- The paper introduces φ-Decoding, a method that leverages foresight sampling to estimate future impact and balance exploration with exploitation in LLM reasoning.
- It employs joint advantage and alignment value distributions via beam search rollouts along with adaptive dynamic pruning to optimize computational efficiency.
- Benchmark results show accuracy improvements up to 14.62% and up to sixfold FLOPS reduction, demonstrating scalability across diverse LLM backbones.
ϕ-Decoding: Adaptive Foresight Sampling for LLM Reasoning Optimization
Motivation and Context
Inference-time optimization approaches have gained traction for enhancing LLM reasoning performance without incurring the prohibitive expense and reproducibility barriers of post-training or reward modeling. Existing decoding paradigms such as auto-regressive generation achieve efficiency but suffer from myopic decisions, while search-based methods like tree search and MCTS provide global reasoning at significant computational cost. The paper "ϕ-Decoding: Adaptive Foresight Sampling for Balanced Inference-Time Exploration and Exploitation" (2503.13288) introduces a decoding strategy that leverages simulated future steps via foresight sampling for optimal step estimation, aiming for a balance between exploration and exploitation during inference.
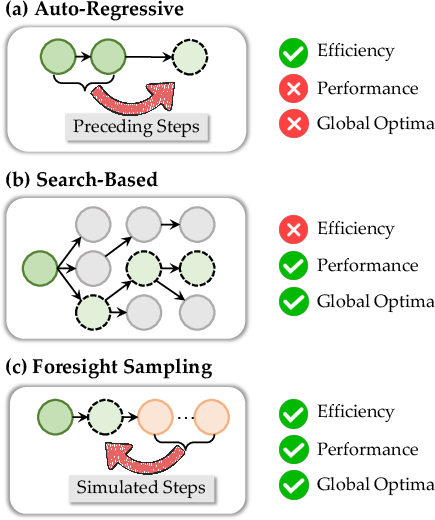
Figure 1: Comparison of auto-regressive, search-based, and foresight sampling paradigms, illustrating their distinct trade-offs with respect to global awareness and computational efficiency.
Methodological Framework
Foresight Sampling Paradigm
ϕ-Decoding employs foresight sampling, wherein at each reasoning timestamp, candidate steps are scored not just by their immediate generation probability but also by estimates of their future impact. This future simulation is computed via beam search rollouts, capturing a set of possible continuations for each candidate. Two distributions are constructed for step value estimation:
- Advantage Value (Absolute): Quantifies the increase in foresight path probability for a candidate over the previous step, reflecting uncertainty discrepancies and potential improvement.
- Alignment Value (Relative): Assesses step quality by clustering foresight paths, measuring the consistency and frequency of candidates within clusters.
The step value R is sampled from the joint normalized distribution of advantage and alignment, enabling both exploitation of confident steps and exploration of diverse reasoning paths. All operations are efficiently parallelized.
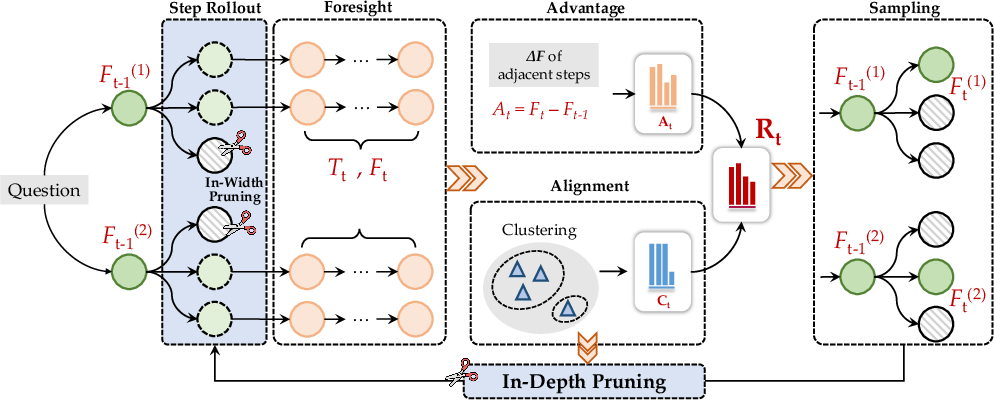
Figure 2: Visualization of the ϕ-Decoding framework at step t, depicting beam size, rollouts, clusters, and pruning actions.
