The requirement for strict schema adherence arises from the necessity to convert production records into structured digital formats for compliance and analytical purposes. The unpredictability of LLMs in generating structured outputs necessitates a robust framework to enforce adherence to predefined schemas.
To address the challenges of structured generation, existing approaches include techniques such as supervised fine-tuning (SFT), RLHF, constraint-based decoding, and prompt engineering. Each strategy has its effectiveness and trade-offs, with techniques like SFT being resource-intensive and RLHF requiring meticulous reward design. Constraint-based decoding guarantees schema adherence by construction but may introduce complexity, while prompt engineering, though less resource-demanding, does not entirely ensure consistency.
Methodology
The proposed method leverages reinforcement learning and supervised fine-tuning to develop a robust schema-adherent LLM generation framework while maintaining computational efficiency. This pipeline builds on the DeepSeek R1 reinforcement learning framework, applying the following main components:
Synthetic Data and Reasoning Pipeline
- Data Generation: Synthetic datasets containing unstructured to structured pairs are created using controlled prompts with Qwen models.
- Reverse Engineering: Utilizing deep models like the Distilled DeepSeek R1, unstructured text is systematically mapped onto schemas to generate a reasoning dataset.
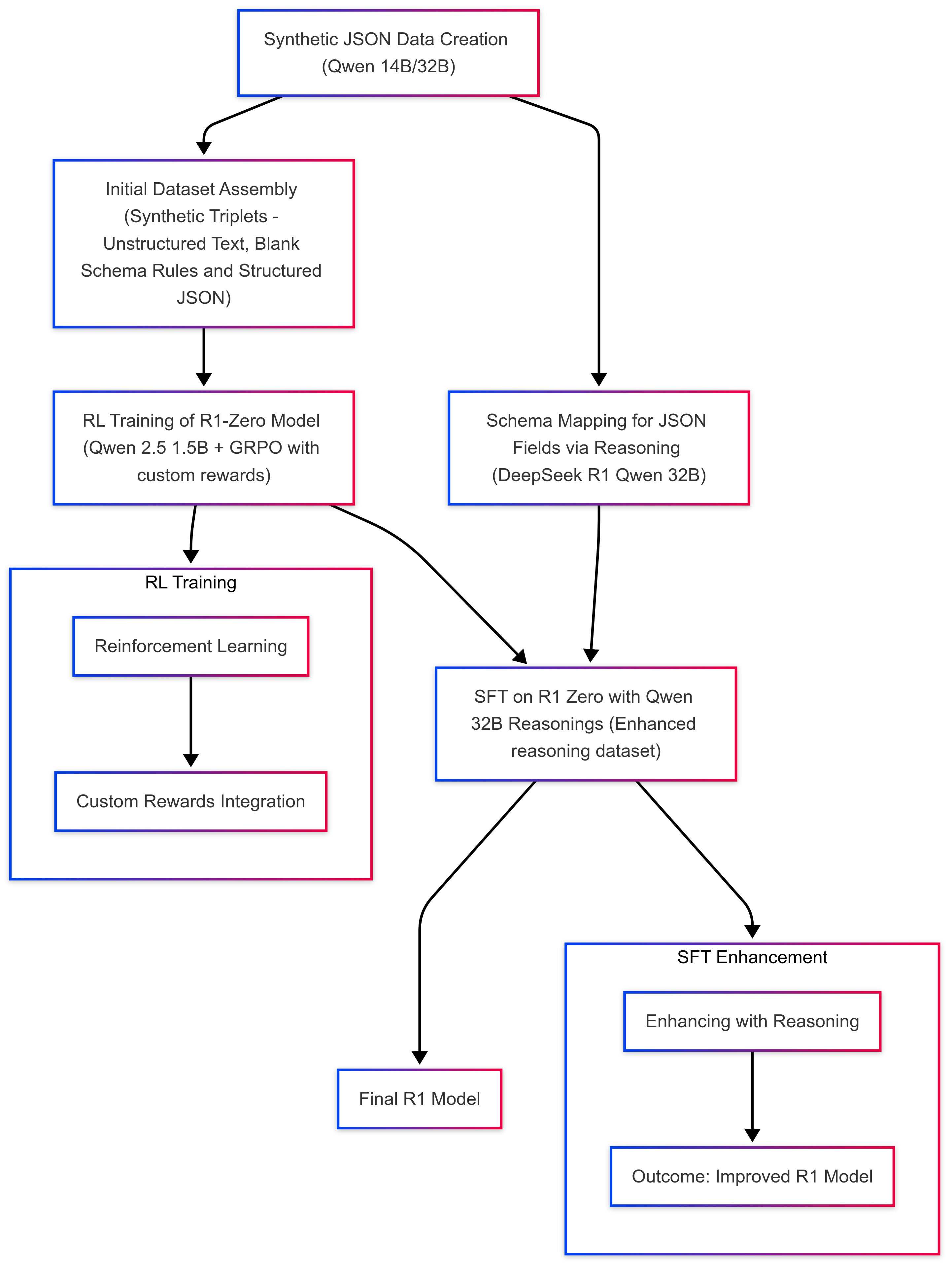
Figure 1: "Think inside the JSON" pipeline.
