- The paper demonstrates that language models exhibiting innate reasoning behaviors, such as subgoal setting and backward chaining, significantly improve through reinforcement learning.
- Experiments reveal that priming models with curated datasets to simulate these behaviors results in marked performance gains even in initially weaker models.
- Selective pretraining aimed at amplifying cognitive patterns shows potential for transferring improved problem-solving skills to complex domains like mathematical reasoning.
Cognitive Behaviors in Self-Improving Reasoners
The paper presents an exploration into the cognitive behaviors that facilitate self-improvement in LLMs, specifically examining four habits critical to enabling effective reasoning. Through a series of experiments on reasoning tasks, the authors investigate how these behaviors, both in innate and primed forms, contribute to models' capabilities to improve via reinforcement learning (RL).
Framework for Analyzing Cognitive Behaviors
The authors identify four key cognitive behaviors: verification, backtracking, subgoal setting, and backward chaining. These behaviors, akin to human reasoning processes, are posited to significantly impact the ability of LLMs to effectively utilize test-time computation for reasoning tasks.
- Verification is the systematic error-checking of intermediate results, ensuring correctness at each step.
- Backtracking involves abandoning failing approaches and revisiting previous decision points when errors are detected.
- Subgoal Setting decomposes complex problems into manageable steps, facilitating gradual progress towards a solution.
- Backward Chaining involves reasoning from the desired outcomes back to initial inputs, often used in goal-directed tasks.
Importance of Initial Behaviors
Through their investigations, the authors demonstrate that models which naturally exhibit these cognitive behaviors (e.g., Qwen-2.5-3B) show marked improvements when subjected to reinforcement learning, while models lacking these behaviors (e.g., Llama-3.2-3B) plateau. This insight underscores the importance of these cognitive patterns in enabling efficient learning.
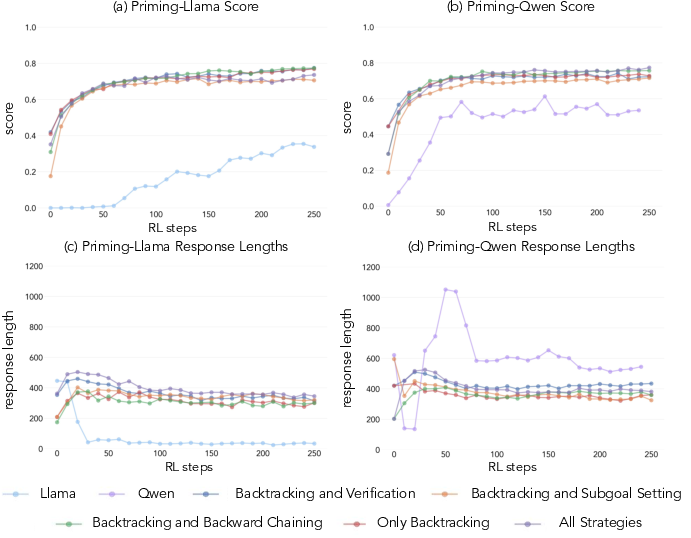
Figure 1: The effects of priming with different cognitive behaviors. Performance comparison illustrates the influence of reasoning behavior priming on scores.
Priming and Intervention Strategies
To explore the potential for inducing these behaviors artificially, the authors implement interventions by priming models with curated datasets exhibiting distinct reasoning patterns. This approach effectively augments models initially devoid of such behaviors, allowing them to improve through RL even with incorrect solutions, as long as they contain the proper reasoning patterns.
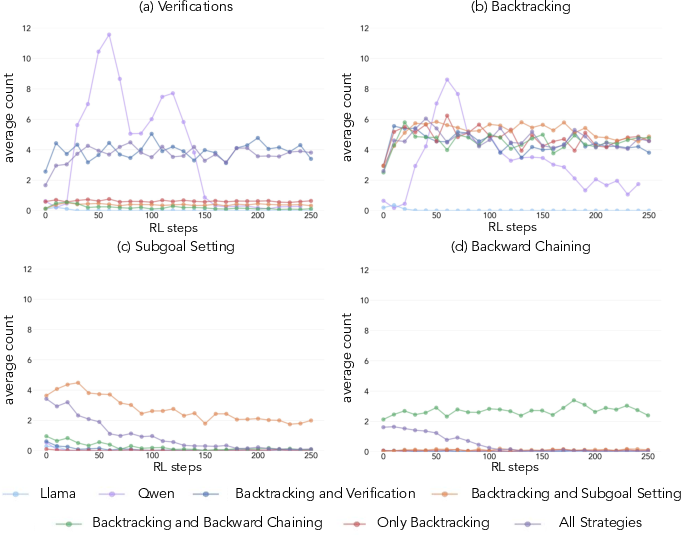
Figure 2: Analysis of four key reasoning behaviors with Llama-3.2-3B, and primed variants, highlighting the role of subgoal setting and backtracking.
