- The paper introduces a token-level optimization framework integrating DPO rewards into RLHF, enabling adaptive policy distillation for LLM alignment.
- It employs contrastive DPO rewards and adaptive logit extrapolation to balance token contributions and enhance convergence speed.
- Experimental results on benchmarks like AlpacaEval 2.0 show superior alignment quality and training efficiency over conventional methods.
AlignDistil: Token-Level LLM Alignment as Adaptive Policy Distillation
AlignDistil presents a novel approach to LLM alignment, focusing on token-level optimization through adaptive policy distillation. This essay examines the method's formulation, theoretical underpinnings, experimental validation, and implications for future advancements in LLM training.
Introduction
The alignment of LLMs with human preferences is a fundamental challenge in AI, traditionally approached through Reinforcement Learning from Human Feedback (RLHF) and Direct Preference Optimization (DPO). These methods typically operate at a response level, applying feedback sparsely and thereby potentially misaligning individual token contributions. AlignDistil addresses this by introducing a token-level optimization framework that derives from RLHF but employs a distillation process equivalent to reinforcement learning, thus enhancing performance and convergence speed.
Methodology
AlignDistil Framework: The core innovation of AlignDistil lies in its integration of DPO-derived rewards into the RLHF framework, establishing a novel token-level distillation objective. The approach involves combining logit outputs from both DPO and reference models to form an adaptive teacher distribution guiding policy updates.
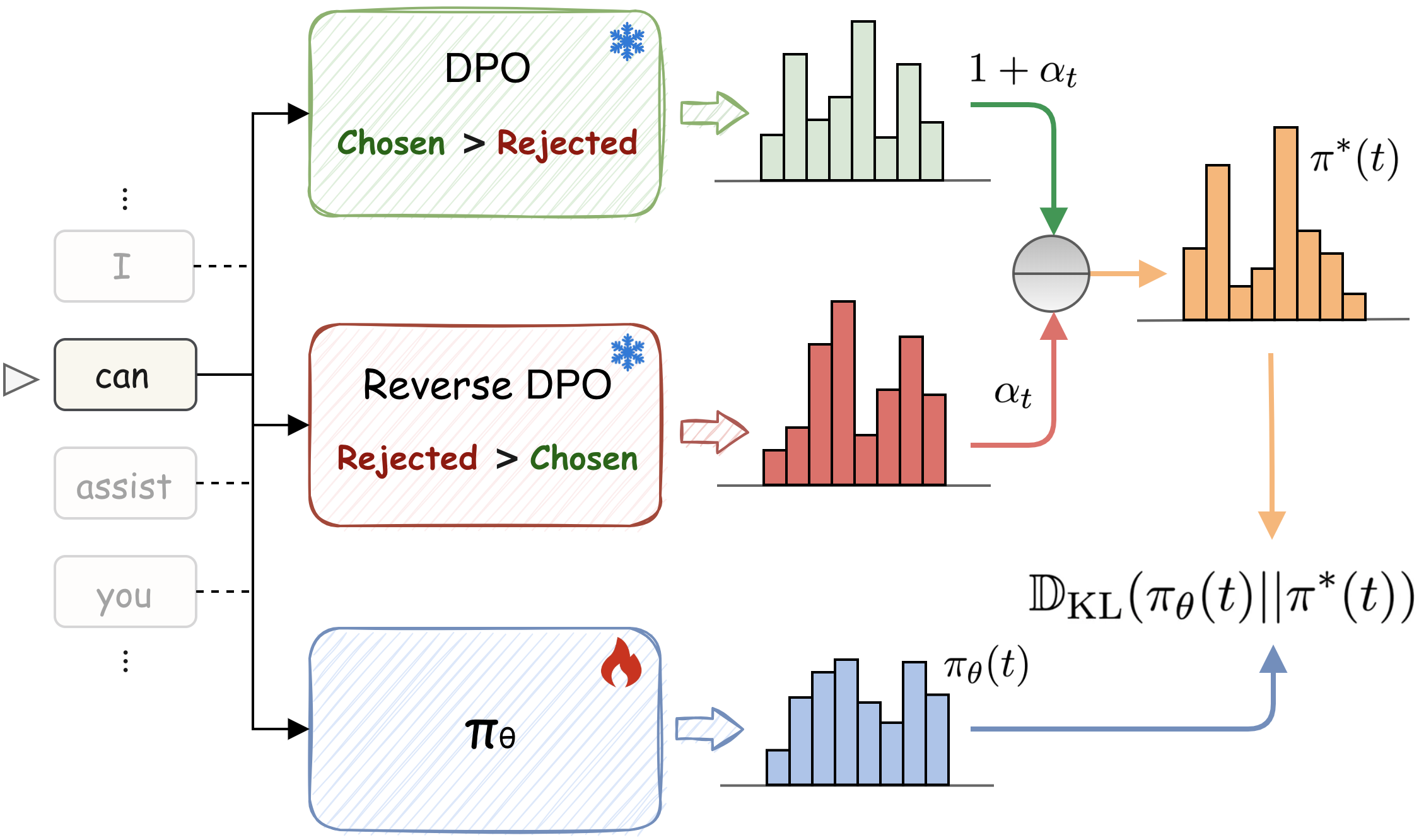
Figure 1: An overview of our AlignDistil. At token position t, the distribution from the current policy πθ is guided by a teacher distribution π∗, which is constructed from an adaptive extrapolation between logit distributions from a DPO model and a reverse DPO model with a weight αt.
Theoretical Foundation: AlignDistil posits a theoretical equivalence between RLHF objectives and a distillation process characterized by token-level guidance. By employing DPO rewards, the method decomposes the conventional RLHF sequence-level objective into a more granular token-level optimization framework.
