- The paper presents Behavior Shaping (BS), a reinforcement learning paradigm that integrates human-conditioned control to improve both task performance and subjective satisfaction.
- Experiments in Overcooked-AI environments show BS outperforms traditional self-play methods in both joint scores and partner preference metrics.
- The study emphasizes that explicit user control of AI behavior enhances predictability and enjoyment, driving a paradigm shift in human-AI teaming evaluation.
Introduction
The study "Controllable Complementarity: Subjective Preferences in Human-AI Collaboration" investigates the premise that human-AI teaming should optimize not only for objective team performance but also for subjective human experience. The authors argue that conventional human-AI teaming (HAT) frameworks, with their emphasis on performance metrics, inadequately capture what humans value in AI partners, particularly the aspects of controllability and subjective satisfaction. This work introduces Behavior Shaping (BS), a reinforcement learning (RL) paradigm enabling explicit human-conditioned control over AI policy behavior, as a solution to bridge this gap.
Methodological Framework: Behavior Shaping for Controllable AI Partners
BS extends the conventional Dec-POMDP formulation by conditioning the AI policy not only on environmental observations but also on a vector of interpretable behavioral reward weights, ω, corresponding to auxiliary and human-meaningful reward functions Ψi. The BS training pipeline involves random sampling of these weights during RL training, producing a single conditional policy capable of expressing diverse, distinctly parameterized behaviors on demand.
This method contrasts with typical multi-agent RL (MARL) approaches such as Population-Play, Fictitious Co-Play, and Any-Play, which require training or maintaining diverse agent populations to achieve robust zero-shot coordination. BS achieves behavioral diversity and post hoc controllability with a single model, reducing system complexity and enabling real-time human manipulation of AI partner behavior.
Experimental Setup and Implementation
Experiments were conducted exclusively in the Overcooked-AI co-grid environment (reimplemented as CoGrid), comprising five canonical layouts requiring nuanced coordination (Figure 1). Each Overcooked agent (AI or human) assumes the role of a chef with full action sets; policy gradients are optimized using Proximal Policy Optimization (PPO).





Figure 1: Cramped Room, one of the canonical Overcooked-AI environments requiring tight spatial coordination.
For BS, the policy is jointly conditioned on observation and three interpretable weights: delivery-act reward, onion-in-pot reward, and plating reward. Weights ω are sampled i.i.d. from N(0,1) per episode in training, then discretized during human studies as "Encourage" (+1), "Neutral" (0), "Discourage" (–1). Several hundred million steps of RL were used for both self-play (SP) and BS agent training, with hyperparameters fixed across conditions for comparability.
Experiment 1: BS Versus Self-Play for Zero-Shot Human-AI Coordination
Experiment 1 evaluates whether the BS training protocol produces objectively superior and more subjectively preferred agents than the standard SP baseline. In a within-subjects design, 59 participants played alternating rounds with SP and BS agents (with ω=0 for fairness on human trials).
Results demonstrate that, across all but one Overcooked layout, human–BS teams achieve significantly higher joint scores than human–SP teams (p < 0.01 or p < 0.001 where marked as significant). Subjective partner preference measures exhibit a parallel trend: users overwhelmingly prefer BS over SP partners (Figure 2).