GRPO Training
The GRPO framework is employed to train a small 1.5B parameter model, emphasizing cost-effectiveness and the capability to adhere to schemas. Custom reward functions focusing on schema adherence are critical for training.
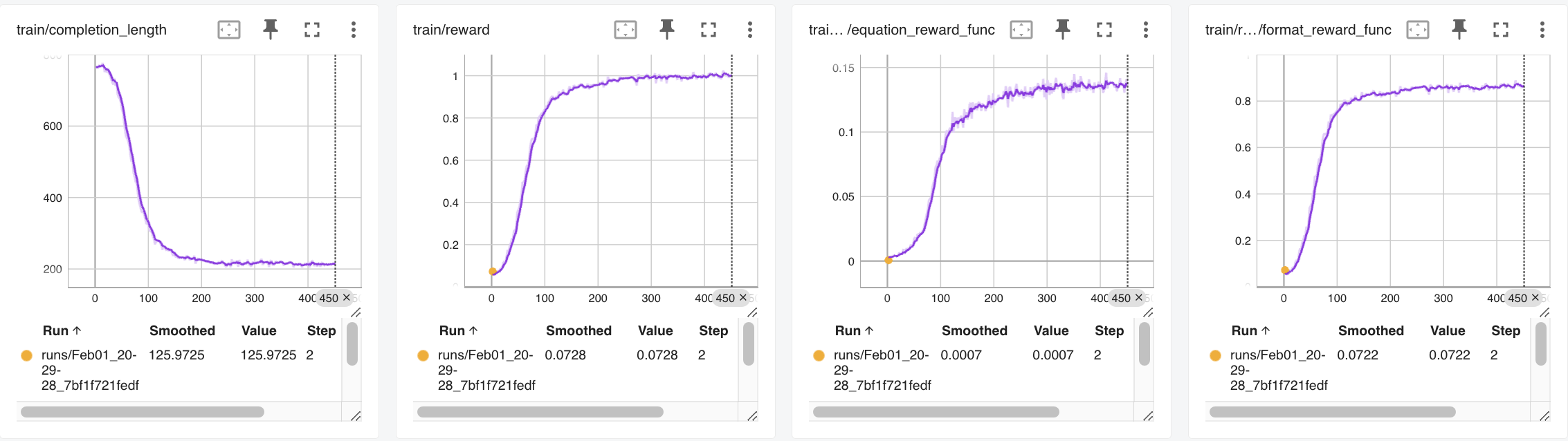
Figure 2: GRPO Training Metrics.
Supervised Fine-Tuning
Following the reinforcement training, SFT refines the task-specific details to ensure models produce output compliant with real-world regulatory requirements. SFT serves as the final alignment step for handling domain-specific nuances that RL fails to address.
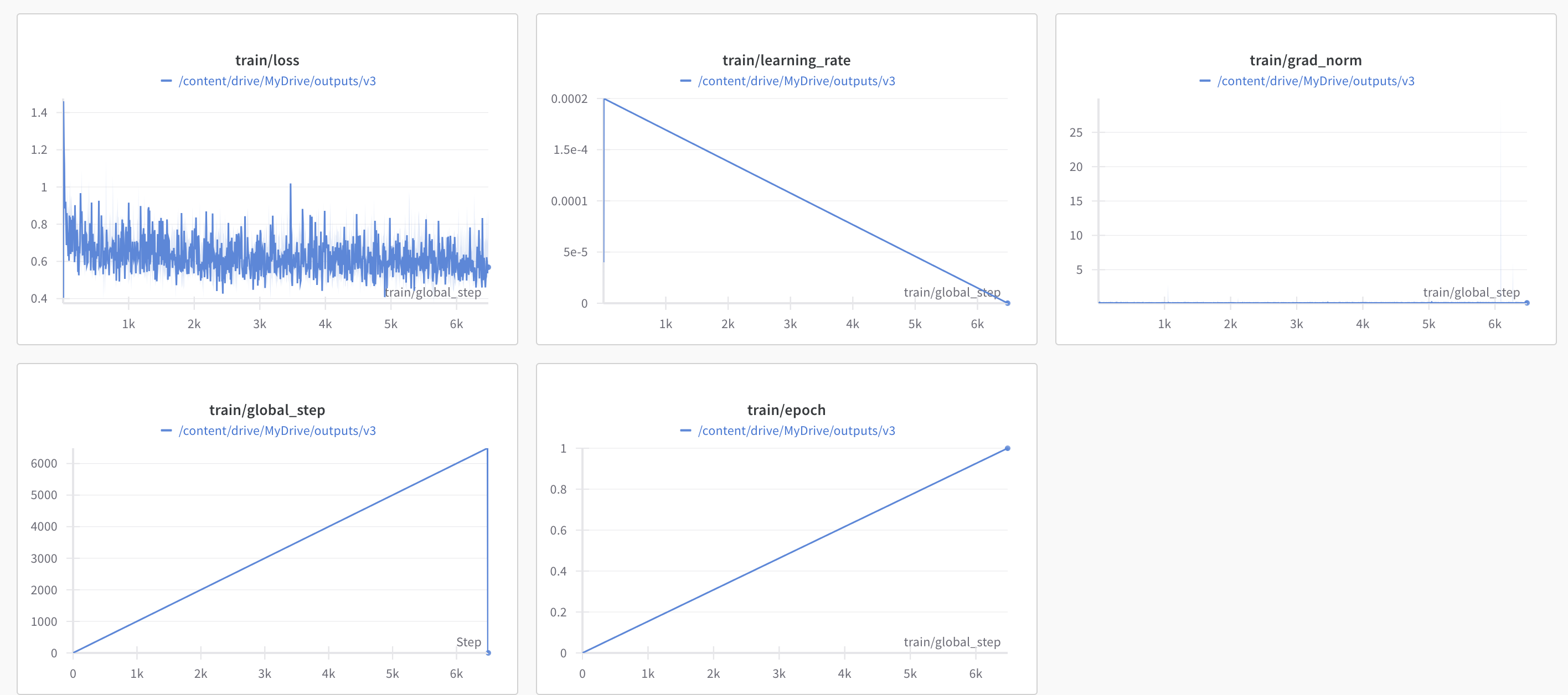
Figure 3: SFT Training Metrics.
