- The paper demonstrates that minimizing the NT-Xent loss without neural dynamics leads to trivial minimizers that fail to capture inherent data clustering.
- It uses variational analysis to expose the ill-posed nature of the SimCLR loss function and highlights why incorporating network optimization is essential.
- Results show that neural network-induced kernel dynamics promote effective clustering in the embedded space, underscoring the impact of architectural choices.
Understanding Contrastive Learning through Variational Analysis and Neural Network Optimization Perspectives
Introduction
The paper "Understanding Contrastive Learning through Variational Analysis and Neural Network Optimization Perspectives" aims to dissect the reasons behind the empirical success of the SimCLR method in contrastive learning. Despite SimCLR's effectiveness in creating useful visual representations across supervised, semi-supervised, and unsupervised tasks, its geometric success is not merely due to invariance. This paper addresses theoretical gaps by analyzing the SimCLR loss function and training dynamics under neural network parameterization. Highlighted are the insufficiencies of SimCLR's loss in selecting optimal minimizers and the necessity of considering neural dynamics to prevent failure.
Variational Analysis of SimCLR
One of the central claims of the paper is that minimizing the SimCLR loss function alone does not suffice for recovering meaningful structure in the data. Specifically, there is an inherent ill-posedness allowing trivial minimizers of the loss that do not preserve the clustering inherent to the original data distribution. The authors demonstrate that the NT-Xent loss can converge to arbitrary distributions, independent of the original data's manifold structure.
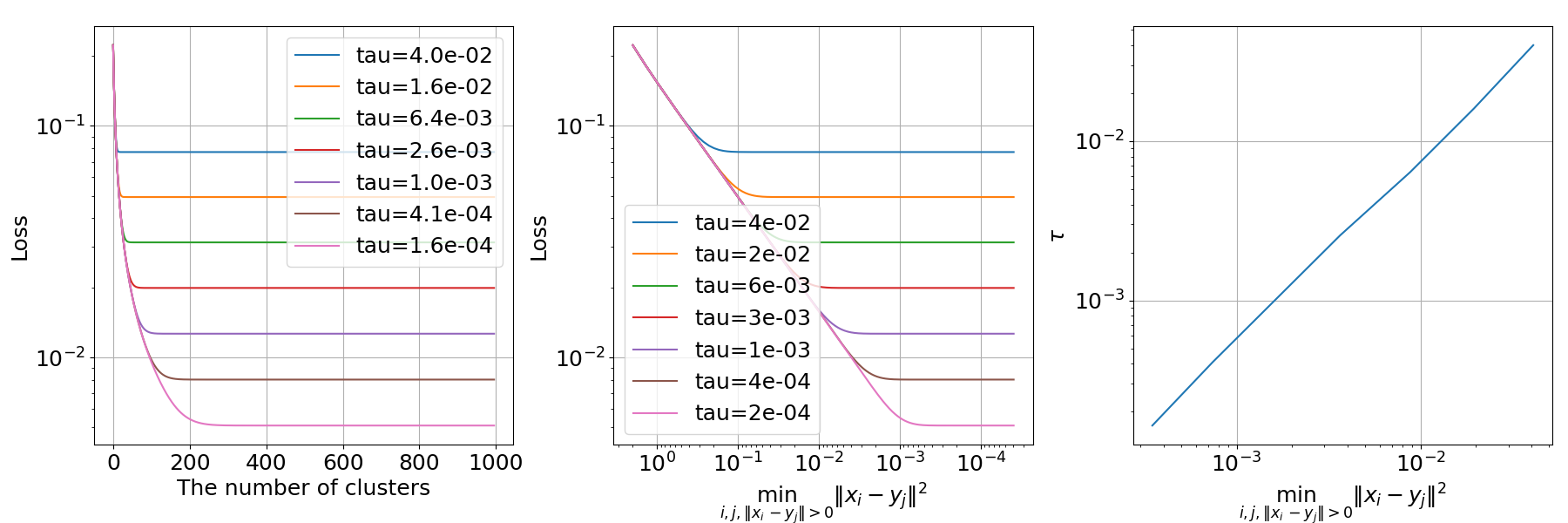
Figure 1: The NT-Xent loss for different embedded distributions f#μ, illustrating the independence from the underlying data distribution.