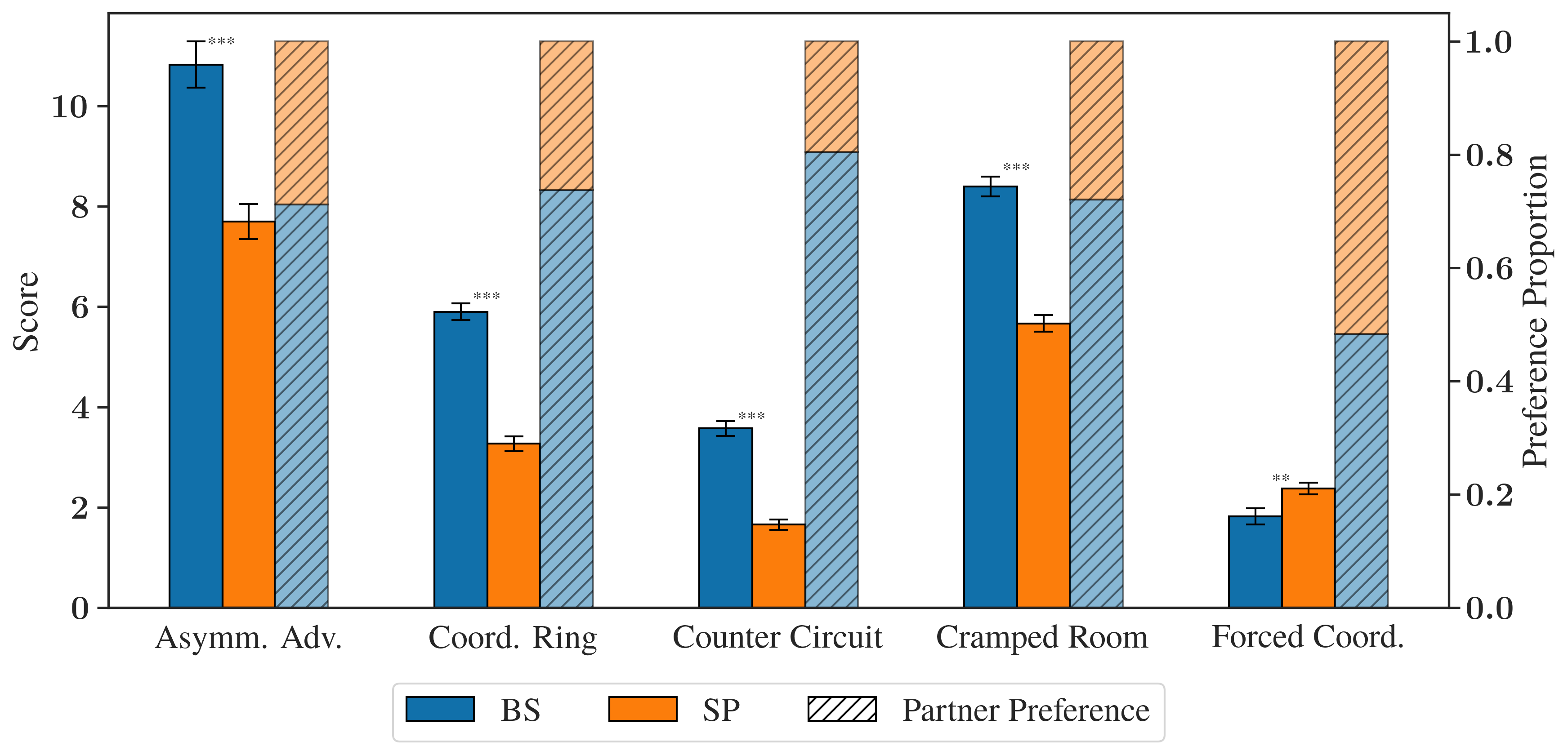
Figure 2: Average team score and human partner preference proportion by environment and AI partner type. Significant improvements for BS over SP in both quantitative and choice metrics.
The lone exception, Forced Coordination, illustrates an impactful limitation: when behavioral shaping does not modulate key task bottlenecks (i.e., one chef must perform nearly all actions, making partner diversity less meaningful), BS does not confer a tangible advantage.
Experiment 2 exposes the ω controls directly to users and measures their effect on subjective experience, using three conditions:
- Controllable: User sets and sees ω; policy follows these settings.
- Fixed: ω is fixed and visible but unchangeable.
- Hidden: ω is fixed and hidden.
Systematic manipulation and counterbalancing across 116 participants assess perceived predictability, effectiveness, and enjoyability—alongside objective performance—controlling for layout and skills.
Strong statistical evidence indicates participants consistently rate the controllable partner higher on subjective metrics than both fixed and hidden-setting partners, even when performance is matched. Users show a robust behavioral preference for the controllable agent when given a choice, with the controllable partner selected the majority of the time across all layouts (Figure 3).
