Deep Learning is Not So Mysterious or Different
Abstract: Deep neural networks are often seen as different from other model classes by defying conventional notions of generalization. Popular examples of anomalous generalization behaviour include benign overfitting, double descent, and the success of overparametrization. We argue that these phenomena are not distinct to neural networks, or particularly mysterious. Moreover, this generalization behaviour can be intuitively understood, and rigorously characterized, using long-standing generalization frameworks such as PAC-Bayes and countable hypothesis bounds. We present soft inductive biases as a key unifying principle in explaining these phenomena: rather than restricting the hypothesis space to avoid overfitting, embrace a flexible hypothesis space, with a soft preference for simpler solutions that are consistent with the data. This principle can be encoded in many model classes, and thus deep learning is not as mysterious or different from other model classes as it might seem. However, we also highlight how deep learning is relatively distinct in other ways, such as its ability for representation learning, phenomena such as mode connectivity, and its relative universality.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Deep Learning Is Not So Mysterious or Different — A Simple Explanation
Overview: What is this paper about?
This paper argues that some famous “weird” behaviors people see in deep learning—like huge models working well, models that fit random noise yet still do fine on real data, and test error going down-then-up-then-down again as models get bigger—are not actually mysterious or unique to deep neural networks. The author shows that:
- These behaviors also show up in very simple models.
- Longstanding theories can explain them clearly.
- A key idea called soft inductive bias ties everything together.
The main questions the paper asks
- Why do very large models (sometimes even larger than the dataset) still generalize well to new data?
- How can a model perfectly fit random noise but still perform well on real, structured data (benign overfitting)?
- Why does test error sometimes go down, then up, then down again as we increase model size (double descent)?
- Do we need brand-new theory to explain deep learning, or do existing tools already work?
How the authors approach these questions
The paper uses both simple examples and established theory to make its case:
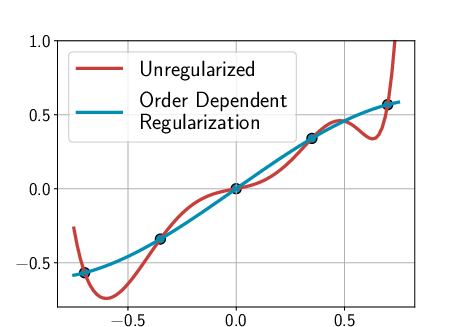
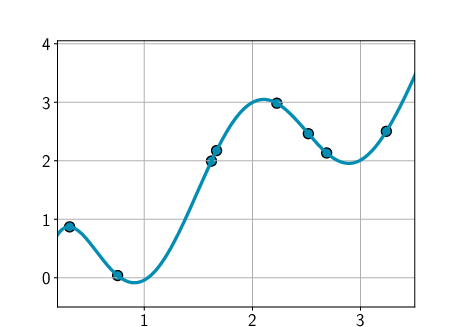
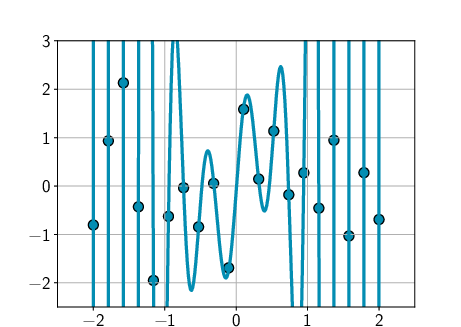
- Simple models: The author shows that even a basic model like a high-degree polynomial (a curve with many wiggles) can behave like a deep net if you set it up with the right “preference” for simple solutions. Another example uses linear models with random features. These reproduce the same “mysterious” behaviors seen in deep learning.
