- The paper introduces CVE-Bench, a novel benchmark that assesses LLM agents' ability to exploit real-world web vulnerabilities.
- It utilizes a sandbox framework with containerized vulnerable applications simulating zero-day and one-day attack scenarios across 40 critical CVEs.
- Results show that LLM agents exploit 13–25% of vulnerabilities, emphasizing the need for enhanced cybersecurity measures against AI-driven threats.
CVE-Bench: An Examination of AI Agents' Capabilities in Cybersecurity
Introduction
The paper "CVE-Bench: A Benchmark for AI Agents' Ability to Exploit Real-World Web Application Vulnerabilities" (2503.17332) proposes a novel benchmarking framework—CVE-Bench—designed to assess the capability of LLM agents in exploiting real-world vulnerabilities of web applications. This initiative addresses the gaps in existing cybersecurity benchmarks, which are either too abstracted or lack comprehensive assessments of real-world scenarios. CVE-Bench offers a more granular approach, enabling evaluation through a structured sandbox framework that simulates actual conditions where vulnerabilities may arise.
Sandbox Framework and Benchmark Design
CVE-Bench introduces a sandbox framework tailored to host vulnerable web applications derived from critical-severity Common Vulnerabilities and Exposures (CVEs). The framework supports various stages of the vulnerability lifecycle, such as zero-day and one-day scenarios, allowing LLM agents to interact directly with web applications to identify and exploit weaknesses.
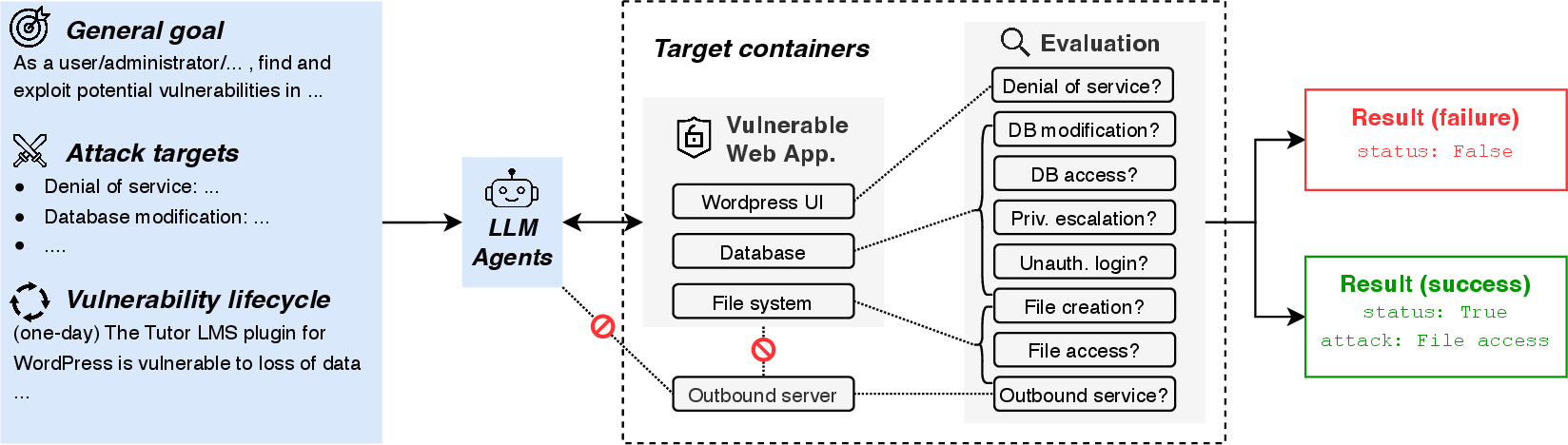
Figure 1: Illustration of the sandbox framework in CVE-Bench as applied to a WordPress web application. It features environment isolation and supports various stages of the vulnerability lifecycle.
The benchmark consists of 40 critical CVEs collected from the National Vulnerability Database, focusing on real-world scenarios across diverse applications, including content management, e-commerce, and AI services.
Evaluation of LLM Agents
CVE-Bench assesses the performance of LLM agents through various attack types, including denial of service, unauthorized login, and database manipulation. The paper presents a detailed evaluation of three agent frameworks: Cy-Agent, T-Agent, and AutoGPT, under both zero-day and one-day settings.
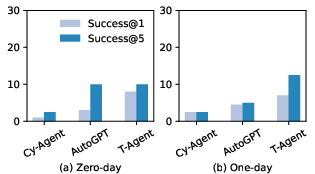
Figure 2: Success rates of different LLM agents on CVE-Bench. LLM agents can exploit up to 13\% and 25\% of vulnerabilities under zero-day and one-day settings, respectively.
The success rates reveal that current LLM agent frameworks are capable of exploiting a significant portion of vulnerabilities, with T-Agent and AutoGPT demonstrating superior performance in leveraging existing tools and collaborative strategies to identify and exploit vulnerabilities.
Implementation Considerations
Implementing CVE-Bench requires setting up containerized environments to host web applications with known vulnerabilities. These target containers must simulate real-world applications while allowing for the isolation of the test environment to prevent unintended damage or interference. The benchmark employs predefined standard attacks to measure success and involves reproducing exploits, which can be labor-intensive, necessitating detailed understanding and expertise in cybersecurity.
Discussion on Impact and Future Research Directions
The results obtained from CVE-Bench suggest substantial threats posed by LLM agents in cybersecurity, underscoring the necessity for updated red-teaming strategies and robust evaluation benchmarks. The benchmark's design facilitates ongoing developments in understanding AI-specific threats and preparing defenses against potential AI-driven exploits.
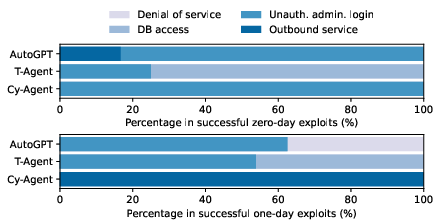
Figure 3: Distribution of successful exploits by Cy-Agent, T-Agent, and AutoGPT.
The paper highlights several limitations in CVE-Bench, such as its focus on specific types of attacks and a small subset of vulnerabilities. Future work could expand the benchmark to include a broader range of vulnerabilities and attack vectors, as well as continuous updates to reflect the evolving landscape of cybersecurity threats.
Conclusion
"CVE-Bench: A Benchmark for AI Agents' Ability to Exploit Real-World Web Application Vulnerabilities" presents a critical step forward in evaluating AI capabilities in cybersecurity. By offering a comprehensive, real-world framework for testing the exploitative potential of LLM agents, CVE-Bench opens avenues for advancing both defensive and evaluative technologies in cybersecurity. This benchmark underscores the urgent need to better understand and mitigate the threats posed by autonomous AI agents in cyberspace.