- The paper demonstrates that LeanKAN improves memory efficiency and convergence by embedding multiplication directly within the layer.
- It retains the parameter count of traditional AddKAN layers while delivering lower error rates in function approximation, ODE, and PDE tasks.
- Its single hyperparameter design reduces tuning complexity, making it a practical choice for diverse scientific machine learning applications.
LeanKAN: A Parameter-Lean Kolmogorov-Arnold Network Layer with Improved Memory Efficiency and Convergence Behavior
Introduction
The paper introduces LeanKAN, a refined architecture for Kolmogorov-Arnold Networks (KANs), designed to improve memory efficiency and convergence behavior by offering a direct and modular replacement for previously used AddKAN and MultKAN layers. While MultKAN layers incorporate multiplication to improve representation capacity, they are often encumbered by bulky parameterizations and complex hyperparameters. LeanKAN reduces these complexities, positioning itself as a parameter-efficient alternative that is applicable to output layers of data-driven modeling networks.
Kolmogorov-Arnold Networks and LeanKAN
KANs utilize the Kolmogorov-Arnold theorem, which states that any multivariate continuous function can be decomposed into univariate functions, making them suitable for high-dimensional functional approximations. Traditional AddKAN layers solely facilitate addition, limiting their expressivity in representing multiplicative functions. MultKAN layers augment this by facilitating multiplication, but at the cost of increased complexity due to additional nodes and hyperparameters. LeanKAN optimizes this structure by directly embedding multiplication within the layer’s computation, avoiding parameter inflation and ensuring all nodes can represent both addition and multiplication.
Structural and Efficiency Improvements
LeanKAN employs a single hyperparameter, nmu, defining the number of input nodes engaged in multiplication, and incorporates multiplication directly within the layer’s functionality. This design choice avoids the need for additional subnodes seen in MultKAN, leading to enhanced parameter efficiency; LeanKAN retains the same number of parameters as AddKAN, despite supporting multiplicative learning operations. This simplification also reduces the need for complex hyperparameter tuning, facilitating ease of implementation in augmented KAN frameworks such as KAN-ODEs and DeepOKANs.
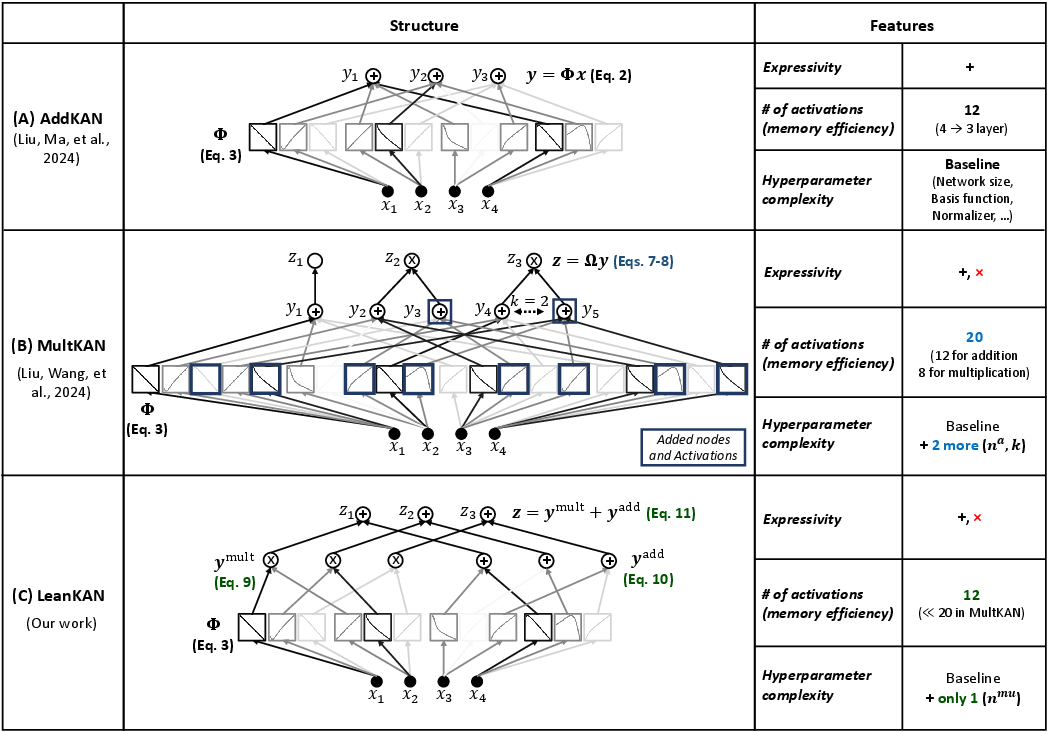
Figure 1: Visualization of the three KAN layers referenced in this work, highlighting LeanKAN’s efficient integration of multiplication within its structure.