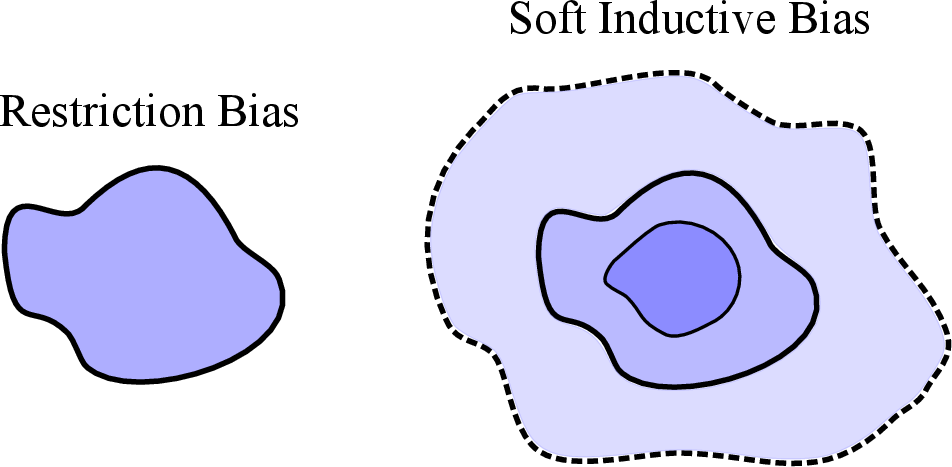
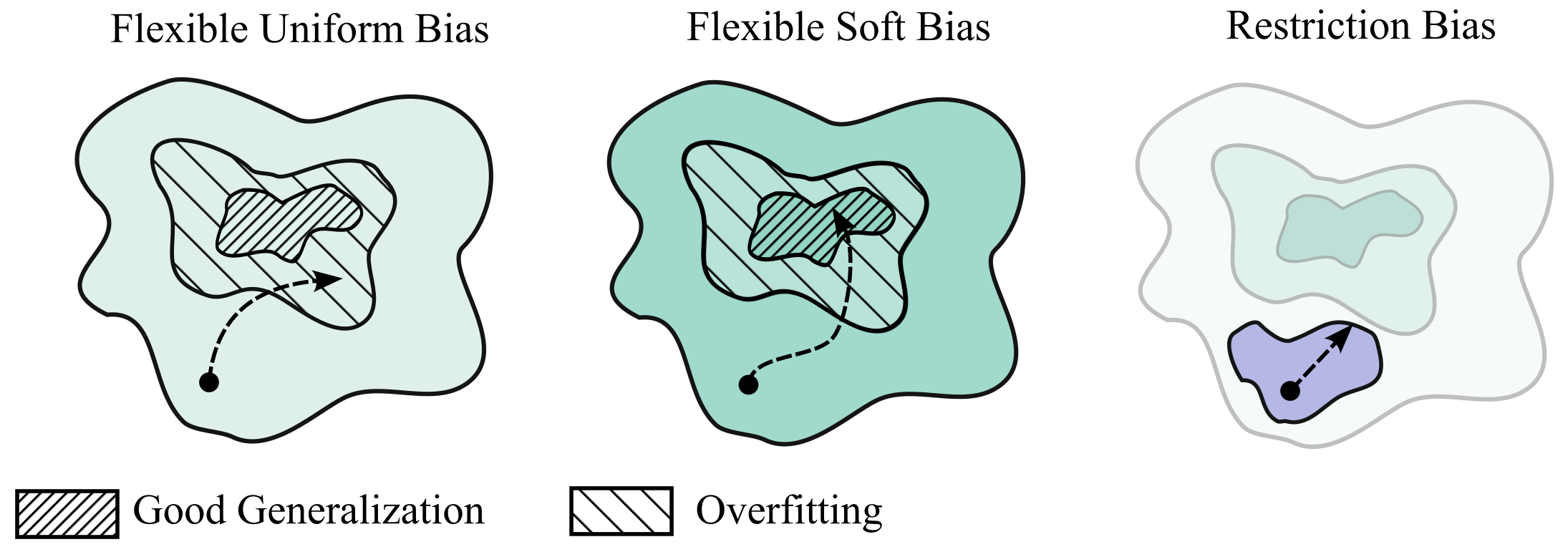
- Soft inductive bias: Instead of banning complicated solutions, you allow all possible solutions but gently prefer simpler ones. Think of it like a dress code that says “prefer plain T‑shirts,” not “T‑shirts only.” This “soft bias” can come from:
- Regularization (penalties that make messy solutions less attractive),
- Bayesian priors (preferences built into the model before seeing data),
- Architecture choices that encourage simple patterns (like symmetry or compression).
- Generalization theory that already exists:
- PAC-Bayes and countable-hypothesis bounds: These are math tools that say your future test error is small if two things are true: your training error is small and your final model can be described simply (it’s compressible—like a small zip file).
- Kolmogorov complexity: A fancy way to measure “how short is the description of your solution?” Shorter is simpler.