Role of Pretraining Data
The study further examines how modifying pretraining distributions to amplify cognitive behaviors can enhance models' learning trajectories. By selectively curating pretraining data abundant in valuable reasoning behaviors, the authors are able to induce the necessary cognitive patterns for efficient self-improvement.
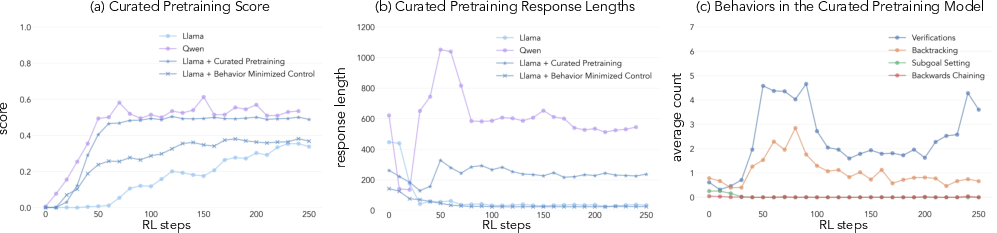
Figure 3: Impact of curated pretraining on model performance and behavior, highlighting how induced behaviors affect training outcomes.
Strategies for Task-Specific Adoption
Different tasks demand specific cognitive behaviors for optimal performance. In domains like mathematical reasoning, the presence of these behaviors aligns closely with successful problem-solving strategies. The authors emphasize that reinforcement learning can amplify behaviors displayed during successful trajectories, hence initial capabilities are essential for learning.
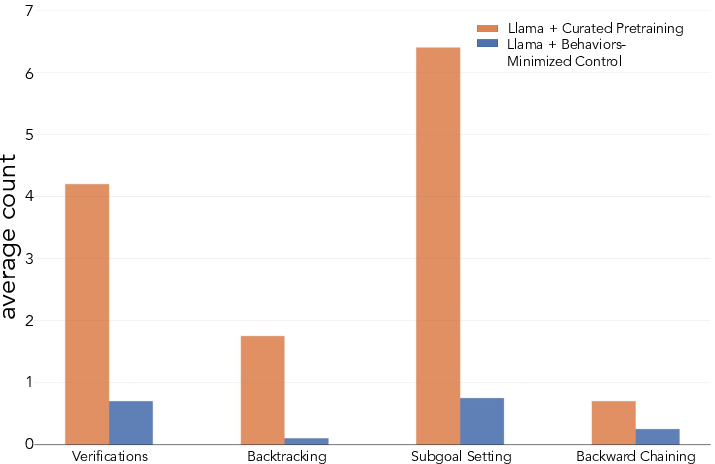
Figure 4: Transfer of Behaviors to Question Answering, showing how cognitive behaviors from mathematical reasoning extend to broader domains.
Discussion and Implications
The paper concludes that the presence and amplification of certain cognitive behaviors are crucial for models to utilize test-time computation effectively. This foundational relationship between a model's initial reasoning capabilities and its ability to self-improve highlights a pathway for developing more proficient AI systems.
The study raises important considerations regarding the generality of these behaviors across tasks, suggesting that future work should explore how domain-specific constraints interact with cognitive patterns. As AI continues to evolve, understanding and engineering models with intrinsic reasoning abilities will be pivotal in advancing their problem-solving capabilities.
Conclusion
The findings illustrate how cognitive behaviors can be harnessed to enable self-improvement in LLMs. By exhibiting these behaviors, models become capable of using additional compute to tackle increasingly complex challenges. This research sheds light on the fundamental role of cognitive behaviors in fostering intelligence within AI systems, paving the way for future advancements in artificial reasoning.