- The paper reveals that using BCE loss in probe training substantially improves the localization and stability of post-hoc attributions.
- It demonstrates how probe architecture complexity, including non-linear MLP probes, enhances both classification accuracy and representation fidelity.
- The study emphasizes revising probe training protocols to bridge the gap between model performance and reliable interpretability.
How to Probe: Simple Yet Effective Techniques for Improving Post-hoc Explanations
This paper investigates the impact of training methodologies on post-hoc explanation quality in deep neural networks (DNNs). It empirically demonstrates the critical yet largely unexplored role of training protocols, specifically the classification layer of DNNs, for obtaining reliable model attributions, a finding that has significant implications for interpretable AI.
Introduction
Post-hoc attribution methods localize features pertinent to a DNN's decisions, offering a bridge in interpreting these often opaque models. Despite their commonplace usage, understanding their dependence on model training details has been insufficiently explored. The authors bring novel insights showing that the model's classification head, although forming a mere fraction of the network's parameters, dramatically affects the fidelity of generated explanations. The paper highlights this dependency across various attribution methods and pre-training paradigms, suggesting adjustments to the head's configuration that remarkably bolster explanation quality.

Figure 1: Impact of Loss (BCE vs.~CE). (a) EPG Scores, and (b) Pixel Deletion scores for Bcos and LRP attributions. BCE probes enhance localization and stability.
Methodology
The paper's methodological contributions lie in its rigorous empirical analyses conducted across distinct tasks and evaluation metrics involving attribution quality. It approaches this through linear and multi-layer perceptron (MLP) probes applied to frozen pre-trained features from DNNs, scrutinizing the resulting attributions through several interpretability metrics, notably localization via grid and energy pointing games.
Setup and Evaluation
The primary hypothesis tested is the significant role of the Binary Cross-Entropy (BCE) loss over Cross-Entropy (CE) for probes, hypothesized to alleviate softmax-induced logit-shift issues inherent to CE. The evaluation is extensive, including a suite of metrics such as pixel deletion for robustness and entropy for compactness, affirming consistent quality improvements in explanations when employing BCE.
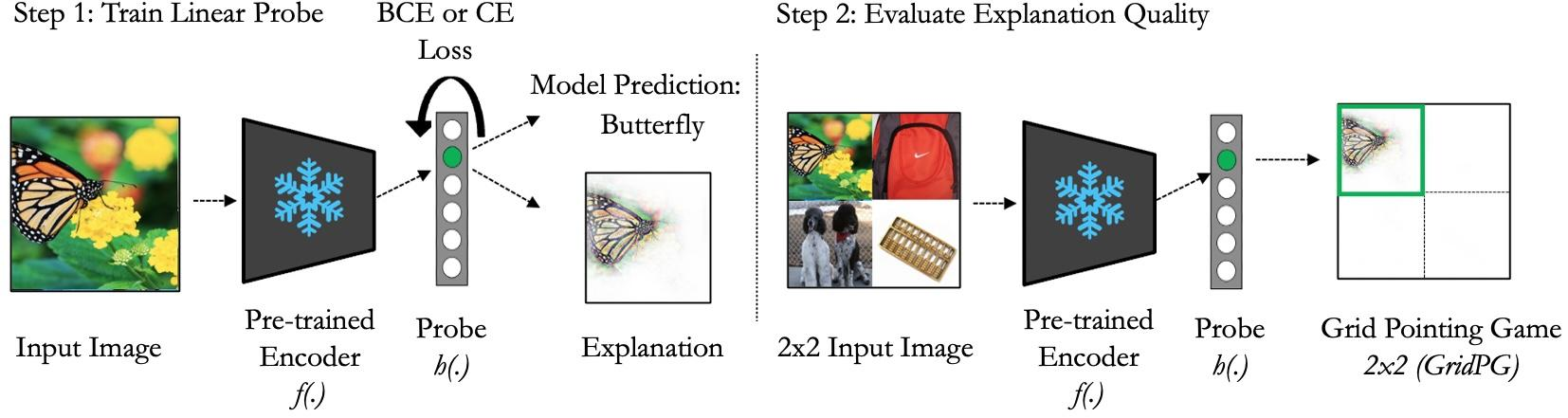
Figure 2: Setup: Step 1. Linear or MLP probes are trained. Step 2. Explanation methods are applied.
Results
BCE vs. CE Loss
The findings confirm that BCE-optimized probes systematically outperform their CE counterparts, yielding more localized attributions across a gamut of pre-training regimes including supervised learning, self-supervised learning (SSL), and vision-language training. This superiority manifests in higher grid and energy pointing scores, along with increased robustness to pixel perturbations.
Complexity of Probes
Moreover, utilizing non-linear, specifically B-cos, MLP probes demonstrated further boosts in both classification accuracy and representational localization, underscoring the advantage of employing a more complex but interpretable architecture for probing.
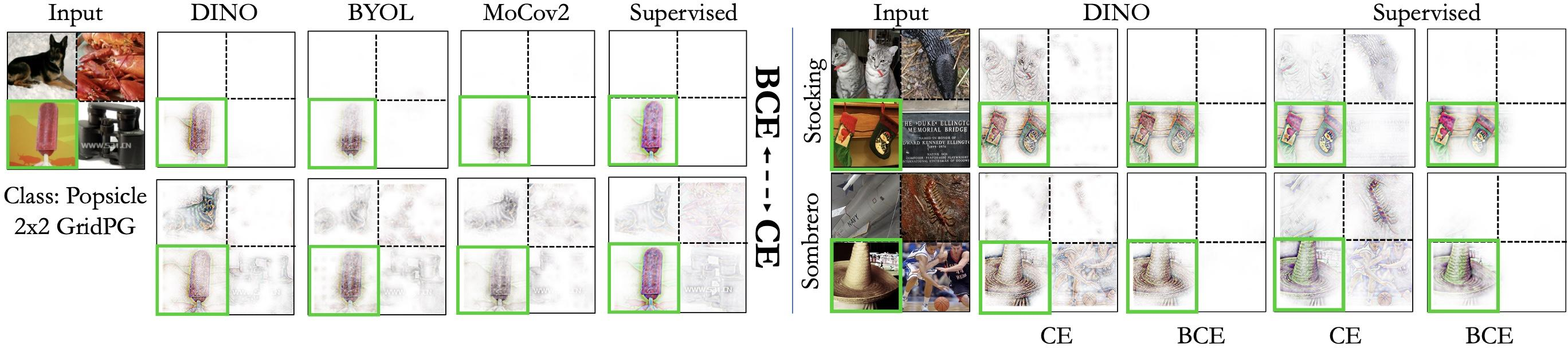
Figure 3: BCE vs.~CE. B-cos attributions show more localized effects with BCE-trained linear probes compared to CE.
Discussion
The implications are profound: choice of training loss at the probe layer can enhance downstream interpretability without altering the core backbone model. These results argue for a reconsideration of how interpretability assessments are normally decoupled from training considerations—suggesting tighter integration could lead to both performance and interpretation improvements.
Conclusion
This study unveils the underappreciated yet pivotal role of probe training configurations in deriving high-quality DNN attributions. By systematically exploring the effect of loss functions and probe complexity, it provides both theoretical and practical insights into optimizing AI systems for interpretability. Future work may leverage these findings to craft explanation-aware training protocols, further bridging the gap between model performance and transparency.