- The paper introduces Audio-Reasoner, which enhances reasoning in audio models using a structured chain-of-thought methodology and the novel CoTA dataset.
- It employs a multimodal approach by integrating audio signals and textual queries to generate logical, step-by-step responses that improve interpretability and reduce hallucinations.
- Experimental results demonstrate significant improvements, including a +25.4% gain in MMAU-mini and a +14.6% increase in AIR-Bench chat performance.
Audio-Reasoner: Enhancing Reasoning in Large Audio LLMs
Introduction
The paper introduces Audio-Reasoner, designed to improve the reasoning capabilities of Large Audio LLMs (LALMs) by leveraging structured chain-of-thought reasoning and inference scaling principles. The need for such advancements becomes apparent due to the underexplored nature of reasoning in audio modalities, as compared to other modalities like vision and text.
Recent efforts in multimodal LLMs, such as LLaVA-Reasoner, have shown success in cross-modal reasoning tasks but often fail to incorporate complex reasoning frameworks in the audio domain. The authors address this gap by introducing CoTA, a high-quality reasoning dataset that contains 1.2 million samples spanning sound, speech, and music tasks, aiming to provide deep learning models the structured data required for developing sophisticated reasoning abilities.
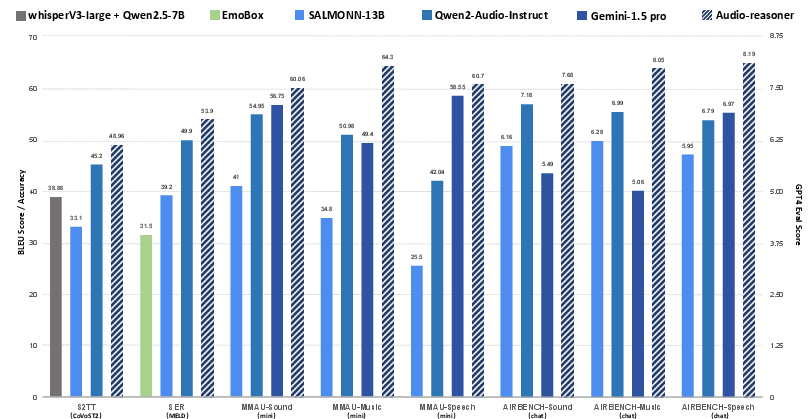
Figure 1: Benchmark performance of Audio-Reasoner on tasks of speech emotion recognition (SER), speech-to-text translation (S2TT), MMAU, and AIR-Bench chat. S2TT is measured using BLEU while SER and MMAU are measured ACC (left axis). AIR-Bench is scored by GPT (right axis).
Audio-Reasoner Model
Audio-Reasoner is trained to generate structured outputs that consist of both reasoning chains and concise final answers. The model's architecture leverages a multimodal input representation consisting of an audio signal and a textual query, allowing it to perform chain-of-thought reasoning and contextual analysis. The structured steps include planning, captioning, reasoning, and summarization, which ensure logical coherence and accuracy in generated responses.
The training focuses on maximizing the joint likelihood of the reasoning chain and the final response, optimizing the model to articulate the logical process before delivering a structured output. This approach significantly enhances interpretability and reduces instances of hallucination commonly observed in audio models that lack such structuring.

Figure 2: Comparison between Audio-Reasoner and Qwen2-Audio-Instruct: While Qwen2-Audio-Instruct produces brief and error-prone reasoning, our Audio-Reasoner uses a structured reasoning framework with distinct "thinking" and "response" phases, ensuring a more reliable and well-supported output through careful planning, information extraction, and step-by-step reasoning.
CoTA: Dataset and Pipeline
The CoTA dataset is meticulously constructed through a three-stage process: automated annotation, structured reasoning chain construction, and rigorous validation. Each stage ensures that audio data is transformed into diversified reasoning tasks, enhancing the capability of LALMs to handle complex audio-based queries. These tasks cover a spectrum of domains, including sound and speech question answering (QA), speaker emotion recognition, and music QA.

Figure 3: Multistage data generation pipeline.
Experimental Results
Audio-Reasoner demonstrates superior performance across multiple benchmarks, surpassing state-of-the-art models like Qwen2-Audio-Instruct and Gemini-1.5-Pro in MMAU-mini and AIR-Bench chat/foundation tasks. It achieves a significant +25.4% improvement in MMAU-mini, +14.6% gains in AIR-Bench chat, and +30.6% enhancement in CoVoST2, validating its competencies in structured reasoning and inference scaling.
Audio-Reasoner's outperformance is attributed to the depth of reasoning enabled by the CoTA dataset, which provides intricately detailed annotations and questions, allowing proficient handling of complex multimodal interactions.
Case Study
A detailed case study illustrates Audio-Reasoner's prowess in handling multi-turn dialogue tasks, showcasing its ability to identify speaker roles and comprehensively analyze multi-faceted audio inputs. The structured approach ensures that outputs are logically sound and contextually relevant, setting a new standard in audio reasoning tasks.

Figure 4: Example of Audio-Reasoner answering music-based question.
Conclusion
Audio-Reasoner represents a significant advance in the field of audio language modeling, demonstrating that structured chain-of-thought methodologies can drastically improve reasoning capabilities in LALMs. The CoTA dataset plays a pivotal role in this achievement, offering a complex and comprehensive training ground for models. Future work may involve expanding reasoning models to support multi-turn dialogue and cross-modal understanding, potentially leading to more robust applications in AI-driven speech systems. Evolution in this field continues to underscore the importance of structured reasoning frameworks and high-quality annotation in the training of cognitive AI models.