- The paper presents SemClip, a plug-and-play method that improves VLM fine-grained reasoning via semantic-guided visual selection.
- It employs a relevance-scoring function to efficiently choose task-related image regions, yielding 3.3% to 5.3% performance boosts on benchmark tests.
- SemClip integrates seamlessly with existing models without retraining, enabling practical deployment in advanced multimodal systems.
Semantic-Clipping: Efficient Vision-Language Modeling with Semantic-Guided Visual Selection
This essay provides a detailed, expert summary of the paper "Semantic-Clipping: Efficient Vision-Language Modeling with Semantic-Guided Visual Selection" (2503.11794), focusing on the practical implications and technical details of the SemClip method.
Introduction to Vision-LLMs
The paper addresses a fundamental challenge in Vision-LLMs (VLMs)—the inefficiencies arising from processing numerous visual tokens. VLMs transform images into visual tokens for integration with a LLM, excelling in tasks such as Visual Question Answering (VQA). Traditional approaches, involving image cropping to improve fine-grained reasoning, often result in increased token load, causing inefficiency and potential distractions in the LLM.
The SemClip Approach
The paper introduces SemClip, a lightweight, universal extension to existing VLMs, enhancing fine-grained visual reasoning without retraining the VLM.

Figure 1: Paying attention to task-relevant regions within a scene is an intuitive approach to answering visual questions. Our objective is to identify the optimal task-relevance measurement ψ that selects the most pertinent sub-region of an image, enhancing visual understanding.
Semantic-Guided Visual Selection
SemClip employs semantic interpretation of text queries to identify essential image regions, improving VQA performance and efficiency. It uses a relevance-scoring function, ψ, to determine which sub-images are incorporated into the visual encoding process. Importantly, SemClip integrates seamlessly with existing VLMs, requiring only minor adjustments without necessitating model retraining.
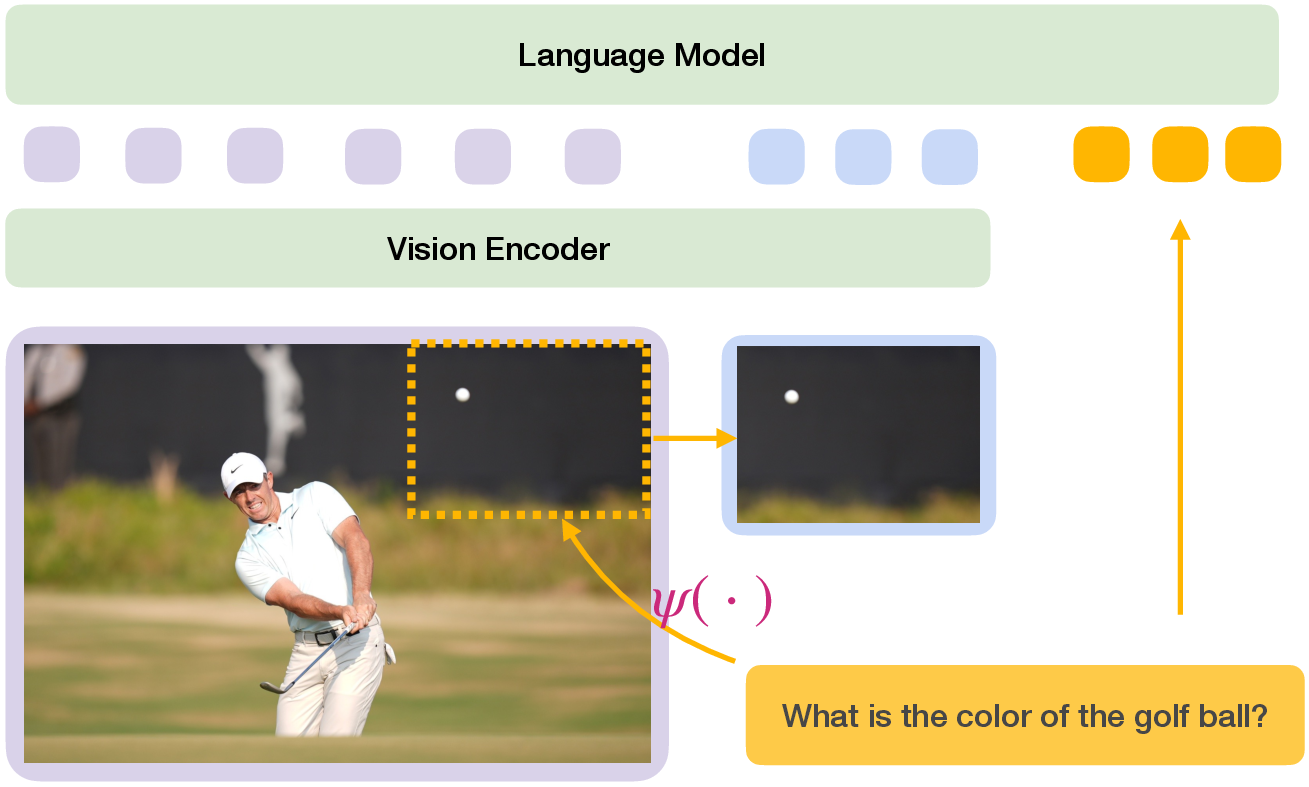
Figure 2: SemClip is a plug-and-play method that enhances a VLM through semantic-guided visual selection. Task-relevant sub-areas of the image are encoded and appended to the visual tokens of the overview image (colored in blue and purple, respectively). These visual tokens together with text embeddings of the question (colored in orange) are processed by the backbone VLM to generate a response.
Implementation Details
SemClip Structure
- Initial Setup:
- Original images are divided into multiple candidate sub-images.
- A scoring approach determines relevance to the query, selecting only the most pertinent sub-image.
- Semantic Clipping:
- The selected sub-image, along with the original image and textual query, is fed into the VLM.
- Various strategies, including pretrained models like CLIP, are employed for relevance measurement. A specific approach leveraging distant supervision proves most effective.
- Training and Performance:
- The method enhances LLaVA-1.5's VQA capabilities by 3.3% across seven benchmarks.
- Exhibits notable improvements in detailed understanding benchmarks, particularly offering a 5.3% boost on challenging tests.
The paper's experiments highlight SemClip's robust performance gains across several benchmarks, displaying a marked improvement in visual reasoning over traditional VLMs.
Theoretical Upper Bounds
SemClip approaches a significant theoretical upper bound for visual comprehension, which modern VLMs have yet to fully exploit. The potential for even greater performance suggests untapped possibilities in current methodologies.
Future Directions and Implications
Practical Deployment
SemClip presents practical benefits for incorporating task-relevant visual cues without overburdening computational resources, positioning itself as an efficient, effective enhancement to current VLM infrastructures.
Research Implications
The findings encourage exploration into semantic-guided visual selection during VLM training, opening pathways for more intelligent, context-aware multimodal systems.
Conclusion
SemClip stands out as a highly efficient enhancement to VLMs, leveraging semantic-guided visual selection to significantly boost fine-grained visual understanding. With its minimal impact on training requirements and pronounced improvements in task performance, SemClip promises a promising pathway for future advancements in multimodal AI systems.