Contrastive DPO Reward: A significant enhancement is the use of contrastive DPO rewards, incorporating both normal and reverse DPO models to establish a reward model that is more robust and discriminative, particularly beneficial for capturing nuances in low-quality data.
Token Adaptive Logit Extrapolation: To prevent under- or over-optimization across tokens, AlignDistil introduces a mechanism for adaptive logit extrapolation. This involves adjusting the contribution of different token positions based on total variation distance, thereby tailoring the strength of guidance across tokens.
Experimental Results
AlignDistil was evaluated against standard benchmarks such as AlpacaEval 2.0, MT-Bench, and Arena-Hard, demonstrating superior performance in both alignment quality and convergence speed compared to baseline methods. The experiments confirmed that token-level distributional reward optimization markedly improves both efficiency and effectiveness in LLM alignment.
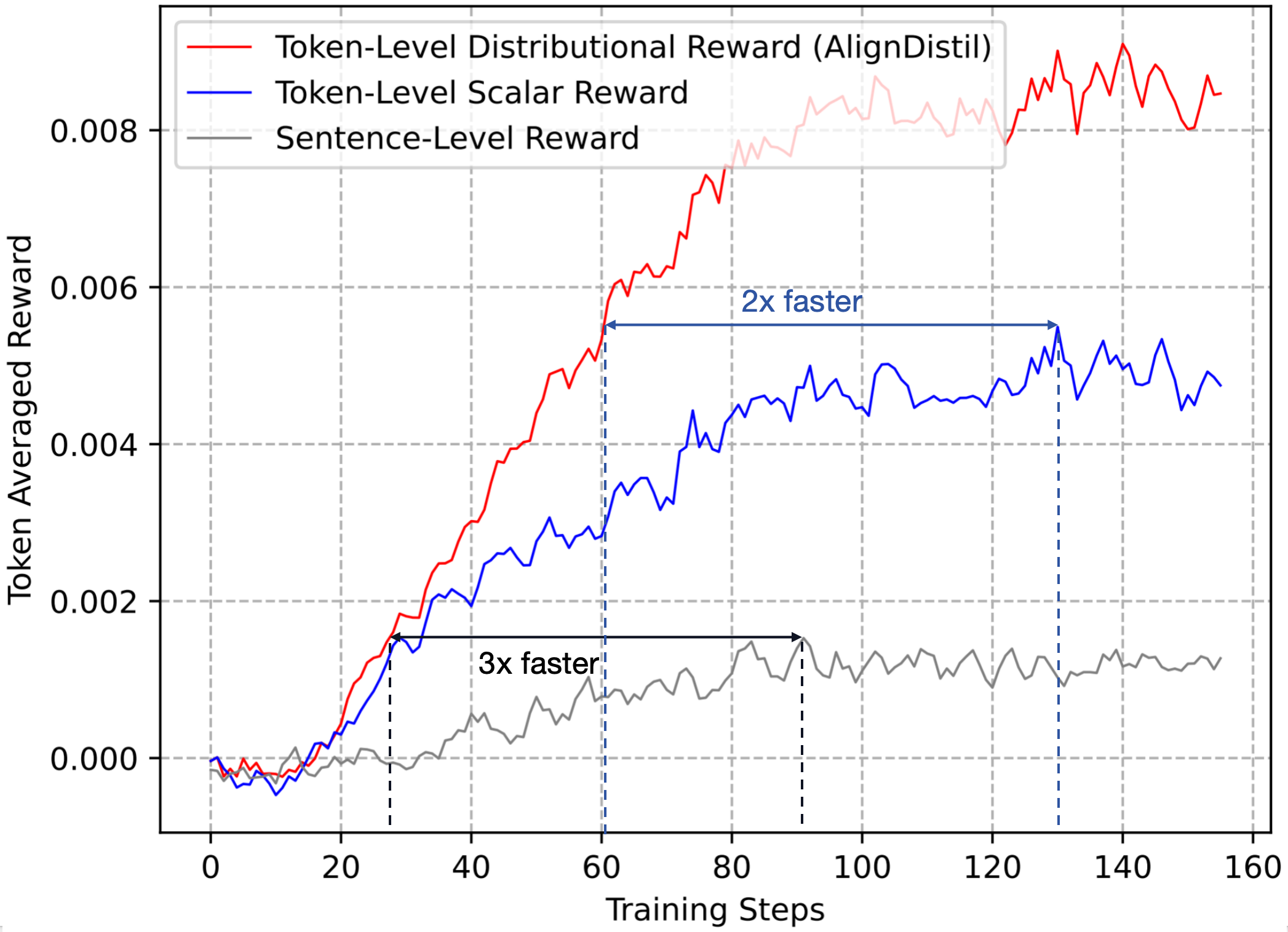
Figure 2: Convergence curves of token averaged reward from optimization on the sentence-level, token-level scalar-type, and token-level distributional reward.
Implications and Future Directions
AlignDistil's approach offers significant improvements in the granularity and speed of LLM alignment processes. By leveraging token-level optimization, it opens new pathways for more nuanced and effective model training strategies. Future research could explore the scalability of this approach to larger models and diverse linguistic tasks, potentially examining its efficacy in real-time beta-testing environments and its adaptability to emerging LLM architectures.
Conclusion
AlignDistil provides a theoretically sound, empirically validated framework for enhancing LLM alignment by focusing on token-level optimization. Its integration of DPO rewards and innovative distillation mechanisms marks a significant advancement in the development of AI systems that better align with human preferences, promising enhanced performance in both research and applied settings. This advancement illustrates a paradigm shift towards more precise and efficient alignment methodologies in AI research.