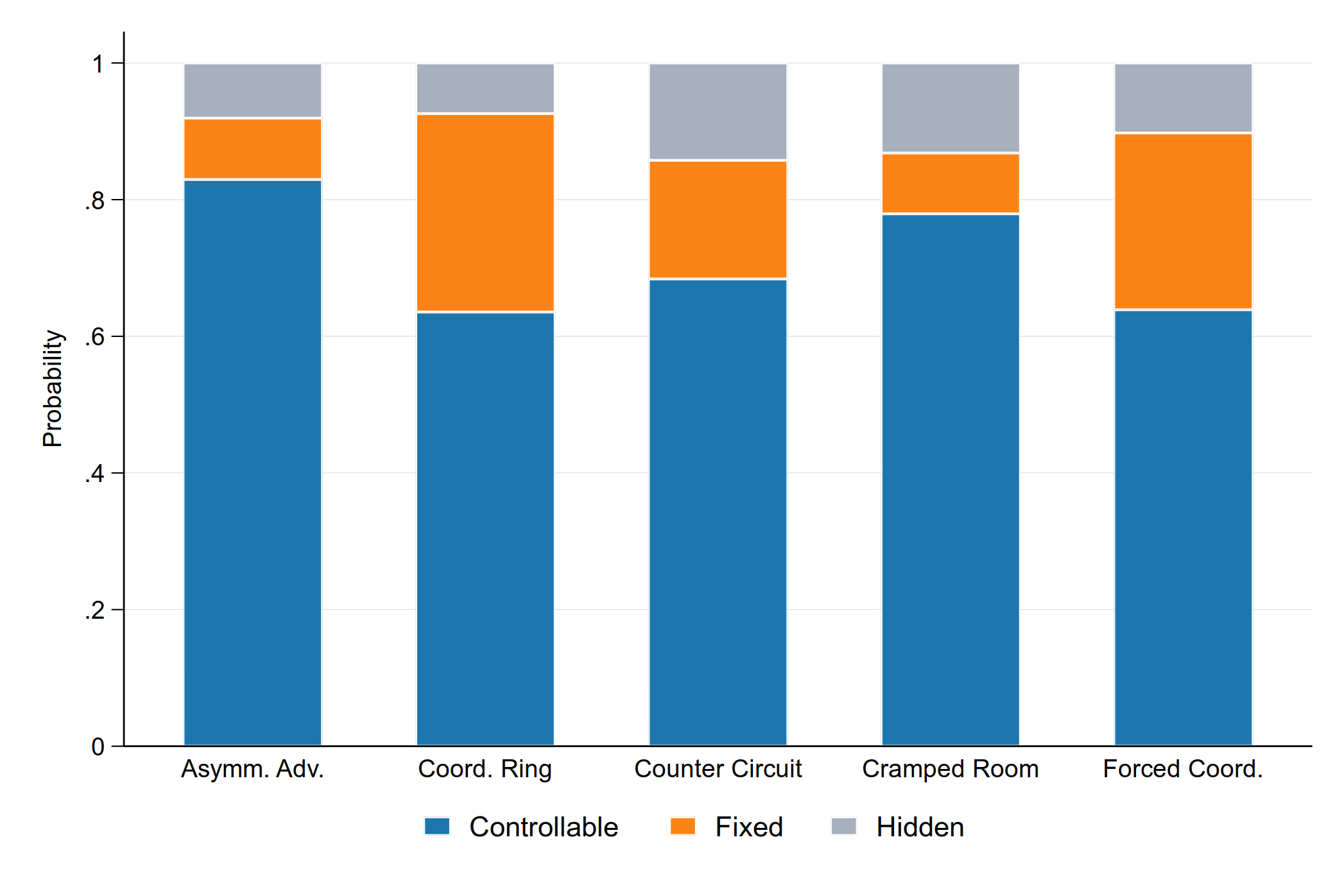
Figure 3: Multinomial logistic regression-predicted probabilities of interacting with a controllable, fixed, or hidden partner demonstrate a clear preference for control across layouts.
Key moderation effects are observed: the subjective value of control is amplified or diminished according to the degree of compliance the AI partner exhibits with the user-defined settings. Deviation from these control signals significantly reduces enjoyment and perceived effectiveness in the controllable condition, even without affecting scores.
Alignment Between Subjective Preferences and Weight Selection
The analysis of participants' chosen ω values during the final free-choice phase reveals that humans sometimes sacrifice maximum expected reward to elicit more predictable, deterministic behaviors. Layouts that support division of labor (e.g., Asymmetric Advantages) reveal a strong bias for settings that encourage a single behavior (+1/–1) and suppress others, despite more balanced or random policies yielding higher potential scores (Figure 4).
