- The paper demonstrates that for L-smooth convex functions, gradient descent yields convex optimization curves when the step size is in the range (0, 1/L].
- It reveals that larger step sizes, specifically in (1.75/L, 2/L), can result in non-convex curves despite a monotonically decreasing objective function.
- The study extends these insights to continuous gradient flow, confirming convex curves and a steadily decreasing gradient norm, thus improving convergence interpretability.
Are Convex Optimization Curves Convex?
The paper "Are Convex Optimization Curves Convex?" (2503.10138) investigates the conditions under which optimization curves produced by gradient descent on convex functions are themselves convex. Although this problem seems straightforward, the answer is contingent upon the choice of step size.
Gradient Descent and Optimization Curves
Gradient descent is a widely-used optimization algorithm defined for a differentiable function f:Rn→R, starting at an initial point x0, with iterations given by xn=xn−1−η∇f(xn−1), where η>0 is the step size. The optimization curve is the linear interpolation of points {(n,f(xn))}, representing the path traced by the objective function values across iterations.
Convexity of the Optimization Curve
Main Result
The main finding of this paper is that for any L-smooth convex function, if the step size η is chosen in the range (0,L1], the optimization curve is indeed convex. This finding is surprising as it delineates conditions beyond mere monotonic convergence to an optimal value that assure the convexity of the curve.
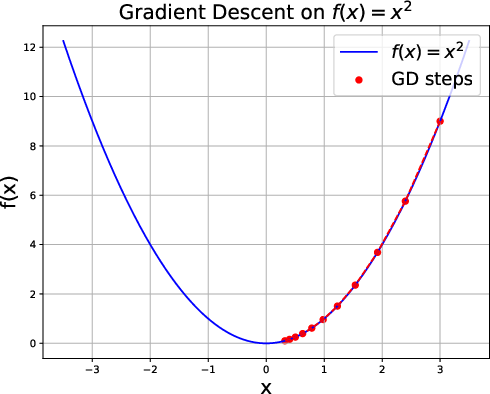
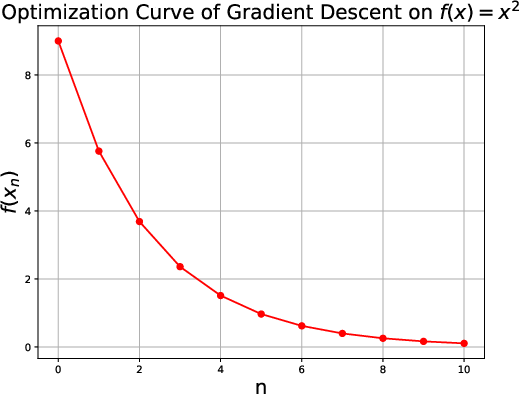
Figure 1: Gradient descent on f(x)=x2 with step-size η=0.1 and initial point x0=3.
Non-Convexity in Certain Regimes
For step sizes η within (L1.75,L2), the optimization curve can lose its convexity, even though the function values continue to decrease monotonically. This indicates the presence of multiple regimes in which gradient descent neither ensures convexity nor non-convexity independent of monotonicity over points.
Gradient Norms and Monotonic Decrease
Separately, the paper addresses whether the norm of gradients {∥∇f(xn)∥} decreases monotonically. It demonstrates that for L-smooth functions and for any η∈(0,L2], the sequence of gradient norms is always monotonically decreasing. This highlights a distinction between gradient norm monotonicity and optimization curve convexity.
Extension to Gradient Flow
The findings are extended to continuous gradient flow, conceptualized as the limit case of gradient descent as the step size approaches zero. Within this framework, the paper affirms that the optimization curve induced by gradient flow is always convex for smooth convex functions. Additionally, the gradient norms decrease continuously, assuring a smoother convergence trajectory without oscillations encountered in discrete settings.
Conclusion
The implications of this research provide insights into the behavior of gradient descent, emphasizing the influence of step size on the convexity of optimization curves. This offers practical guidance for selecting step sizes that maintain desirable curve properties and improve interpretability, which is critical in applications where interpretability of convergence behavior is crucial, such as real-time optimization settings or when early stopping criteria are dynamically adjusted.
Future investigations could explore whether the identified convexity regimes for discrete optimization become apparent in practical large-scale optimization problems or whether these conceptual benchmarks may guide the development of adaptive methods ensuring both convexity of curves and efficient convergence. The paper questions whether more general optimization settings or analogous properties for other algorithms might possess different behaviors or require alternate step-size considerations.