- The paper demonstrates that a two-stage training process with optimal visual backbones yields significant multimodal performance improvements.
- It evaluates the effects of model scale and image resolution, showing that smaller models with advanced visual encoders can outperform larger ones on visual tasks.
- The study highlights the impact of contrastive pre-training in visual encoders, with models like SigLIP2 achieving consistent gains across benchmarks.
LLaVA-MORE: A Comparative Study of LLMs and Visual Backbones for Enhanced Visual Instruction Tuning
Introduction
The paper "LLaVA-MORE: A Comparative Study of LLMs and Visual Backbones for Enhanced Visual Instruction Tuning" (2503.15621) focuses on optimizing Multimodal LLMs (MLLMs) by integrating advanced visual backbones with LLMs of varying scales. As the field of MLLMs is rapidly advancing, the research addresses the unexplored trade-offs between model size, architecture, and performance, implementing a unified training protocol for fair comparisons. Through a systematic evaluation of different models and configurations, the authors aim to derive insights into effective MLLM architectures that outperform traditional setups by leveraging state-of-the-art visual encoders and LLM pairings.

Figure 1: Performance comparison of the best version of LLaVA-MORE with other LLaVA variants across different benchmarks for multimodal reasoning and visual question answering.
Methodology
LLaVA-MORE extends the standard LLaVA framework through a two-stage training process. The first stage focuses on aligning the visual features with the underlying LLM to ensure effective cross-modal representation. The second stage enhances the MLLM's conversational capabilities through visual instruction tuning. This two-stage process is systematically applied across all configurations to ensure consistency and comparability.
Different LLMs, including Phi-4, LLaMA-3.1, and Gemma-2, are paired with diverse visual backbones such as CLIP, DINOv2, SigLIP, and SigLIP2. The authors adopt a thorough experimental setup involving a range of multimodal tasks to understand the influence of model size and pre-training data on performance.
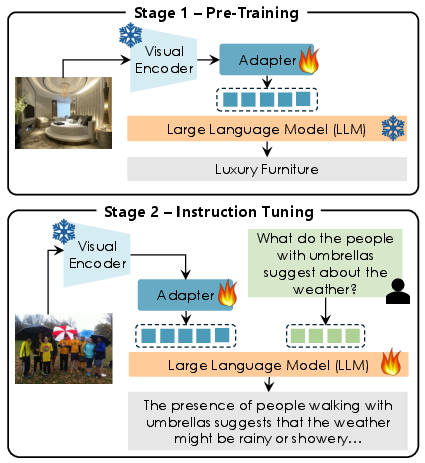
Figure 2: Overview of the LLaVA-MORE architecture, highlighting the two-stage training process and the evaluation of various LLM and visual encoder choices.
Experimental Evaluation
Influence of Model Scale and Visual Backbone
The paper conducts a comprehensive evaluation by varying both the scale of the underlying LLM and the choice of the visual backbone. The results demonstrate that even small-scale models configured with appropriate visual encoders can outperform medium-scale counterparts. Amongst the model configurations, LLaVA-MORE with Phi-4-3.8B and SigLIP2 showcases notable gains across varied benchmarks.
The analysis further reveals that visual backbones pre-trained with contrastive learning, such as SigLIP and SigLIP2, consistently surpass other self-supervised models irrespective of the LLM scale, highlighting the importance of pre-training strategies that enhance cross-modal alignment.
Impact of Image Resolution
Resolution and visual token count significantly impact model performance. Increasing image resolution through multi-scale processing, i.e., the S² scheme, provides performance boosts particularly for smaller models, although the benefits diminish for larger scale models and are task-dependent. Notably, higher resolutions contribute to substantial improvements in VQA benchmarks that require detailed scene understanding.
Qualitative Results
Qualitative analyses were performed to further illustrate the advantages of proposed configurations. These analyses compared image descriptions generated by different LLaVA-MORE models, highlighting differences in detail, context, and narrative style. The results showed that models trained using the enhanced configurations provided more accurate and contextually enriched descriptions.

Figure 3: Qualitative comparisons of image descriptions generated by three MLLMs, demonstrating differences in context and narrative style.
Conclusion
This study advances the understanding of optimizing MLLMs by systematically evaluating different LLM and visual backbone combinations. The findings underscore that maximizing the effectiveness of MLLMs does not solely depend on scaling model size but rather leveraging the right architectural and pre-training data choices. The introduction of LLaVA-MORE models presents a reproducible framework that encourages further exploration and optimization of multimodal architectures.
Future work could extend these insights by exploring the integration of novel visual backbone architectures and further refining multimodal training protocols to accommodate evolving datasets and tasks.