- The paper introduces PointVLA, a framework that injects 3D point cloud data into pre-trained VLA models via a modular, lightweight adapter without retraining the entire network.
- It leverages skip block analysis to strategically inject 3D features into later layers of the action expert, ensuring improved few-shot learning and long-horizon task execution.
- Experimental results demonstrate that PointVLA outperforms 2D-only and naive 3D methods in tasks like bimanual manipulation, safety-critical disambiguation, and adaptability to environmental changes.
PointVLA: Injecting 3D Perception into Vision-Language-Action Models
Introduction
The PointVLA framework addresses a fundamental limitation in the deployment of Vision-Language-Action (VLA) models for robotics: their reliance on 2D visual inputs, which impedes comprehensive spatial reasoning and robust physical object interaction. Existing VLA models, extensively pre-trained on large-scale 2D vision-language data, cannot be efficiently retrained with limited 3D data due to resource constraints, and discarding legacy data is economically impractical. PointVLA provides a solution that integrates sparse 3D point cloud data into these pre-trained VLA architectures without costly retraining or catastrophic forgetting, ultimately advancing the model's ability to reason about and manipulate the physical world.
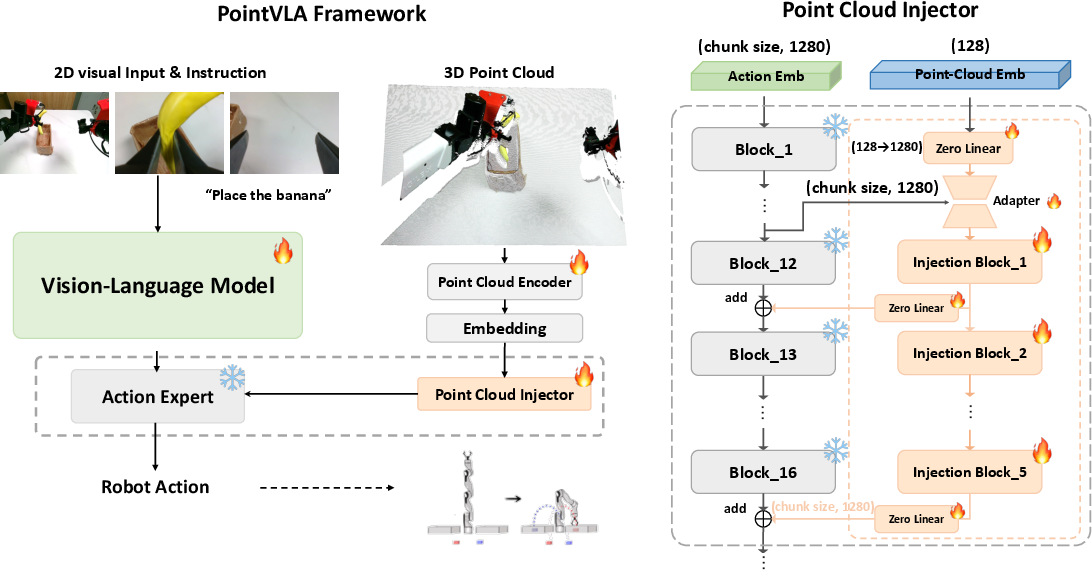
Figure 1: PointVLA architecture—2D image and language instructions are processed by a fixed VLM; the action expert receives 3D point cloud features injected via a modular network.
Methodology
PointVLA augments a pre-trained VLA with a lightweight point cloud injector that selectively integrates 3D features into the action expert while leaving the vision-language backbone frozen. The design is governed by key practical constraints: the volume of available 3D data is orders of magnitude less than 2D data, and preserving pre-trained 2D representations is essential. Instead of the naive approach of fine-tuning the VLM or integrating 3D tokens directly (which is data inefficient and risks overfitting), PointVLA adopts a modular block that injects 3D information only at targeted layers of the action expert.
The point cloud encoder employs a shallow, hierarchical convolutional design, following evidence that over-parameterizing the 3D branch results in negative transfer. Injected features enter the action expert through an additive adapter, but only in specific layers identified via skip block analysis.
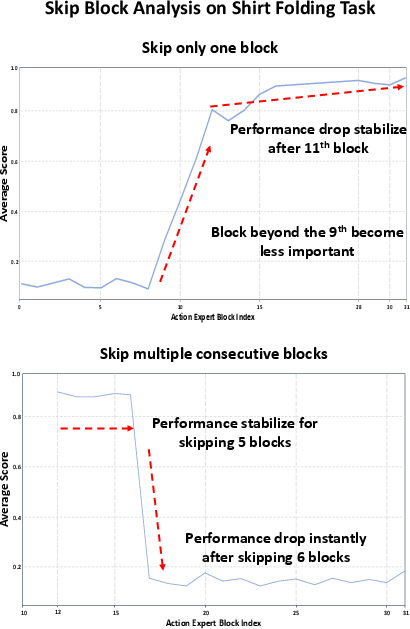
Figure 2: Empirical skip block analysis reveals that blocks beyond the 11th in the action expert are less critical and can be used for 3D feature injection without sacrificing performance.