Adaptive Dynamic Pruning
To mitigate unnecessary computation—specifically the overthinking phenomenon where LLMs excessively deliberate over trivial reasoning steps—ϕ-Decoding implements two adaptive pruning strategies:
- In-Width Pruning: Steps with generation confidence below a dynamic threshold (computed via mean and variance) are filtered out before foresight simulation.
- In-Depth Pruning: Early stopping is triggered when the size of the largest cluster exceeds a set threshold, with subsequent reasoning reverting to standard auto-regressive generation.
These strategies enable compute scaling and resource allocation tailored to step difficulty, with lightweight runtime cost.
Experimental Results
Benchmarking across six representative reasoning datasets (GSM8K, MATH-500, GPQA, ReClor, LogiQA, ARC-Challenge) and AIME competition-level benchmarks demonstrates superior average accuracy improvements—up to 14.62% for LLaMA3.1-8B-Instruct and 6.92% for Mistral-v0.3-7B-Instruct—over auto-regressive baselines. ϕ-Decoding outperforms strong search-based and predictive decoding baselines not only in accuracy but also in computational efficiency, achieving comparable or superior performance with up to sixfold reduction in FLOPS.
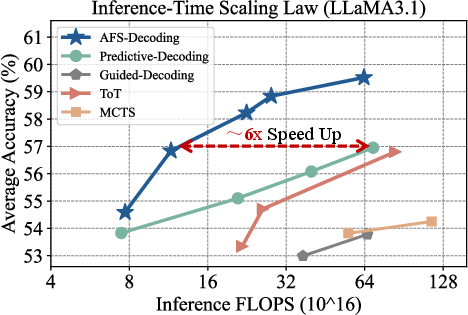
Figure 3: Inference-time scaling law showing ϕ-Decoding's consistent superiority across computational budgets and benchmarks.
Ablation and Analysis
Ablations highlight the key contributions: foresight sampling (absolute gains), clustering (relative gains), and dynamic pruning (efficiency without accuracy tradeoff). Step value estimation accuracy is tightly correlated with final task performance, reinforcing the efficacy of the joint distribution approach.
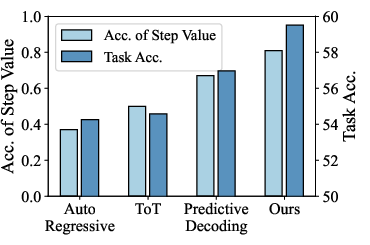
Figure 4: Step value estimation accuracy (light blue) versus final task performance (dark blue), demonstrating positive correlation.
Step-wise computational cost analysis reveals that broadened sampling and pruning are particularly effective at early reasoning steps, confirming that the allocation of resources is best concentrated in initial, pivotal decisions.