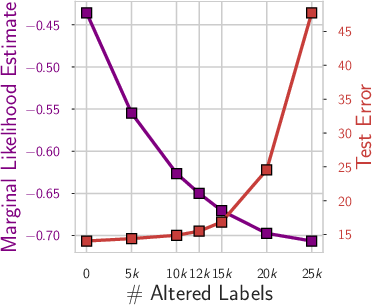
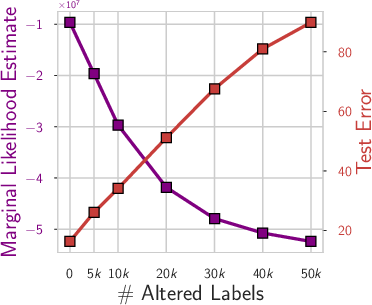
- Marginal likelihood: A Bayesian score that lines up with these bounds and rewards solutions that explain the data well without being overly complicated.
- A helpful intuition: effective dimensionality. Imagine your model has lots of knobs (parameters), but only some really matter for the final result. Effective dimensionality measures roughly how many knobs are “sharp” and need to be tuned. Flatter solutions (fewer sharp knobs) are simpler, compress better, and usually generalize better.
What the paper finds and why it matters
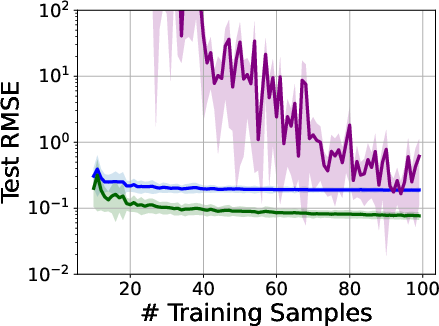
1) Benign overfitting is not unique to deep nets
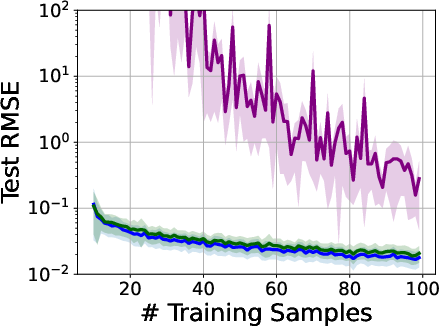
- What people saw: Big neural networks can perfectly fit random labels but still do well on real tasks.
- What the paper shows: Simple models can do this too if they have soft biases toward simple explanations. For real, structured data, the model naturally picks a simple pattern; for pure noise, it will still fit if forced, but that doesn’t mean it will overfit real structure.
- Why this matters: You don’t need brand-new theory to explain this—PAC-Bayes and related ideas already do.
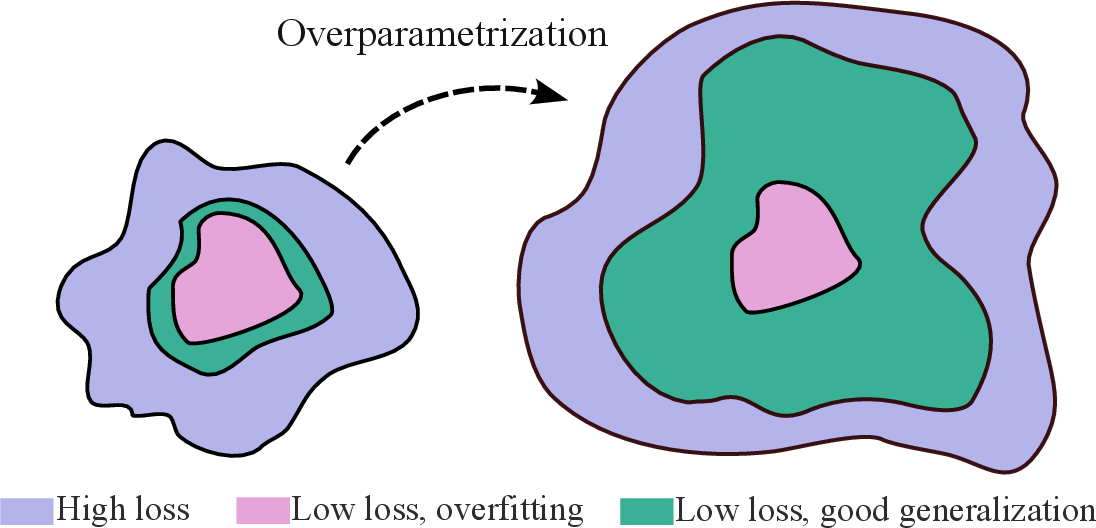
2) Overparameterization (having more parameters than data) can help
- What people assume: More parameters means more overfitting.