Skip block analysis on the action expert (e.g., a ScaleDP-style diffusion transformer with 32 blocks) shows that only the final ~20 layers are amenable to such modifications—skipping early layers damages task performance, but inserting 3D features in later blocks is low-risk. This architectural insight ensures that 3D information augments spatial reasoning while minimizing interference with pre-existing 2D-induced representations. The final model thus consists of the frozen action expert, five trainable 3D conditioning blocks, and adjustable output heads.
Experimental Validation
Few-Shot Multi-Task Generalization
On bimanual AgileX robots, PointVLA outperforms 2D-only and conventional 3D baselines on four distinct few-shot tasks (ChargePhone, WipePlate, PlaceBread, TransportFruit) using only 20 demonstrations per task. Where the pure Diffusion Policy and up-scaled ScaleDP-1B fail due to limited sample coverage and entanglement in action representations, PointVLA exhibits sample-efficient adaptation and robust generalization.
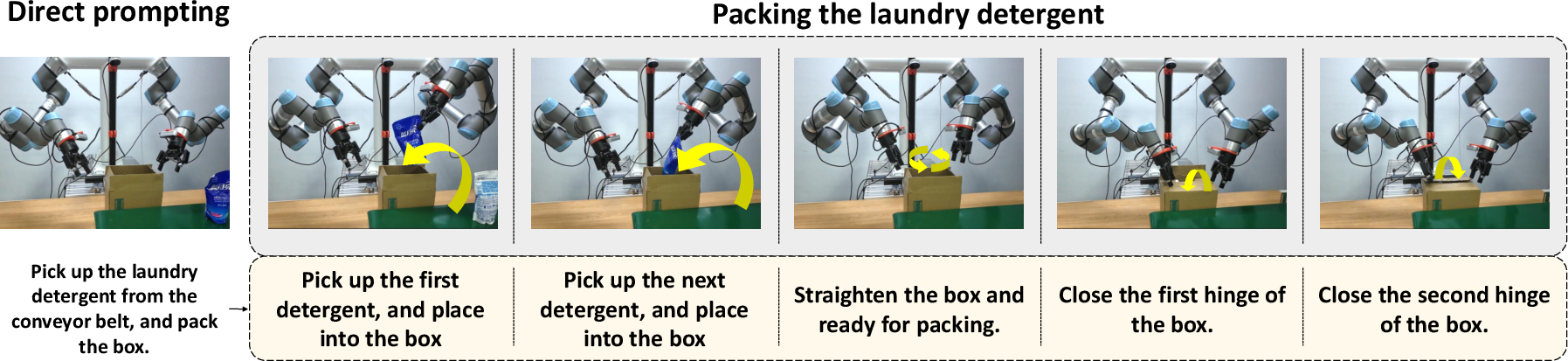
Figure 3: Experimental setup for bimanual UR5e with three-camera system performing a long-horizon picking and packing task.

Figure 4: Few-shot multi-task setup on AgileX arms; environment and tasks are highly variable with minimal data.
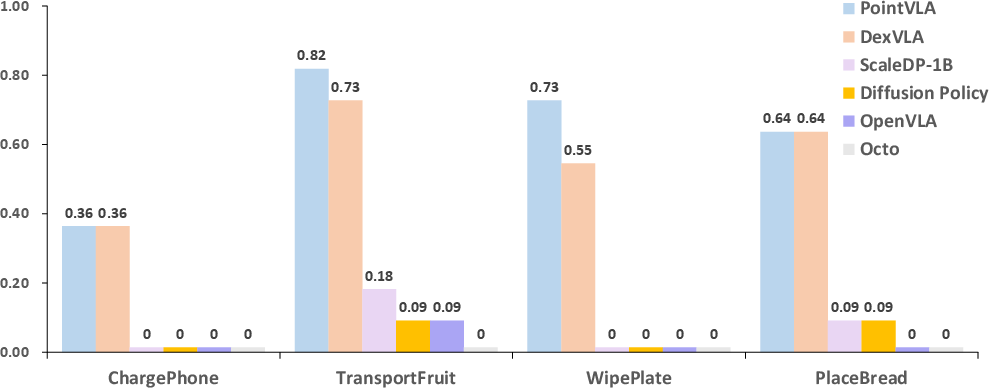
Figure 5: Head-to-head multi-task performance—PointVLA yields superior average success rates under limited demonstration regimes.
Long-Horizon Tasks
In a real-world dynamic packing task on a dual-arm UR5e system with three cameras, PointVLA demonstrates robust sequential manipulation, outperforming all 2D and pure-3D baselines in both average success length and generalization to new, unseen manipulation sequences. It achieves an average step completion length of 2.36 versus 1.72 for the strongest 2D VLA baseline, DexVLA.
