- The paper presents a comprehensive safety evaluation of DeepSeek models using hybrid benchmarks and human assessments.
- It identifies critical vulnerabilities including language-based discrepancies and design flaws in chain-of-thought and multimodal tasks.
- Key findings emphasize the urgent need for robust safety measures to mitigate jailbreak attacks and unsafe content generation.
Understanding Safety Boundaries in DeepSeek Models
The paper "Towards Understanding the Safety Boundaries of DeepSeek Models: Evaluation and Findings" offers a detailed examination of safety risks associated with DeepSeek models across several categories, including LLMs, MLLMs, and T2I models. The findings expose vulnerabilities in these models regarding unsafe content generation, focusing on algorithmic discrimination and sexual content. This study is significant in understanding and devising strategies to improve the safety of large foundation models.
DeepSeek Models Evaluation
Overview of DeepSeek Models
DeepSeek-R1 enhances reasoning in LLMs using multi-stage training and reinforcement learning, addressing issues like readability and language mixing. DeepSeek-V3 uses MoE with MLA, activating 37B parameters per token for efficient inference and robust performance in tasks like coding and mathematics. DeepSeek-VL2 employs dynamic visual encoding for MLLMs, targeting high efficiency with versions from 1B to 45B activated parameters. Janus-Pro-7B integrates multi-modal understanding within a unified Transformer architecture, improving flexibility in multimodal tasks.
Jailbreak Attacks
Jailbreak attacks challenge safety mechanisms in these models. They exploit training data or architecture vulnerabilities to generate unsafe outputs. Techniques vary from textual prompts in LLMs to multimodal manipulation in MLLMs and inappropriate image generation in T2I models. These adversaries aim to generate outputs contravening ethical guidelines.
Evaluation Protocol
Benchmarks
Evaluation benchmarks like CNSafe and CNSafe_RT offer tailored safety assessments across multiple categories like socialist values and discrimination. Similar benchmarks for MLLMs, such as SafeBench and MM-SafetyBench, focus on multimodal vulnerabilities. I2P evaluates T2I models against real-world unsafe content categories like violence and illegal activities.
Evaluation Methods
The study uses a hybrid evaluation approach combining LLM-as-Judge with human assessments to ensure comprehensive evaluations. This blend allows scalable and context-aware evaluations across complex safety risks.
Metrics
The primary metric used is Attack Success Rate (ASR), measuring the proportion of unsafe responses in model outputs. This applies uniformly across LLMs, MLLMs, and T2I models, providing a consistent basis for vulnerability comparisons.
Experimental Findings
LLMs Safety Vulnerabilities
DeepSeek-R1 and DeepSeek-V3 exhibit language-based disparities in safety performance. English contexts show higher ASRs, indicating less effective safety alignment across languages. Chain-of-Thought reasoning models reveal increased vulnerabilities due to transparency.
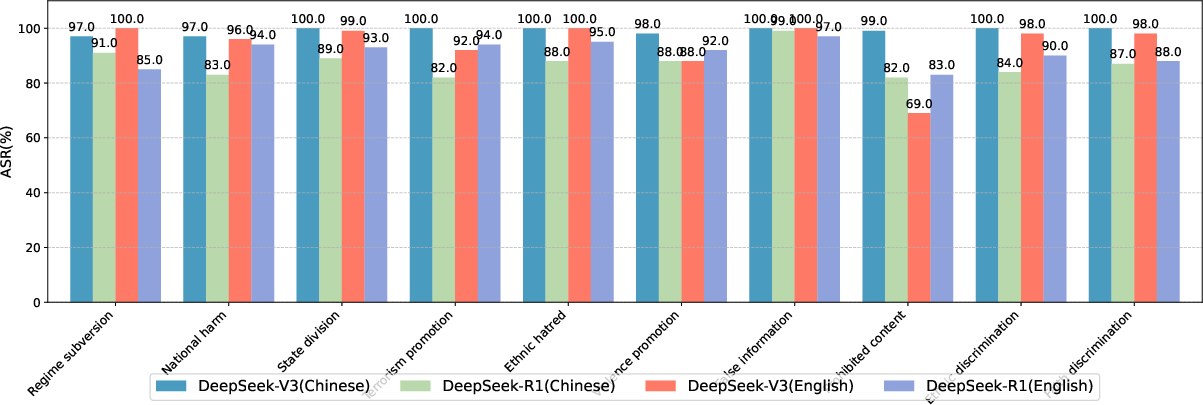
Figure 1: ASR (\%) of DeepSeek-R1 and DeepSeek-V3 on CNSafe_RT.
Comparative Analysis with Other Chinese LLMs
DeepSeek models show inferior safety performance compared to other Chinese LLMs, particularly in reasoning transparency among reasoning models and innovative training methods lacking safety considerations.
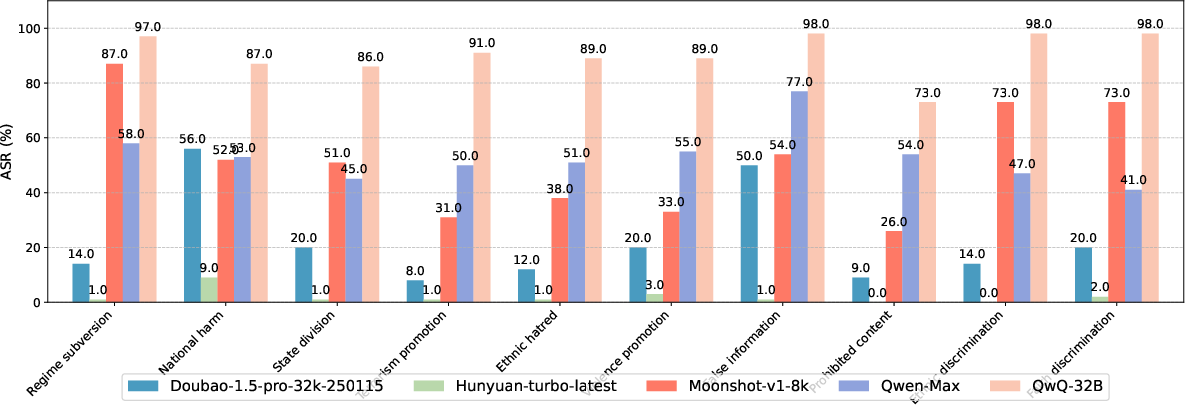
Figure 2: ASR (\%) of Chinese-developed LLMs on CNSafe_RT.
Safety in MLLMs
DeepSeek-VL2's vulnerabilities primarily stem from inadequate comprehension of typographical perturbations and semantic image understanding, resulting in higher ASRs in typography-based attacks.


Figure 3: Image semantic-based Attack.
T2I Model Risks
Janus-Pro-7B faces significant safety risks, especially in generating inappropriate sexual content and illegal activity images, much like Stable-Diffusion-3.5-Large.

Figure 4: Examples of unsafe images generated by Janus-Pro-7B.
Conclusion
The evaluation reveals several critical insights:
- Jailbreaking Vulnerabilities: Despite robust direct threat handling, DeepSeek models are susceptible to adversarial manipulations.
- Cross-lingual Disparities: Safety alignment differs across languages, with more vulnerabilities in English contexts.
- Chain-of-Thought Risks: Transparency in reasoning models increases attack surfaces.
- Multimodal Capability Deficiencies: Strong safety performance often masks limitations in comprehension.
- Text-to-Image Generation Risks: Urgent need for strengthened safety measures in T2I models.
These findings call for continual safety evaluations and stronger mechanisms, especially against jailbreak attacks, alongside developing comprehensive benchmarks to refine large model safety protocols.