- The paper presents novel token weighting methods that assign differential importance to tokens based on CPMI metrics.
- It introduces a two-step framework with token scoring and postprocessing, employing both sparse and dense weighting techniques.
- Empirical evaluations show that these approaches significantly improve long-context performance over uniform weighting.
Token Weighting for Long-Range Language Modeling
Introduction
The paper "Token Weighting for Long-Range Language Modeling" (2503.09202) presents novel methodologies targeting the enhancement of LLMs' (LLMs) capabilities in understanding long-range contexts. Acknowledging the challenges faced by LLMs in tasks necessitating extensive contextual comprehension, the study proposes various token-weighting schemes that assign differential importance to each token during training. These schemes aim to address the limitations of conventional uniform weighting in next-token prediction tasks, which can impede long-context comprehension by treating all tokens with equal significance.
Methodology
The authors introduce a two-step framework for token weighting comprising token scoring and postprocessing. The token scoring step evaluates the relative importance of tokens by comparing the confidence levels of a long-context model and a short-context model. This comparison is facilitated by the Conditional Pointwise Mutual Information (CPMI) metric, where the token scores are proportional to the absolute differences in confidence between these models.
In the postprocessing step, two main approaches are explored: sparse weighting and dense weighting. Sparse weighting involves setting a proportion of token scores to zero based on a specified sparsity ratio, while dense weighting normalizes scores to ensure all tokens contribute to the overall learning signal. The framework's flexibility permits the use of various short-context models, potentially smaller than the main model, to efficiently calculate token scores during training.
Experiments
Empirical evaluations were conducted using extended versions of the Llama-3 8B and Phi-2 2.7B models, expanding their context from 8k and 2k tokens, respectively, to 32k tokens. The study deploys these models on long-context tasks such as the RULER benchmark and Longbench, alongside evaluating their performance retention on shorter-context datasets like MMLU and BBH. The results underline the efficacy of non-uniform token weights in bolstering long-context performance, surpassing uniform weighting methods across several tasks.
Results
The research findings highlight that sparse weighting tends to excel in retrieval-intensive tasks due to its focused attention mechanism, whereas dense weighting provides a balanced improvement across various context lengths. Unfrozen sparse models particularly achieve superior results on synthetic tasks where long-range dependencies are paramount. Notably, frozen models that deploy pre-computed token scores offer competitive performance, albeit at the cost of increased initial computation effort.
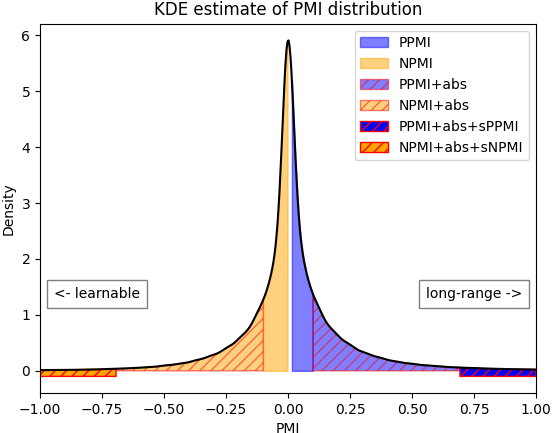
Figure 1: A kernel density estimate of the PMI distribution of all tokens in PG19-eval, measured with the uniform 32k model at the end of training.
Implications and Future Research
This study's insights into token weighting generalize and refine prior approaches by offering comprehensive guidelines for integrating token scoring into LLM training for enhanced context comprehension. The framework opens avenues for further exploration into analogous techniques that might incorporate additional context signals or alternative model architectures.
Moreover, while the paper concentrates predominantly on improving long-range model capabilities, future research might explore the interplay between token weighting strategies and other model components, such as attention mechanisms and positional encoding techniques. Understanding these interactions could further optimize model efficiency and effectiveness in processing extensive sequences.
Conclusion
This comprehensive investigation into token-weighting methodologies reveals significant potential for improving long-context understanding in LLMs. By employing various token scoring techniques and weighting distributions, the paper successfully demonstrates enhanced performance on tasks demanding nuanced context comprehension. These advances position token weighting as a promising direction for future model training frameworks aimed at overcoming the inherent challenges of long-range language modeling.