SuperBPE: Space Travel for Language Models
Abstract: The assumption across nearly all LLM (LM) tokenization schemes is that tokens should be subwords, i.e., contained within word boundaries. While providing a seemingly reasonable inductive bias, is this common practice limiting the potential of modern LMs? Whitespace is not a reliable delimiter of meaning, as evidenced by multi-word expressions (e.g., "by the way"), crosslingual variation in the number of words needed to express a concept (e.g., "spacesuit helmet" in German is "raumanzughelm"), and languages that do not use whitespace at all (e.g., Chinese). To explore the potential of tokenization beyond subwords, we introduce a "superword" tokenizer, SuperBPE, which incorporates a simple pretokenization curriculum into the byte-pair encoding (BPE) algorithm to first learn subwords, then superwords that bridge whitespace. This brings dramatic improvements in encoding efficiency: when fixing the vocabulary size to 200k, SuperBPE encodes a fixed piece of text with up to 33% fewer tokens than BPE on average. In experiments, we pretrain 8B transformer LMs from scratch while fixing the model size, vocabulary size, and train compute, varying only the algorithm for learning the vocabulary. Our model trained with SuperBPE achieves an average +4.0% absolute improvement over the BPE baseline across 30 downstream tasks (including +8.2% on MMLU), while simultaneously requiring 27% less compute at inference time. In analysis, we find that SuperBPE results in segmentations of text that are more uniform in per-token difficulty. Qualitatively, this may be because SuperBPE tokens often capture common multi-word expressions that function semantically as a single unit. SuperBPE is a straightforward, local modification to tokenization that improves both encoding efficiency and downstream performance, yielding better LLMs overall.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper asks a simple question with a big impact: Do computers really need to split text only at spaces when they “read” and “think”? The authors introduce SuperBPE, a new way to break text into pieces (called tokens) that lets a LLM group common phrases like “by the way” or “Milky Way” as single pieces, not just single words or parts of words. This makes models faster, cheaper to run, and often smarter.
The big questions the authors asked
- Can we make LLMs work better by letting tokens cross spaces (so one token can be several words), not just stop at word boundaries?
- Will this “superword” tokenization make text shorter in tokens, saving compute time and memory?
- If we keep the model size, training data, and training budget the same, does changing only the tokenizer improve real-world performance on many tasks?
How did they test their idea?
First, a quick primer:
- Tokenization: Imagine you want to read a sentence but can only look at a few “chunks” at a time. A tokenizer decides where to cut the sentence into chunks (tokens). Traditional tokenizers mostly cut at spaces and also split long or rare words into smaller parts (subwords).
- BPE (Byte-Pair Encoding): Think of building with LEGO. BPE starts with tiny bricks (bytes) and repeatedly snaps together the pairs of pieces that show up next to each other most often, creating bigger, more useful bricks (subwords). Classic BPE doesn’t let pieces join across spaces, so it won’t turn “by the way” into one brick.
What SuperBPE changes:
- Two-stage learning (a simple curriculum): 1) Stage 1: Learn normal subword tokens (no crossing spaces), just like standard BPE. 2) Stage 2: Turn off the “no crossing spaces” rule, so the algorithm can also learn superword tokens that span multiple words (like “by_the_way”).
- Why this helps: Many phrases act like single ideas. Grouping them reduces the total number of tokens and can make the model’s job easier and faster.
How they experimented:
- They trained large transformer LLMs (about 8 billion parameters) from scratch.
- They kept everything the same—model size, training data mix, total training compute, and vocabulary size (200,000 tokens)—and changed only how the tokenizer learns its vocabulary (BPE vs. SuperBPE).
- They tried different “transition points” (when to switch from Stage 1 to Stage 2), such as 80k, 160k, and 180k tokens learned.
An everyday analogy: Packing a suitcase. BPE packs each word (or word piece) separately. SuperBPE lets you bundle common outfits (multi-word phrases) into a single packing cube. You fit more with fewer items to manage.
What did they find? Why it matters
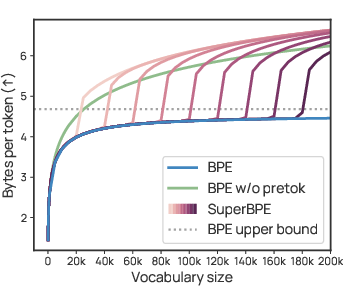
Shorter tokenized text (better “encoding efficiency”):
- With the same 200k vocabulary size, SuperBPE used up to about 33% fewer tokens to represent the same text than regular BPE.
- In simple terms, each token carries more text on average, so the model needs fewer steps to read or generate the same passage.
Faster and cheaper at inference (when you actually use the model):
- Because there are fewer tokens, the model does less work per response.
- In their 8B-model tests, SuperBPE cut inference compute by about 27%–35%, depending on the setup.
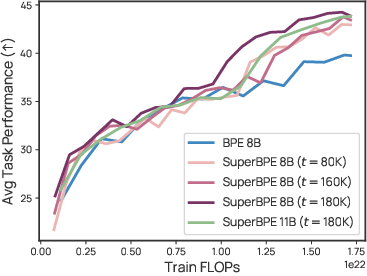
Stronger performance on many tasks:
- Across 30 evaluation tasks (covering knowledge, reasoning, reading, and more), the best SuperBPE model scored about +4.0 percentage points higher on average than the BPE baseline.
- It won on 25 out of 30 tasks, including big gains on multiple-choice benchmarks (for example, +8.2 on MMLU).
Why it might help the model think better:
- SuperBPE often creates tokens that are common, meaningful phrases (like “by accident,” “in the long run,” “for a living,” “by the way”).
- The authors found SuperBPE spreads difficulty more evenly across tokens: fewer “too easy” and fewer “very hard” predictions. That may help models focus on the challenging parts that matter for real tasks.
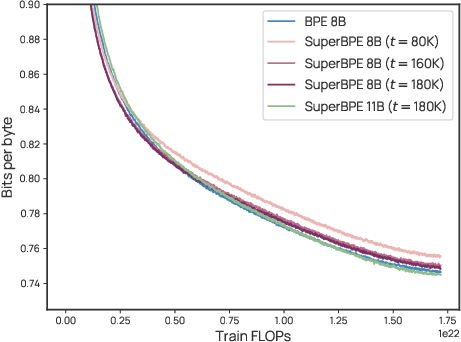
A small caveat explained simply:
- A metric called bits-per-byte (BPB) measures how hard the model’s predictions are, adjusted for token size. SuperBPE’s BPB was very close to BPE’s—and sometimes slightly worse—even though SuperBPE did better on tasks. Why? Because SuperBPE merges some extremely common words (like “the” or “of”) into longer tokens, removing some of the “easy wins.” At the same time, it reduces the worst-case mistakes, which likely boosts task accuracy where it counts.
What could this change in the real world?
- Better models without changing architectures: SuperBPE is a small, drop-in tokenizer change. No need to redesign the model or training code.
- Lower costs and energy use: Fewer tokens per input means faster, cheaper, and greener inference.
- Smarter handling of language: Many languages don’t use spaces the way English does, and many ideas are phrases, not single words. SuperBPE naturally captures these, which can help multilingual and phrase-heavy text.
- Practical takeaway: If you’re training or serving LLMs, switching to SuperBPE can yield both performance gains and efficiency savings.
- Future directions: SuperBPE could be combined with other techniques (like predicting multiple tokens at once) for even bigger benefits.
In short, the paper shows that letting tokens cross spaces—so models can treat common phrases as single units—makes LLMs more efficient and often more capable, all with a simple change to how we split text.
Collections
Sign up for free to add this paper to one or more collections.