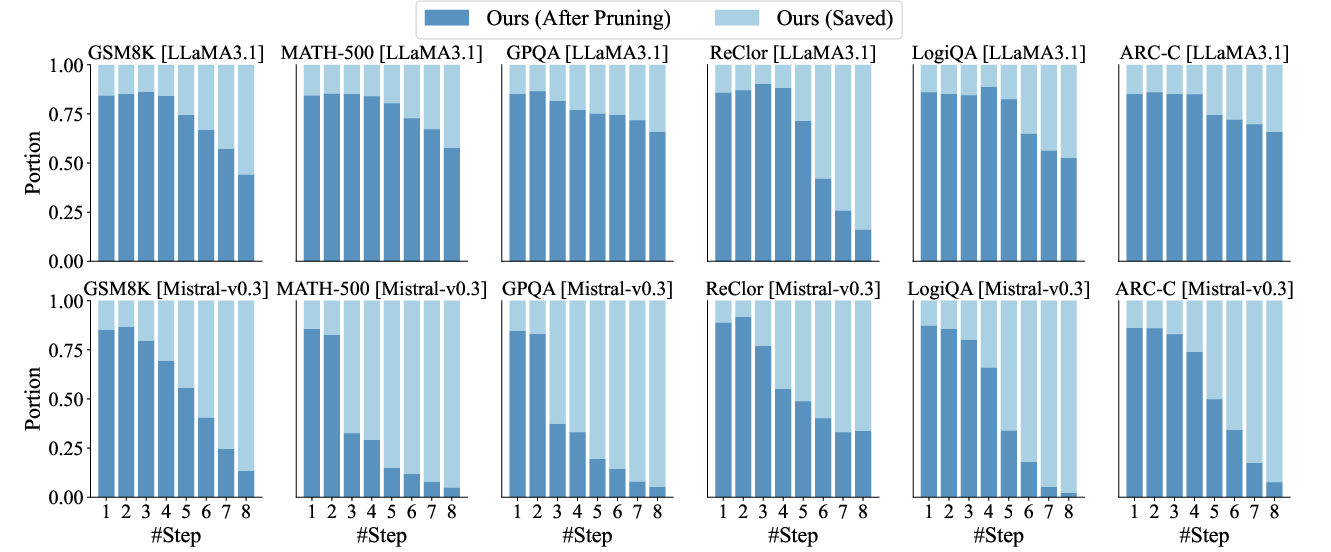
Figure 5: Step-wise effects on overthinking for both LLaMA and Mistral backbones, with pruning strategies reducing unnecessary computations.
Generalization and Scalability
ϕ-Decoding generalizes robustly across multiple LLM backbones from 3B up to 70B parameters—including LLaMA3.1-70B-Instruct and DeepSeek-R1-Distill-LLaMA-8B—demonstrating stable performance gains even in competition-level tasks. The adaptive scaling enables deployment in scenarios with variable compute budgets and inference-time constraints, addressing practical resource allocation challenges in LLM deployments.
Implications and Future Developments
The theoretical contribution lies in shifting inference-time optimization towards joint statistical modeling of absolute and relative reward, eschewing dependence on external process reward models, and providing a paradigm for efficient deliberate reasoning. Practically, ϕ-Decoding enables scalable, training-free enhancement of LLM reasoning chains for downstream applications ranging from mathematical problem solving to complex logical inference.
Future research directions include extending weighting schemes for advantage versus alignment, optimizing pruning thresholds, integrating hybrid reward functions, and adapting foresight sampling to multimodal or reinforcement learning contexts. The approach also lays groundwork for compute-adaptive LLM architectures, potentially enabling real-time allocation of reasoning effort commensurate with task complexity.
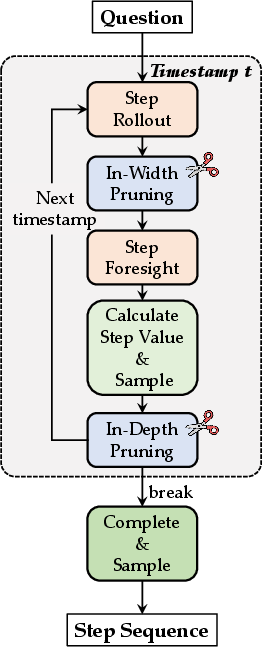
Figure 6: End-to-end pipeline view of ϕ-Decoding, encapsulating step sampling, value estimation, clustering, and prune-based allocation.
Conclusion
ϕ-Decoding introduces a principled, adaptive inference-time optimization algorithm that enables LLMs to achieve global-aware stepwise reasoning without external supervision or prohibitive search computation. Through foresight sampling and dynamic pruning across absolute and relative reward distributions, this strategy empirically and theoretically advances the state of inference-time exploration and exploitation, addressing critical scalability and resource allocation issues in LLM reasoning.