- The paper introduces Tabby, a novel transformer-based model employing MoE layers to capture column-specific distributions in tabular data synthesis.
- The paper demonstrates that plain training techniques combined with architectural modifications significantly improve the quality of synthetic tabular and nested datasets.
- The paper shows that Tabby's approach yields superior performance based on MLE metrics, outperforming larger non-Tabby models in realistic data generation.
Tabby: Tabular Data Synthesis with LLMs
The paper "Tabby: Tabular Data Synthesis with LLMs" introduces novel approaches for synthesizing high-fidelity tabular data using transformer-based LLMs. It addresses the complexities inherent in tabular datasets, such as heterogeneous data types and unimportant column order correlations, and proposes effective solutions through architectural modifications and training techniques.
Introduction to Tabular Challenges
Tabular datasets exhibit intricate challenges due to complex column interdependencies, diverse data types across columns, and the potential for spurious correlations arising from column arrangements. Traditional data synthesis models tend to overlook these nuances, leading to suboptimal performance. Efforts to tailor generative models like GANs, LLMs, and diffusion models to tabular synthesis have encountered significant preprocessing hurdles, limiting their efficacy. The development of specialized Large Tabular Models (LTMs) necessitates curated tabular pretraining sets, tailored model architectures, and substantial computational resources.
Tabby Architecture and Training Techniques
To overcome these challenges, Tabby introduces a MoE-based modification to standard transformers, enhancing their adaptability to tabular synthesis. Key components include:
- Tabby Architecture: MoE layers assign dedicated blocks per column, boosting expressivity and allowing finer modeling of column-specific distributions. The primary focus is on the language modeling head (Tabby Multi-Head, MH), enhancing its ability to synthesize structured data.
- Plain Training Technique: A straightforward yet impactful training method that formats data into an easily interpretable sequence for LLMs, enabling effective encoding of tabular information without imposing additional computational demands during training.
- Tabby Multi-Head (Figure 1): The combination of MoE at the LM head leads to superior handling of tabular nuances compared to non-Tabby models, as shown in the architectural comparison.
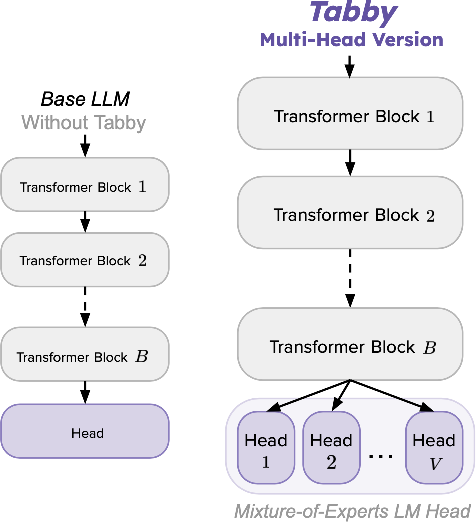
Figure 1: Tabby Multi-Head modifications (right side) compared to an original, Non-Tabby LLM on the left.
Performance comparisons using MLE highlight Tabby's proficiency in generating realistic synthetic datasets with fidelity comparable to real data. The primary metric, MLE, evaluates synthetic data quality based on the downstream model's predictive success, offering insights into the generative model's competence.
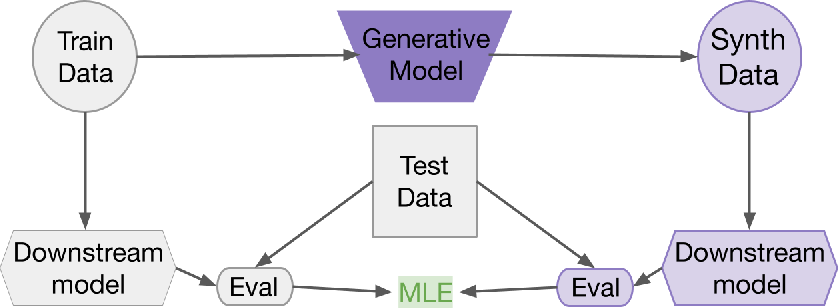
Figure 2: Process for calculating our primary metric, Machine Learning Efficacy (MLE). We train a generative model, which produces a synthetic dataset. Two downstream classifiers are trained: one on the generative model's training data and the other on the synthetic data. Each downstream model is evaluated on real test data. MLE is the difference in downstream models' test-time performance. Higher scores indicate better-quality synthetic data.