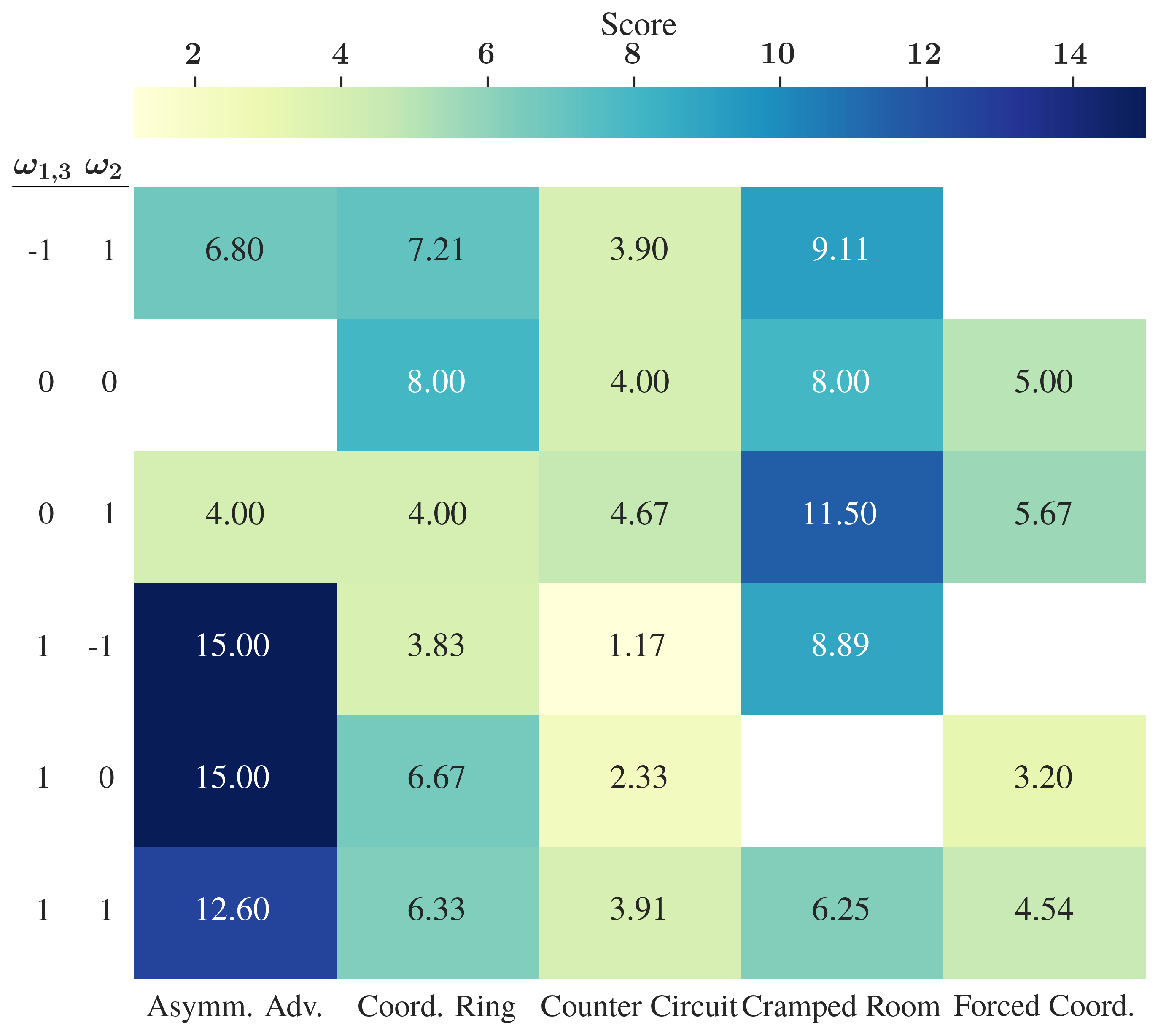
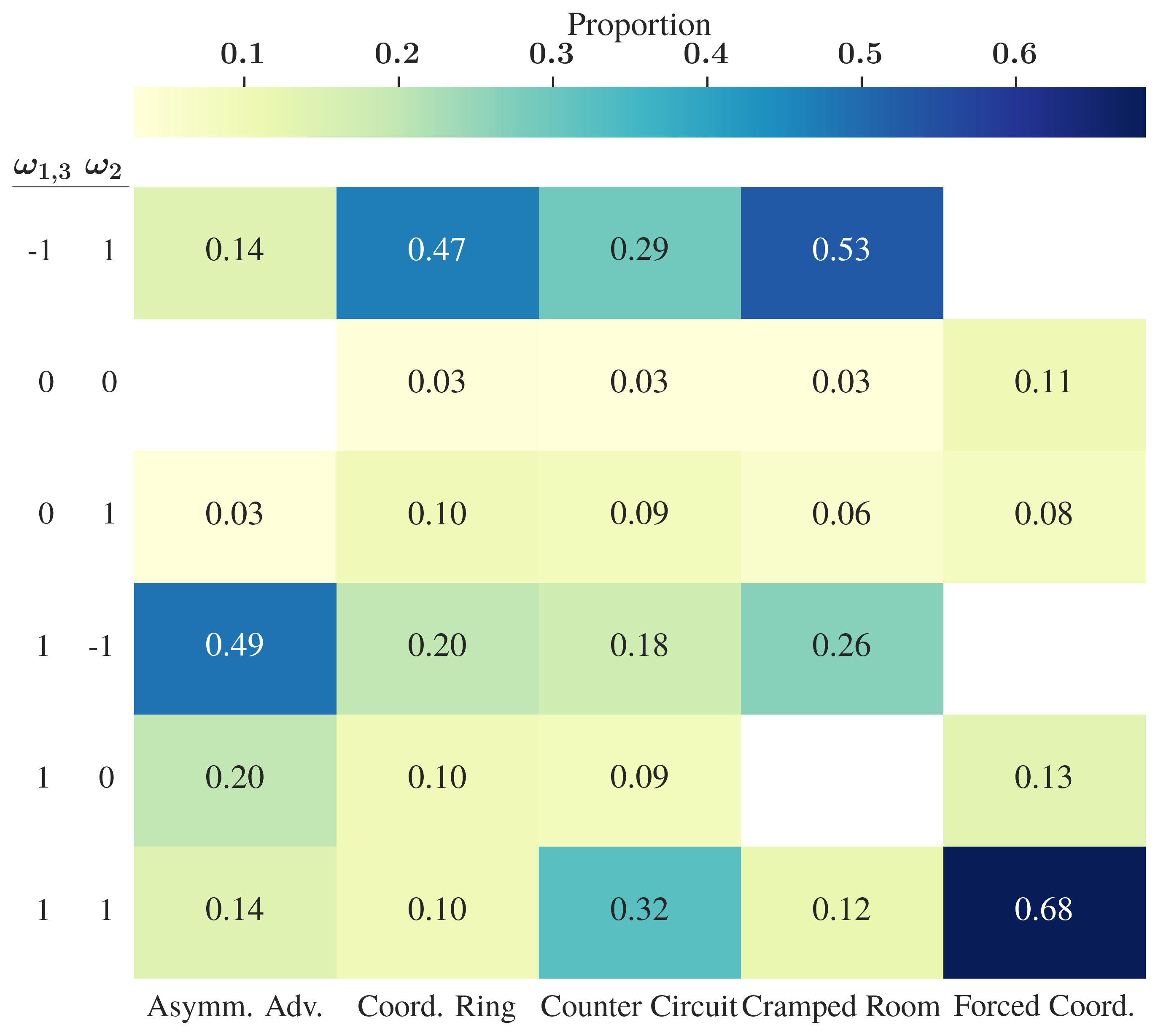
Figure 4: Mean Overcooked joint score by environment and ω weight combination, capturing the trade-off between predictability and objective reward.
Such findings indicate human preferences for predictability may trump reward maximization when the agent’s behavior is under explicit user control.
Implications and Future Directions
This work operationalizes a more inclusive metric for human-AI complementarity, advocating for the optimization of subjective human preferences (especially for control and predictability) alongside classical team performance. The BS framework enables rapid adaptation to human needs in dynamic, collaborative tasks, uniquely enabling explicit, user-facing behavioral control of AI partners.
Engineering Implications
- Efficiency: Single-conditional-policy models reduce computational and memory overhead for robust, user-configurable partners compared to population-based or ensemble approaches.
- Deployment Practicality: Real-time, user-facing behavioral modulation enables better human-in-the-loop experiences and customization in real-world applications.
- Reward Engineering: Defining interpretable and effective behavioral control dimensions is both critical and context-dependent. Poorly chosen shaping signals can dilute the benefits (as visible in environments where no actionable diversity exists).
Limitations
- Reward Misspecification: If behavior dimensions are not carefully selected for the task structure, controllability may have no practical effect (e.g., Forced Coordination).
- Behavioral Interpretability: Control over neural policies is limited to hand-chosen, preconditioned behavioral axes; extension to richer, perhaps natural-language–driven shaping remains an open engineering challenge.
Theoretical Consequences
- Redefinition of Teamwork: This approach strengthens the argument that the value of human-AI teams must be assessed on more than conventional outcome or efficiency metrics. Subjective utility—including the experience of agency and satisfaction—must be considered integral to the success of AI deployment in collaborative settings.
Broader Applicability
Further investigation is warranted into domain transferability (e.g., outside Overcooked), scaling to multi-agent tasks, and using learned or data-driven shaping dimensions (potentially via LLM-based reward models for behavioral traits, cf. [kwon2023reward]).
Conclusion
The introduction of Behavior Shaping and rigorous experimental evaluation demonstrate that controllable, robust AI policies can deliver superior objective performance and—critically—improved user satisfaction and partner preference when explicit control is provided. These findings motivate a paradigm shift in HAT system objectives, broadening evaluative criteria to include subjective human needs and expectations, ultimately shaping the next generation of collaborative AI systems that prioritize both task efficacy and human experience.