Evaluation
Evaluation of the ThinkJSON model against other models—Original DeepSeek R1, Qwen variants, and Gemini 2.0 Flash—demonstrated the model's superiority in generating syntactically valid JSON with a high mean match percentage and minimal noise.
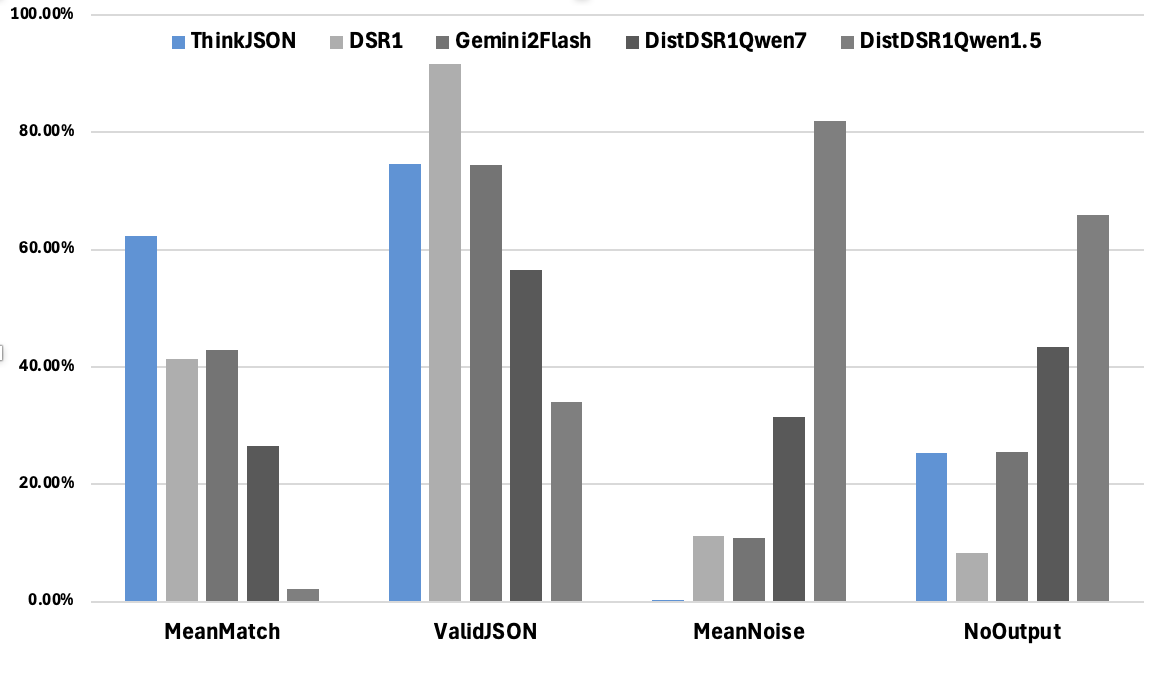
Figure 4: Performance Comparison.
Discussion and Future Work
The proposed structured generation framework effectively addresses the need for reliable AI in regulated bio-manufacturing, ensuring output validity and schema adherence with minimal computational overhead. The reasoning-driven strategy appeals in domains that prioritize compliance and data integrity. Future research will explore scaling to larger models to enhance context interpretation and adaptivity while preserving efficiency. This approach exemplifies a balance between technical robustness and cost, promising broader applicability across diverse regulated domains.
Conclusion
ThinkJSON proves to be a viable path forward in improving structured output from LLMs. By integrating robust reasoning strategies and alignment techniques, it ensures schema adherence without incurring significant resource costs; thus, positioning itself as an integral tool for those focusing on compliance and data governance in AI applications.