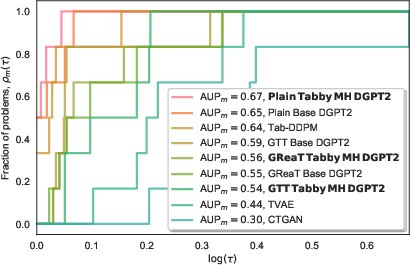
Figure 3: Performance profile curves and AUP scores across computed using the MLE scores on our evaluation tasks. The top performing method is Tabby MH DGPT2 with plain training.
Extending Tabby: Application to Nested Data
The flexibility of the Tabby architecture extends its utility beyond simple tabular data. The paper demonstrates Tabby's potential in synthesizing structured nested modalities, like JSON datasets, using recursive application of MoE layers. This adaptability signifies Tabby's robustness across diverse types of structured datasets.
Computational Requirements and Scaling
Tabby's implementation remains computationally feasible and efficient, enabling deployment on various LLM architectures without imposing significant resource demands. Experiments confirm that even smaller models equipped with Tabby modifications outperform larger non-Tabby models, suggesting that Tabby enhances learning effectiveness irrespective of model size.
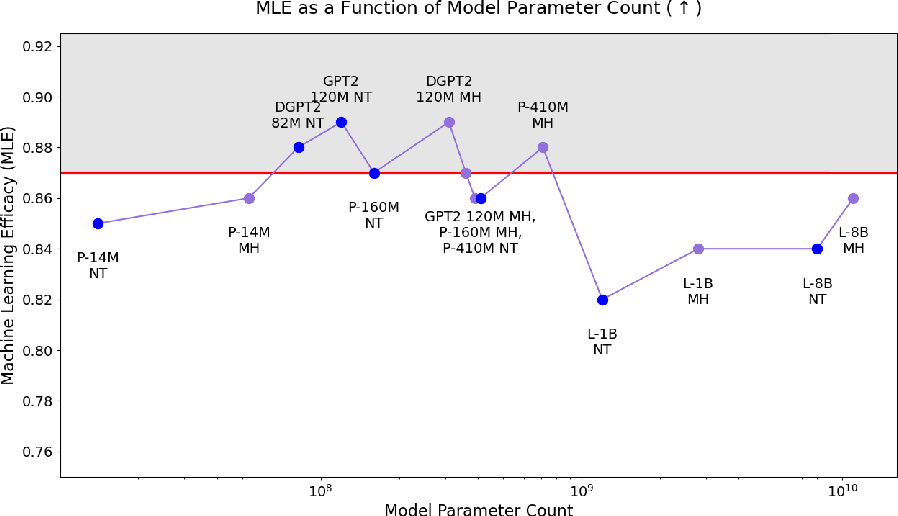
Figure 4: Machine Learning Efficacy (MLE) as a function of parameter count for 7 base LLMs, using Non-Tabby or Tabby MH architectures. Non-Tabby points displayed in blue; MH points in purple. Red line represents Original, upper-bound performance.
Implications and Future Directions
The introduction of Tabby paves the way for developing LTM-like architectures capable of synthesizing complex tabular and structured data. Potential research directions include refining the MoE layer designs, exploring parameter sharing for scalability, and extending the scope to novel structured data types.
Conclusion
Tabby exemplifies cutting-edge advancements in tabular data synthesis through intelligent use of MoE layers coupled with simplistic yet effective training methodologies. Its innovations promise to elevate the quality and realism of synthetic datasets, yielding substantial improvements over prior methodologies. This work underscores the importance of refining LLM architectures to exploit their full potential in diverse data synthesis scenarios.