The authors explain how certain stationary points attained from minimizing this loss contribute to poor data representation outcomes if neural network dynamics are not incorporated into training.
Neural Network Optimization Dynamics
The next focus is understanding how neural network parameterization alters the optimization landscape of contrastive learning problems. Through analyzing the training dynamics by expressing them as a function of the Neural Tangent Kernel (NTK), the study reveals that neural networks inherently resist full collapse by injecting data distribution properties into the learning process. A significant insight is the NTK's ability to capture and possibly enhance clustering tendencies when the learned feature map starts respecting the input data’s underlying structure.
The Role of Kernel Induced by Neural Networks
The study outlines the impact of the kernel matrices induced by neural networks on learning. Specifically, for one-hidden-layer neural networks, the gradient flows significantly differ from those of standard gradient descent, underscoring how neural network weights guide optimization toward useful representational landmarks.
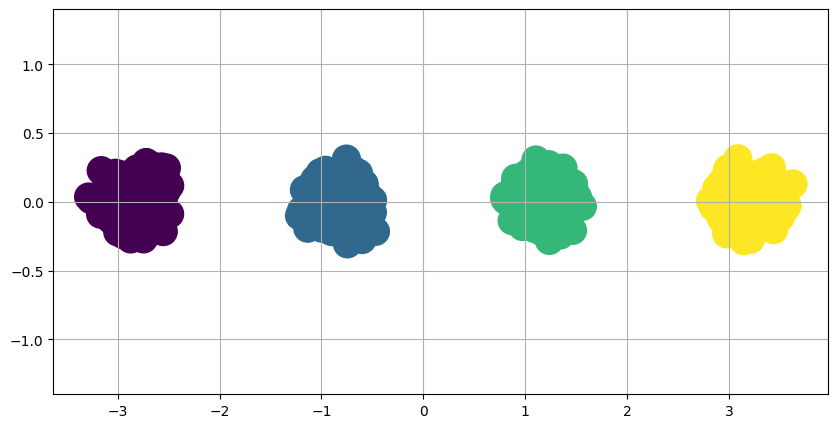
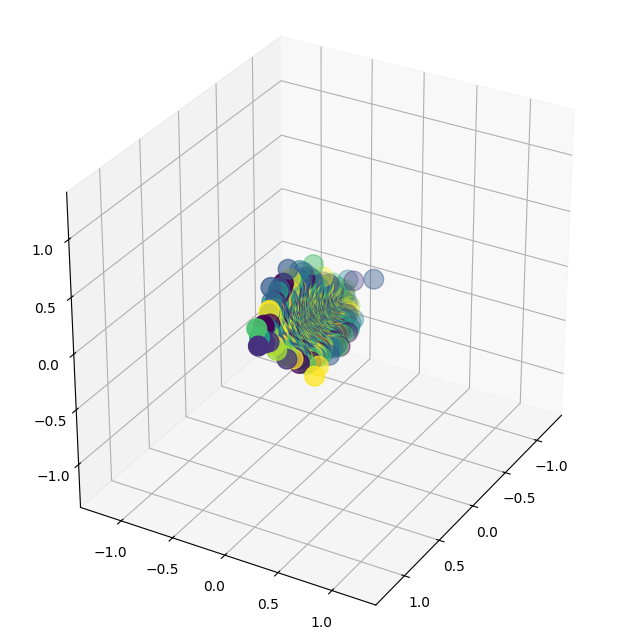
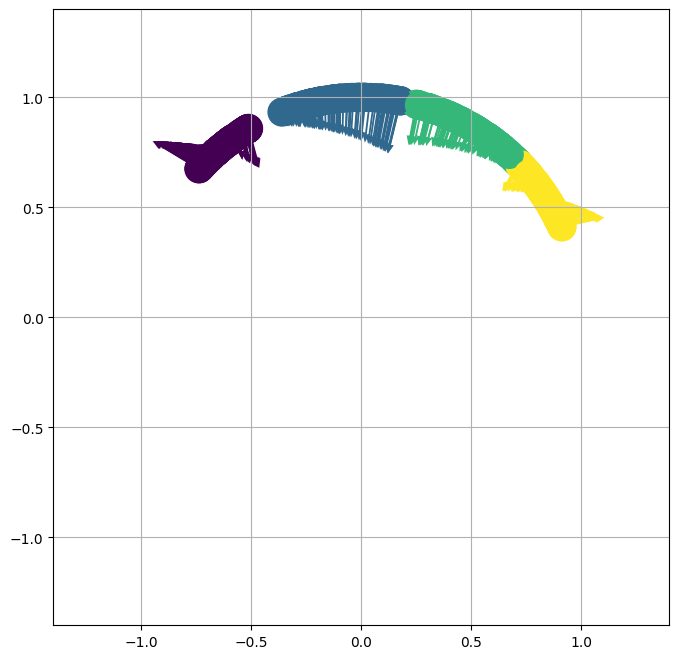
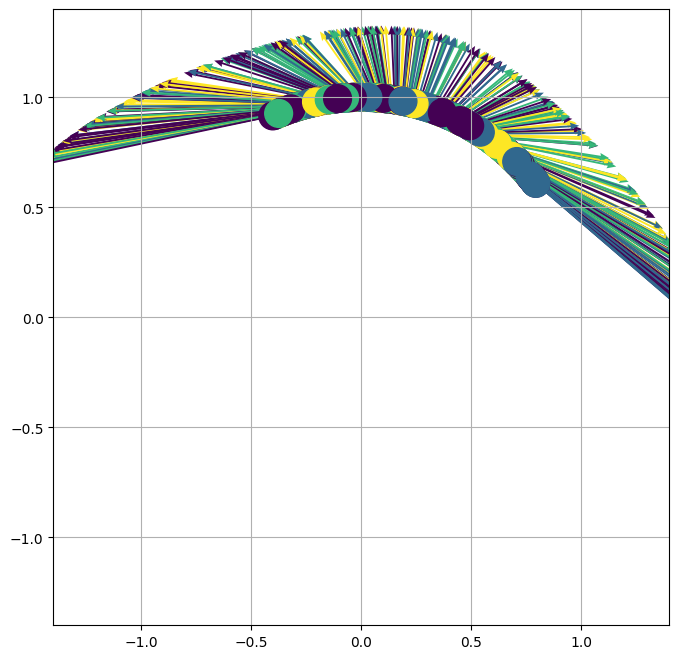
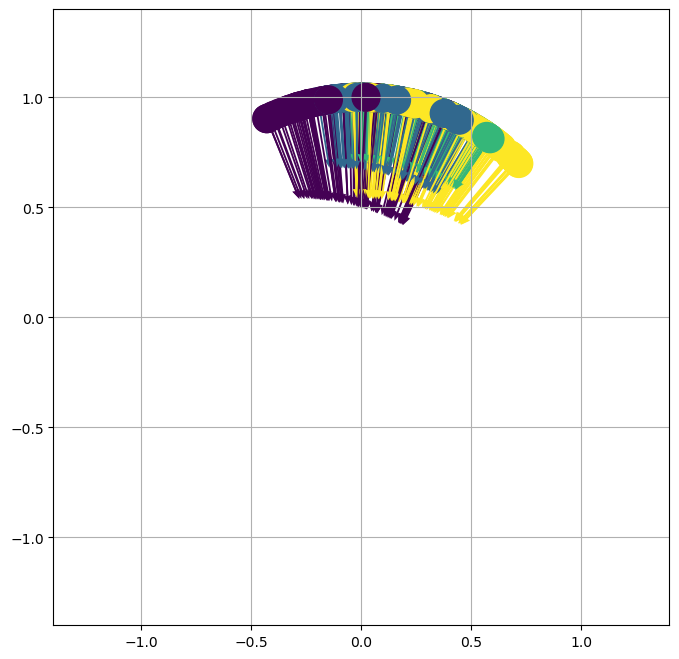
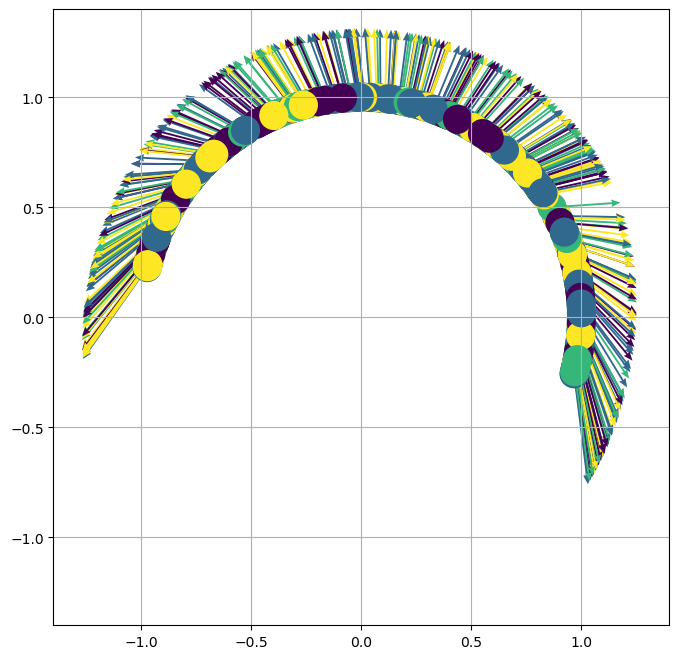
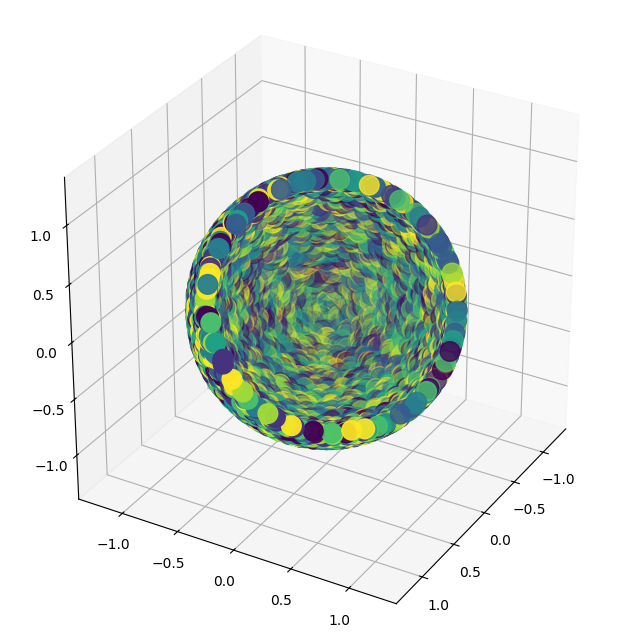
Figure 2: Neural network weights provide clustering dynamics, enhancing feature separability in contrast to default gradient descent methodologies.
Generally, the results underscore that contrastive learning's representational power depends on both the loss landscape and the dynamics introduced by rich, kernel-based architectures. Even with naive initializations, neural networks in contrastive learning steers the feature space towards structures that exploit intrinsic similarities in data clusters.
Practical Implications and Future Directions
The findings of this paper prompt several important strategies for practitioners leveraging contrastive learning. Primarily, it suggests focusing on the architecture choice and initialization strategy, as these can directly influence whether useful data representations are formed. The need to explore wider or deeper architectures as a means to achieve robust results invites further research.
Exploring mean field dynamics and rigorous convergence properties can provide further theoretical insight into these dynamics, perhaps illuminating more conditions under which contrastive learning methods like SimCLR can optimally function. Additionally, understanding the dependencies on kernel alignment relative to data geometry could dictate more sophisticated neural architecture designs tailored to specific applications.
Conclusion
This paper lays a foundation for a robust understanding of contrastive learning — particularly with SimCLR — by highlighting essential aspects of variational learnability and the critical role of parameters dictated by neural network-induced optimization dynamics. Through mathematical rigor and conceptual insights, the study suggests that success in these models depends not only on loss minimization but importantly on how the underlying network architecture nuances the learning pathway, thus maintaining rich data embeddings.