Multidimensional Function Approximation
In testing against MultKAN, LeanKAN demonstrated superior memory efficiency and interpretability while maintaining higher or comparable accuracy across various function reconstruction tasks. Specifically, LeanKAN used fewer parameters, owing to its lean architecture, and achieved lower error rates, showcasing its improved computational efficacy for function approximation tasks.
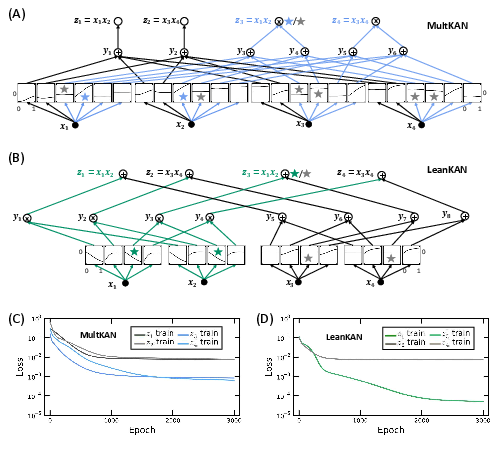
Figure 2: Comparison between MultKAN and LeanKAN for single-layer multiplication training example, illustrating improved memory efficiency with LeanKAN.
Ordinary Differential Equations
The paper applied LeanKAN within the framework of KAN-ODEs to learn dynamic systems under the Lotka-Volterra predator-prey model. LeanKAN illustrated accelerated convergence rates and enhanced accuracy, reducing testing and training loss by an order of magnitude compared to the larger parameter-sized MultKAN networks. This was attributed to its lean parameterization, which mitigates the negative impact of redundant activations, thereby supporting faster and more accurate model training.
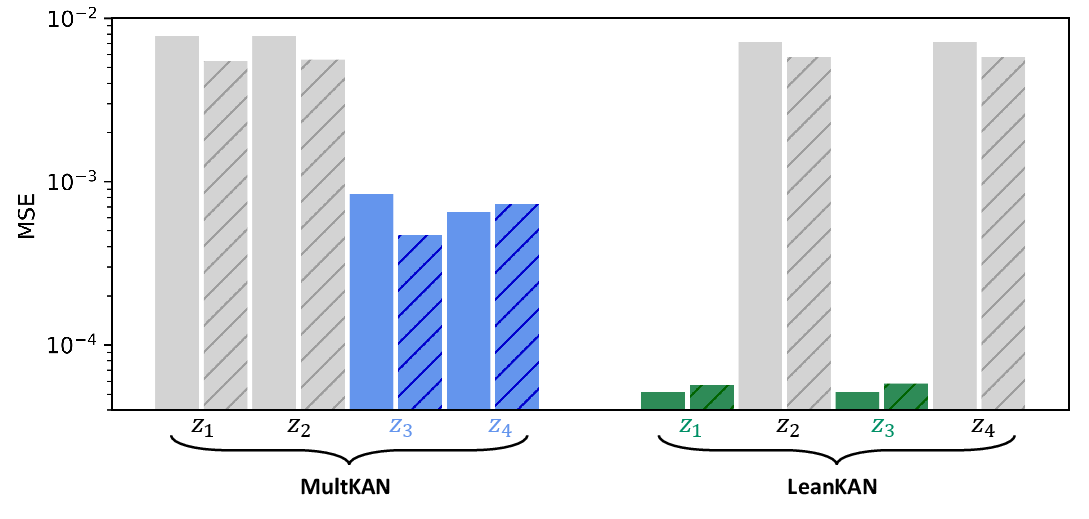
Figure 3: Loss metrics comparison between LeanKAN and MultKAN after extensive training, highlighting LeanKAN's lower training and testing losses.