- What actually happens: Bigger models can be both more flexible and more biased toward simple, “flat” solutions. Bigger models often compress better after training and end up with fewer “effective” parameters. They contain many ways to fit the data well, and many of those ways are simple and generalize.
- Why this matters: Counting parameters isn’t a good measure of how complex a model really is. Simplicity and compressibility matter more.
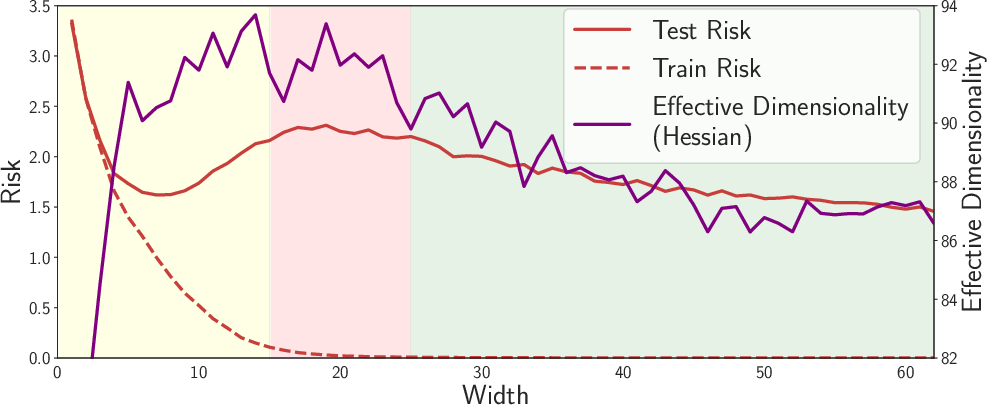
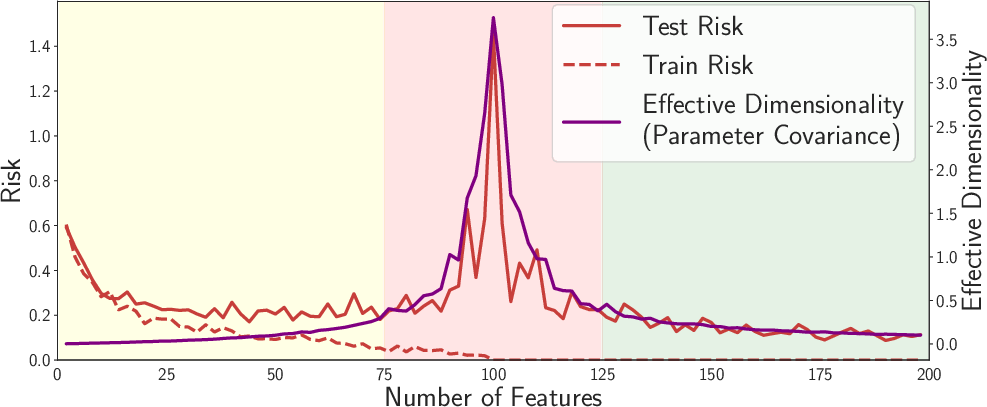
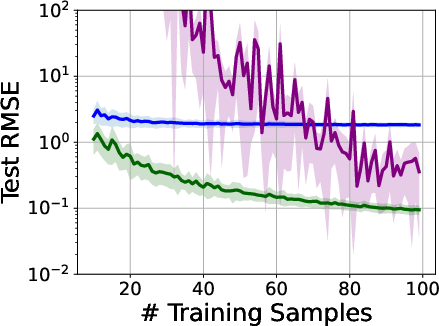
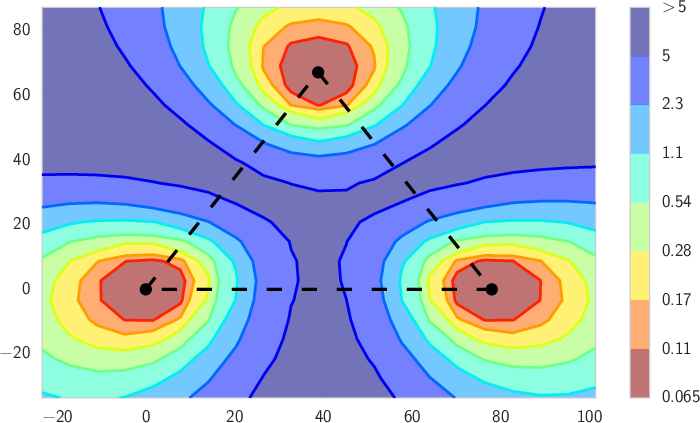
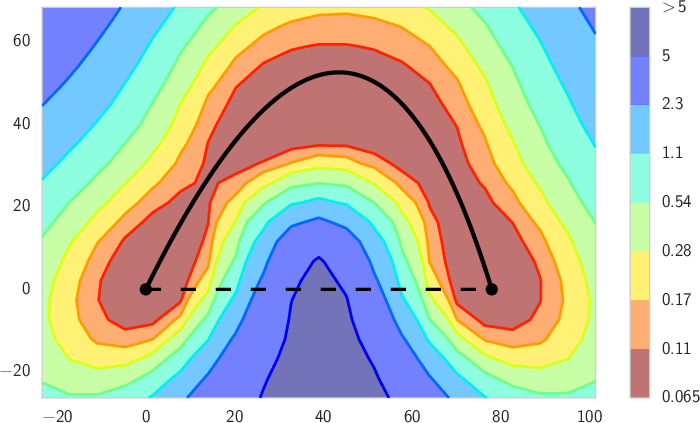
3) Double descent has a clear, non-mysterious explanation
- The pattern: As model size grows, test error goes down (good), then up (overfitting), then down again (surprisingly good).
