- The paper introduces a reflective planning framework that integrates a diffusion dynamics model with vision-language models to refine multi-stage robotic manipulation actions.
- It employs an iterative self-reflection mechanism and interactive imitation learning to improve long-horizon planning and decision-making.
- Experimental validation shows significant improvements in success rates over baselines, indicating potential for broader application in sequential decision-making tasks.
Reflective Planning: Vision-LLMs for Multi-Stage Long-Horizon Robotic Manipulation
Introduction
The paper "Reflective Planning: Vision-LLMs for Multi-Stage Long-Horizon Robotic Manipulation" introduces a new methodology to extend vision-LLMs (VLMs) in solving complex multi-stage robotic manipulation tasks. These tasks require not only high-level planning abilities but also the capability of reasoning about the physical interactions and executing appropriate motor skills. While current VLMs exhibit remarkable visual scene understanding from large-scale internet training, they lack the nuanced understanding needed for intricate physics and long-horizon planning.
Reflective Planning Framework
The core contribution of this research lies in enhancing VLMs through a reflective planning framework. This framework comprises two main components: the use of a diffusion dynamics model to predict potential future states and a reflection mechanism utilizing these predictions for action refinement.
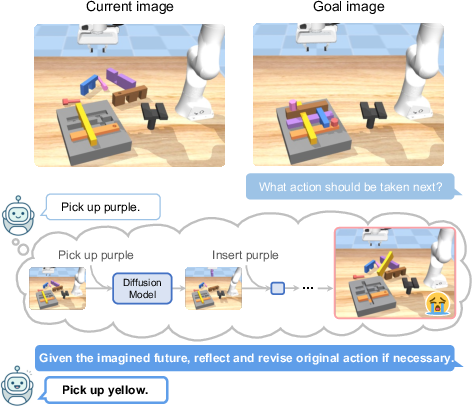
Figure 1: Reflective planning. Our method uses a VLM to propose actions and a diffusion dynamics model to imagine the future state of executing the plan. The imagined future helps the VLM reflect the initial plan and propose better action.
The reflection mechanism iteratively refines VLM actions by critiquing outcomes based on visual predictions of future world states. This iterative refinement is akin to self-critique methods deployed in LLMs and significantly improves the model's decision-making across long-horizon tasks.
Training and Dynamics Model Integration
Training involves interactive imitation learning, with post-training refinement through relabeling rollouts, allowing the VLM to access additional future states for enhanced decision-making.
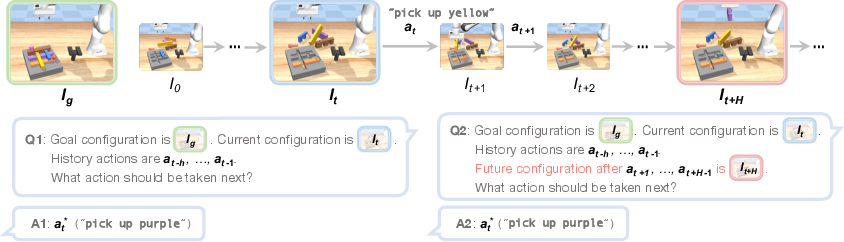
Figure 2: Training data generation. Training data for the reflection mechanism is collected by relabeling the rollouts. For each timestep, two training examples are generated: (Q1, A1) for action proposal and (Q2, A2) for reflection.
To facilitate this, the diffusion dynamics model is employed to simulate future states without actual execution in the environment, enabling the VLM to improve its predictive capabilities effectively.
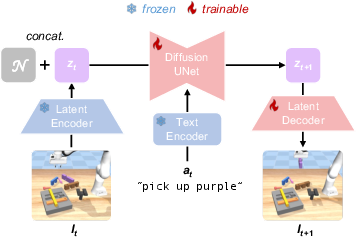
Figure 3: Architecture of Diffusion Dynamics Model, which consists of a latent encoder, text encoder, Diffusion UNet, and latent decoder. The latent encoder and text encoder are frozen during training, while Diffusion UNet and latent decoder are finetuned on our task data.
Experimental Validation
The methodology was empirically validated against baseline models including state-of-the-art VLMs and model-based planning approaches such as Monte Carlo Tree Search (MCTS). ReflectVLM showed a marked improvement in success rates across challenging tasks involving multi-step reasoning and interaction logic.
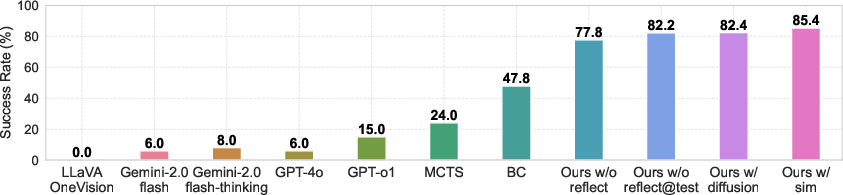
Figure 4: Performance of our method and baselines. Success rate (\%) on 100 tasks. For the zero-shot test of state-of-the-art VLMs and MCTS, the experiments were conducted once; for other methods, the results are the average of five seeds.
The VLM enhanced with the reflection mechanism performs well despite the complexities tied to physical reasoning, only being slightly outperformed in scenarios where simulation-based future predictions are used instead of the diffusion model.
Discussion and Future Work
The results underline the efficacy of integrating structured reflection mechanisms within VLM frameworks, offering potential applications beyond robotic manipulation. Future research directions could focus on expanding this approach to other sequential decision-making domains requiring enhanced physical reasoning and predictive accuracy.
Conclusion
This study presents a robust methodology that extends the capabilities of VLMs for complex robotic manipulation tasks. By integrating diffusion models for future state prediction and a reflection mechanism for decision improvement, the research delineates a promising path for enhancing VLM utility in real-world applications requiring sophisticated reasoning and planning. The approach's adaptability suggests significant potential for scaling and application in various planning problems across AI domains.