Partial Differential Equations
LeanKAN was further examined within PDE contexts, specifically in solving Schrödinger-type equations. Here, LeanKAN again demonstrated improved performance and efficiency, presenting a marked reduction in MSE despite a sparse setup. The simpler hyperparameter configuration facilitated easier adaptability and implementation compared to traditional KAN structures.
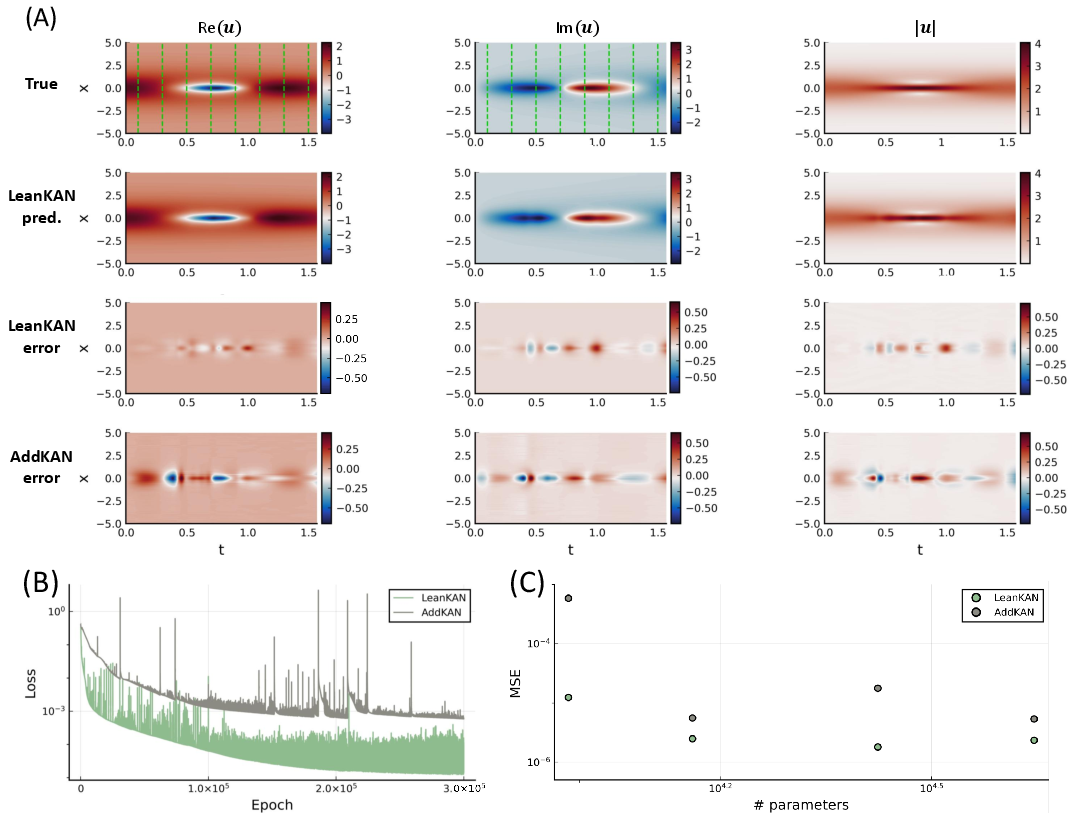
Figure 4: Schrödinger Equation case study results, demonstrating LeanKAN's predictive accuracy and lower error margins compared to AddKAN.
Conclusion
LeanKAN emerges as a viable, memory-efficient replacement for MultKAN and AddKAN layers, especially in augmented network models like KAN-ODEs or DeepOKANs. Its design strategically embeds multiplication without redundant parameters, ensuring simplicity in hyperparameter tuning and accelerating both convergence rates and overall accuracy. The paper suggests widespread applicability for LeanKAN across diverse scientific machine learning applications, where efficient, high-order learning operations are critical.