- The paper introduces FFTNet, which leverages FFT to replace quadratic self-attention with an O(n log n) global token mixing mechanism.
- The methodology features a four-step process: Fourier transform, adaptive spectral filtering, modReLU activation, and inverse FFT, ensuring effective token interactions.
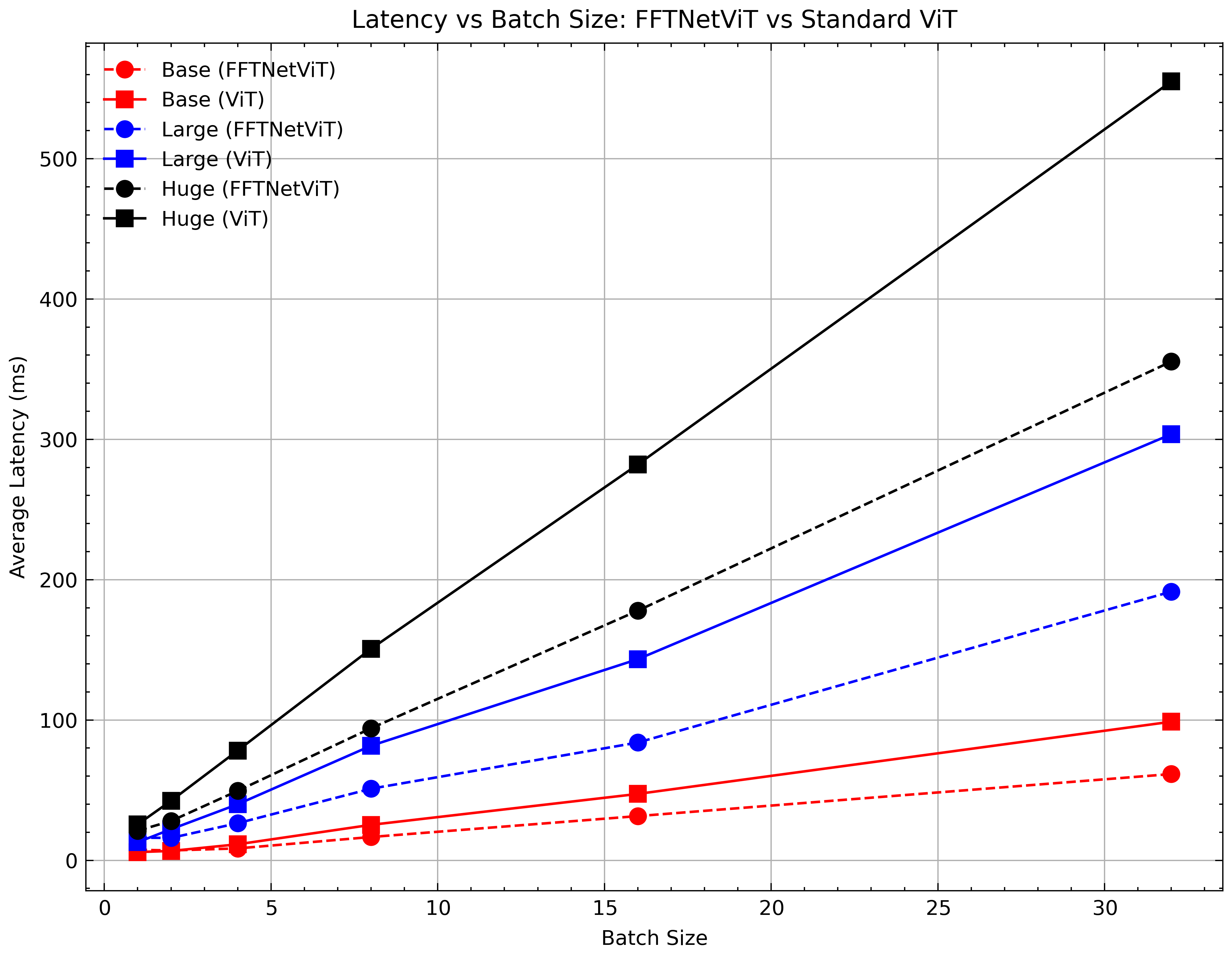
- Experimental results on Long Range Arena and ImageNet illustrate competitive accuracy and reduced latency compared to standard self-attention models.
SPECTRE: An FFT-Based Efficient Drop-In Replacement to Self-Attention for Long Contexts
Introduction
The paper presents FFTNet, an innovative spectral filtering paradigm that addresses the scalability challenges of conventional self-attention mechanisms in neural networks. The authors leverage the Fast Fourier Transform (FFT), offering a reduction in complexity from O(n2) to O(nlogn). This computational efficiency is achieved by transforming sequence inputs into the frequency domain, where orthogonality and energy preservation are maintained through Parseval's theorem. The result is an adaptive global token mixing framework that efficiently captures long-range dependencies.
Methodology
The FFTNet framework comprises four main steps:
- Fourier Transform: The discrete Fourier transform decomposes the sequence into orthogonal frequency components. This step encapsulates global interactions without pairwise computations, laying the groundwork for subsequent filtering.
- Adaptive Spectral Filtering: The authors introduce a learnable spectral filter using a context vector derived from the sequence mean. A modulation tensor is computed through an MLP, allowing dynamic spectral filter adjustment. This adaptability emphasizes salient frequencies crucial for intricate patterns.
- Nonlinear Activation (modReLU): To enhance representation capabilities beyond linear transformations, modReLU is applied to complex components, conditioning on input magnitude while retaining phase information.
- Inverse Fourier Transform: The filtered frequency components are transformed back into the token domain, yielding a globally mixed representation that incorporates adaptive filter dynamics and nonlinear spectral processing.
Computational Complexity
The FFT-based approach prominently reduces computational demand, offering:
Experiments
The authors validate their approach on both the Long Range Arena (LRA) benchmarks and the ImageNet classification tasks, showcasing favorable results:
- Long Range Arena: FFTNet exceeded performance on various tasks (e.g., ListOps, Text) against both standard Transformers and other Fourier-based models like FNet. It achieved a significant accuracy margin on average across these benchmarks.
- ImageNet Classification: FFTNet variants demonstrated competitive Top-1 and Top-5 accuracy, reducing operational overhead through efficient parameter and FLOP management compared to standard ViT architectures.
Theoretical Guarantees
The authors provide robust theoretical underpinnings supporting FFTNet's design, emphasizing:
- Energy Preservation: Parseval's theorem guarantees the transformation's stability, preserving signal norms across transformations.
- Expressivity & Approximation: FFTNet's configuration allows approximation of self-attention dynamics, with complex convolution providing scalable, adaptive interaction modeling.
Conclusion
FFTNet emerges as a practical and efficacious alternative to self-attention, merging FFT's theoretical solid foundation with adaptive filtering capabilities. The proposed framework achieves competitive accuracy and improved computational efficiency, neatly encapsulating a pathway towards scalable sequence modeling without the quadratic encumbrances of conventional self-attention. This work underscores the potential of combining spectral processing with adaptive learning strategies, setting a precedent for future developments in efficient model architectures.