- Intuition:
- Small to medium size: The model learns useful structure (test error drops).
- Mid-size “bump”: The model starts to overfit (test error rises).
- Very large size: There are so many good, flat (simple) solutions that training naturally finds these compressible ones, and test error drops again.
- Why this matters: This effect is not special to deep nets; simple linear models can show it too. The second descent is about finding simple, flat solutions in a vast space, not about “more flexibility = more overfitting.”
4) The right theory matches what we see in practice
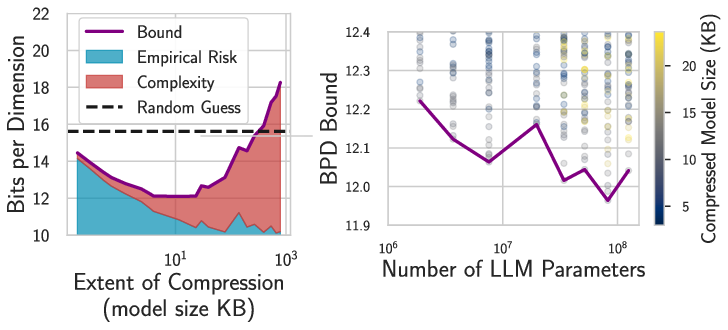
- PAC-Bayes and countable-hypothesis bounds say: expected test error ≤ training error + a simplicity/compression term.
- This matches observations:
- Large models that compress well (small file size, flat minima) can generalize.
- These bounds can be made non-vacuous (actually meaningful) even for very large models, including LLMs.
5) Deep learning is still special in other ways
- While generalization isn’t so mysterious, deep nets do stand out for:
- Representation learning (discovering useful features),
- Mode connectivity (different good solutions are connected in parameter space),
- Broad, often universal usefulness,
- Strong in-context learning in LLMs.
Why this is important
This paper tells us we don’t need to throw out decades of learning theory to understand why deep learning works. If we focus on:
- letting models be flexible,
- nudging them toward simpler explanations,
- and measuring how compressible and flat their solutions are,
then the “mysteries” like benign overfitting, overparameterization, and double descent make sense. This helps guide how we design and train future models: build flexible systems with strong, soft preferences for simple, compressible solutions.
Key terms in plain language
- Inductive bias: The model’s built-in preferences for certain types of solutions. Hard bias: strict rules (“must”). Soft bias: gentle preferences (“prefer”).
- PAC-Bayes: A generalization framework that says you’ll do well on new data if you both fit the training data and keep the final solution simple/compressible.
- Kolmogorov complexity: How short a description (like the shortest computer program) can produce your solution. Shorter = simpler.
- Compressibility: If a trained model can be saved as a small file, it’s simpler and more likely to generalize.
- Effective dimensionality: How many “truly important knobs” the solution is using. Fewer important knobs means flatter, simpler, more robust solutions.
- Marginal likelihood: A Bayesian score that prefers models that can explain the data well without needing overly complicated settings.
Bottom line
Deep learning’s surprising behaviors aren’t so surprising after all. They appear in simple models too and can be explained by well-known ideas. The winning recipe is: allow lots of possibilities, but softly prefer the simple ones that fit the data—then good generalization follows.
Collections
Sign up for free to add this paper to one or more collections.