Robustness: 3D-Aware Disambiguation and Height Adaptation
PointVLA excels in scenarios that expose the limitations of 2D-only models:
- Real-vs-Photo Discrimination: PointVLA identifies photo-based object decoys and avoids interaction, whereas 2D models hallucinate graspable objects, leading to repetitive failed attempts.
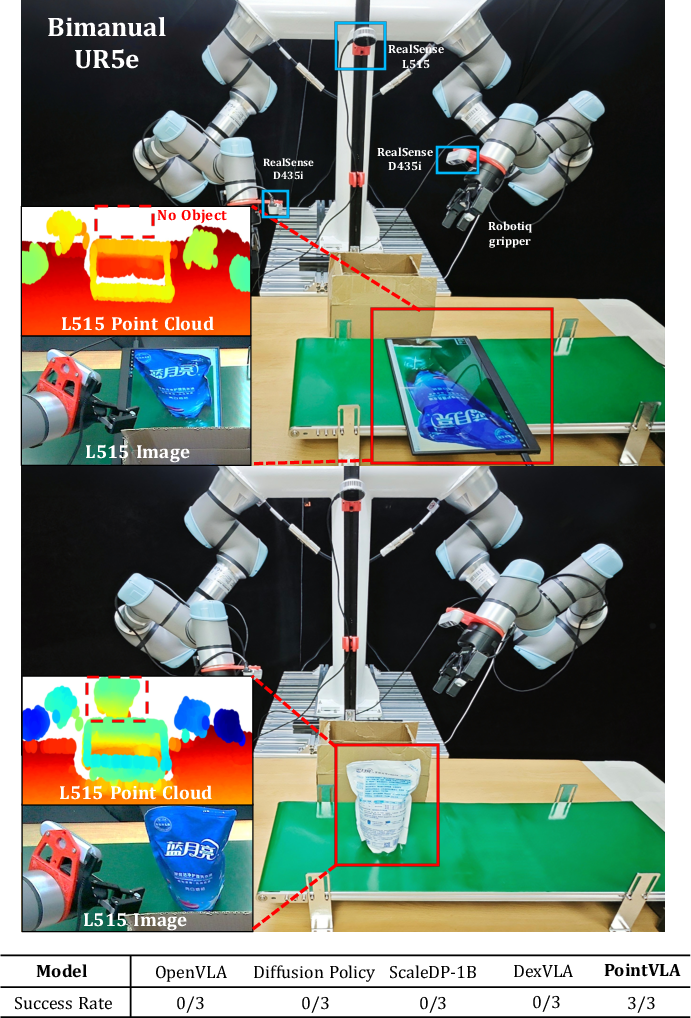
Figure 6: Setup and outcome for real-vs-photo discrimination; PointVLA reliably detects the absence of a real object using 3D cues.
- Height Adaptability: When deployed on tasks with substantial, unseen table height changes (e.g., an abrupt increase in supporting surface height), PointVLA adapts its gripper pose to successfully grasp objects. All 2D reference models fail, rigidly executing learned height trajectories and missing the object.

Figure 7: Height generalization—PointVLA adapts to varying table heights during deployment, in contrast to complete failure by 2D models.
Simulation Benchmarks
On the RoboTwin simulated platform, PointVLA achieves leading performance on a wide suite of bimanual manipulation tasks, both in the low-data (20 demos) and moderate-data (50 demos) regimes. It systematically outperforms Diffusion Policy, DP3 (3D Diffusion Policy), and more expensive fusion baselines that naïvely combine RGB and point cloud data. The data confirms that conditional, modular 3D feature injection is superior to direct stacking of heterogeneous modalities.
Implications
Practically, PointVLA establishes a scalable pathway for integrating novel sensory modalities into foundation robotic models. It preserves sample efficiency and avoids full retraining costs, directly benefiting industrial scenarios where available 3D sensor data is sparse or where legacy data must be reused. The framework provides critical safety robustness in adversarial or ambiguous settings (e.g., object decoys) and demonstrates adaptability in out-of-distribution deployment (e.g., environment geometry changes).
Theoretically, the skip block analysis provides a general method for modular extension of large-scale robots’ policies. PointVLA's approach could be generalized to other sensor modalities (e.g., multimodal haptics or audio), suggesting future directions in compositional and modular foundation models for embodied AI.
Conclusion
PointVLA represents a rigorous, modular augmentation of existing VLA pipelines for robotics, efficiently introducing 3D spatial reasoning via point cloud injection without retraining or performance degradation. Its strong numerical results in few-shot learning, long-horizon sequential tasks, and robust 3D generalization validate the design. The approach is architecturally simple, resource-efficient, and directly improves VLA models’ safety and reliability in real-world robotic manipulation (2503.07511).