- The paper introduces a novel approach by eliminating top-layer feature prediction constraints and using direct token prediction to speed up inference.
- It leverages multi-layer feature fusion to capture richer semantic information, enhancing token accuracy and robustness.
- Experimental results demonstrate up to a 6.5x speedup across multiple tasks, supporting efficient real-time LLM applications.
EAGLE-3: Scaling up Inference Acceleration of LLMs via Training-Time Test
Introduction
The paper "EAGLE-3: Scaling up Inference Acceleration of LLMs via Training-Time Test" explores advancements in speculative sampling methods for accelerating the inference of LLMs. The sequential computation requirements of LLMs result in high inference costs and latency. EAGLE-3 introduces techniques that significantly improve performance by focusing on direct token prediction and utilizing multi-layer feature fusion, discarding previous constraints associated with feature prediction. These methods aim to leverage increased training datasets to enhance inference acceleration without compromising on model quality (2503.01840).
Key Improvements in EAGLE-3
Removal of Feature Prediction Constraints: EAGLE-3 eliminates the reliance on predicting top-layer features and instead focuses on directly predicting tokens. The removal of this constraint allows a more flexible draft model and facilitates better scaling with increased training data.
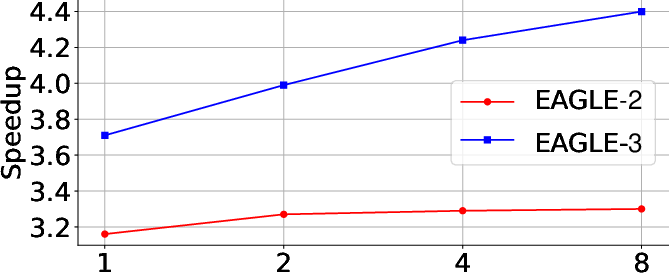

Figure 1: Scaling law evaluated on the MT-bench using LLaMA-Instruct 3.1 8B as the target model, with the x-axis representing the data scale relative to ShareGPT. The new architectural designs in EAGLE-3 enable an increasing scaling curve, which was never observed in the previous works.
Multi-layer Feature Fusion: Unlike previous methods that use features from either a single layer or top-layer features, EAGLE-3 utilizes a fusion of low, middle, and high-level features. This approach captures richer semantic information, improving expressiveness and token prediction accuracy.
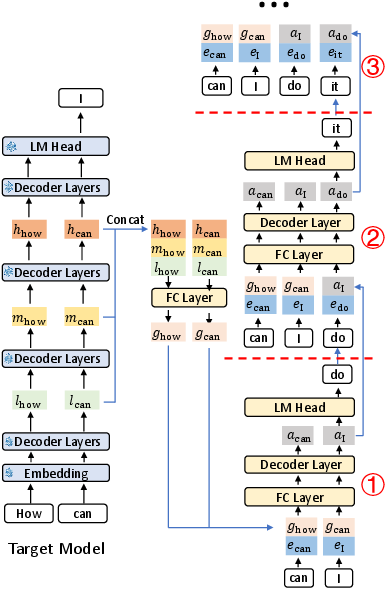
Figure 2: Diagram of the EAGLE-3 inference pipeline, illustrating the three steps of the draft model. l, m, and h represent the low, middle, and high-level features of the target model, respectively. e denotes the embedding.
Experimental Results
EAGLE-3 tested various open-source models, demonstrating superior performance across five tasks: multi-turn conversation, code generation, mathematical reasoning, instruction following, and summarization. The authors report a maximum speedup ratio of 6.5x and significant improvements over earlier versions like EAGLE-2, highlighting the effectiveness of EAGLE-3's architectural innovations.
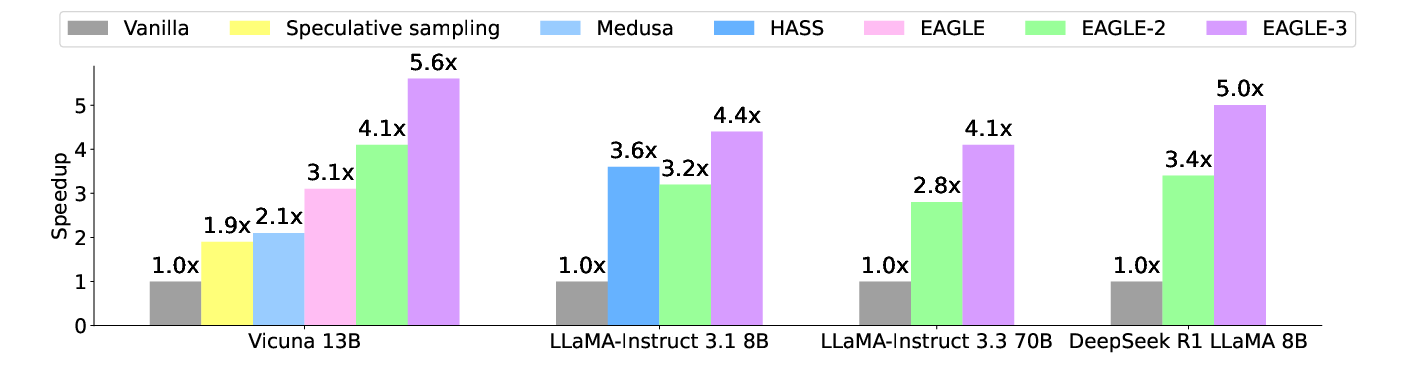
Figure 3: Speedup ratios of different methods at temperature=0.
Acceptance Rates and Speedup: EAGLE-3 achieves notable improvements in acceptance rates of draft tokens compared to previous methods like EAGLE. The experiments reveal consistent acceptance rates across inputs with increased self-predicted values. This reflects the robustness of EAGLE-3’s training approach and its ability to maintain high performance even with enhanced input complexity.
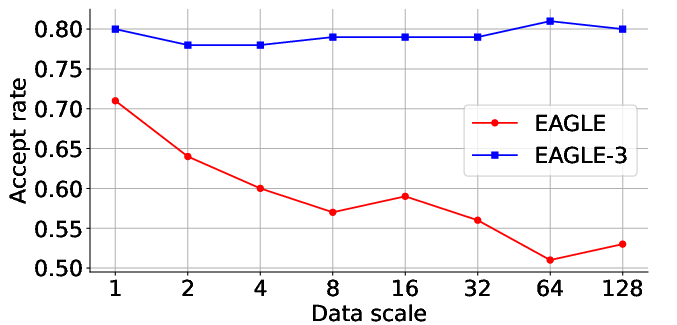
Figure 4: Acceptance rate of EAGLE and EAGLE-3 on MT-bench, with the target model being LLaMA-Instruct 3.1 8B.
Implications and Future Directions
The enhancements provided by EAGLE-3 offer practical benefits in deploying LLMs for real-time applications where latency is a critical constraint. The observed scaling behavior with increased data suggests potential expansions in efficiency for even larger datasets and models. Future developments may explore further optimization avenues such as adaptive layer selection or integrating external knowledge bases to further boost LLM capabilities while minimizing computational overhead.
Conclusion
EAGLE-3 represents a significant step forward in speculative sampling methods, demonstrating notable improvements in inference acceleration for LLMs. By eschewing feature prediction constraints and adopting a multi-layer fusion approach, EAGLE-3 sets the stage for future advancements in efficient LLM deployment. This paper’s findings reveal a clear pathway towards scalable, fast, and efficient LLM inference (2503.01840).