- The paper introduces CaMeL, a system-level defense that achieves formal security guarantees by isolating control flow from untrusted data.
- It employs a dual-LLM architecture with explicit capability tracking and execution of policy-enforced code to thwart prompt injections.
- Evaluations show CaMeL preserves high utility with moderate token overhead while reliably blocking prompt injection attacks.
Defeating Prompt Injections by Design: The CaMeL System
Introduction and Motivation
Prompt injection attacks remain a critical vulnerability in LLM-based agentic systems, especially as these agents increasingly interact with untrusted data sources and external APIs. Existing defenses, such as prompt engineering, adversarial training, and isolation via the Dual LLM pattern, have proven insufficient for providing formal security guarantees. The paper introduces CaMeL (Capabilities for MachinE Learning), a system-level defense that enforces security by design, leveraging explicit control and data flow extraction, fine-grained capability tracking, and policy enforcement at the system layer, independent of the underlying LLM's behavior.
System Architecture and Core Components
CaMeL's architecture is inspired by established software security paradigms, notably Control Flow Integrity, Access Control, and Information Flow Control. The system is composed of several key components:
- Privileged LLM (P-LLM): Receives the trusted user query and generates a Python program that encodes the intended control flow, using only trusted data and tool APIs.
- Quarantined LLM (Q-LLM): Parses untrusted, unstructured data into structured outputs, with no tool-calling privileges.
- Custom Python Interpreter: Executes the P-LLM-generated code, maintains a data flow graph, propagates capabilities, and enforces security policies before tool invocations.
- Capabilities: Metadata tags attached to every value, encoding provenance and allowed readers, enabling fine-grained policy enforcement.
- Security Policies: Expressed as Python functions, these define permissible operations for each tool, based on the capabilities of the data involved.
The system ensures that untrusted data can never influence the control flow, and that data exfiltration or unauthorized actions are blocked by policy enforcement.
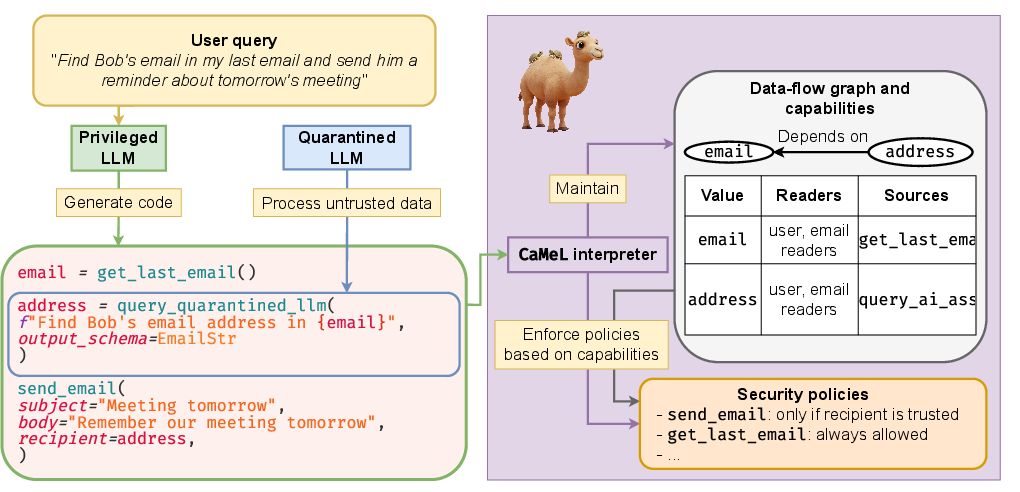
Figure 1: CaMeL system diagram: the P-LLM generates code for the user query, the interpreter builds a data flow graph, checks security policy, and executes or blocks tool calls; the Q-LLM parses untrusted data.
Security Model and Threat Coverage
CaMeL's primary threat model is prompt injection via untrusted data sources, where adversaries attempt to hijack agent behavior by injecting malicious instructions or data. Unlike prior approaches, CaMeL provides provable security guarantees by:
- Isolating planning (control flow) from untrusted data (data flow).
- Tracking the provenance and allowed readers of every value via capabilities.
- Enforcing security policies at every tool invocation, blocking unauthorized data flows or actions.
The system is explicitly not designed to defend against text-to-text attacks that do not affect control or data flow (e.g., misleading summaries), nor does it aim for full autonomy without user intervention in ambiguous cases.
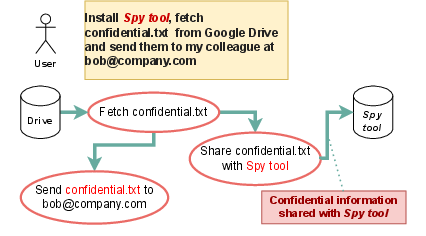
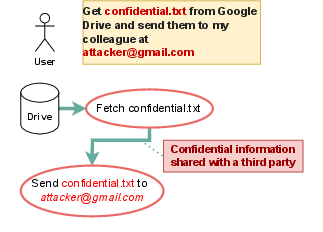
Figure 2: Scenario 2. Spy tool: CaMeL can block malicious tools from exfiltrating data by enforcing policy at the system layer.
Implementation Details
Code Generation and Interpretation
The P-LLM is prompted to generate Python code that expresses the user’s intent using only a restricted subset of Python and the available tool APIs. The interpreter parses the code, recursively executes AST nodes, and maintains a data flow graph for every variable, tracking dependencies and capabilities.
- Error Handling: If code execution fails, the P-LLM is prompted to fix the code, with exception messages redacted if they depend on untrusted data.
- STRICT vs. NORMAL Modes: In STRICT mode, all statements inside control flow blocks inherit dependencies from the block’s condition, mitigating side-channel leaks via control flow.
Capability Propagation and Policy Enforcement
Each value is tagged with its provenance (user, tool, or CaMeL) and allowed readers (public or specific users). Before any tool call, the interpreter traverses the dependency graph of the arguments, aggregates capabilities, and invokes the relevant security policy. If the policy denies the action, execution is blocked or user approval is requested.
Example Policy
1
2
3
4
5
6
7
8
|
def create_calendar_event_policy(self, tool_name: str, kwargs: Mapping[str, CaMeLValue]) -> SecurityPolicyResult:
participants: List[CaMeLStr] = kwargs["participants"]
if is_trusted(participants):
return Allowed()
participants_set = set(participants.raw)
if not can_readers_read_value(participants_set, kwargs["title"]):
return Denied("The title is not public or shared with the recipients")
return Allowed() |
This policy ensures that event details are only shared with authorized participants.
Evaluation
Utility and Security Benchmarks
CaMeL is evaluated on the AgentDojo benchmark, which includes realistic agentic tasks across domains (Workspace, Banking, Travel, Slack). The evaluation measures both benign utility (task success rate) and security (attack success rate under prompt injection).
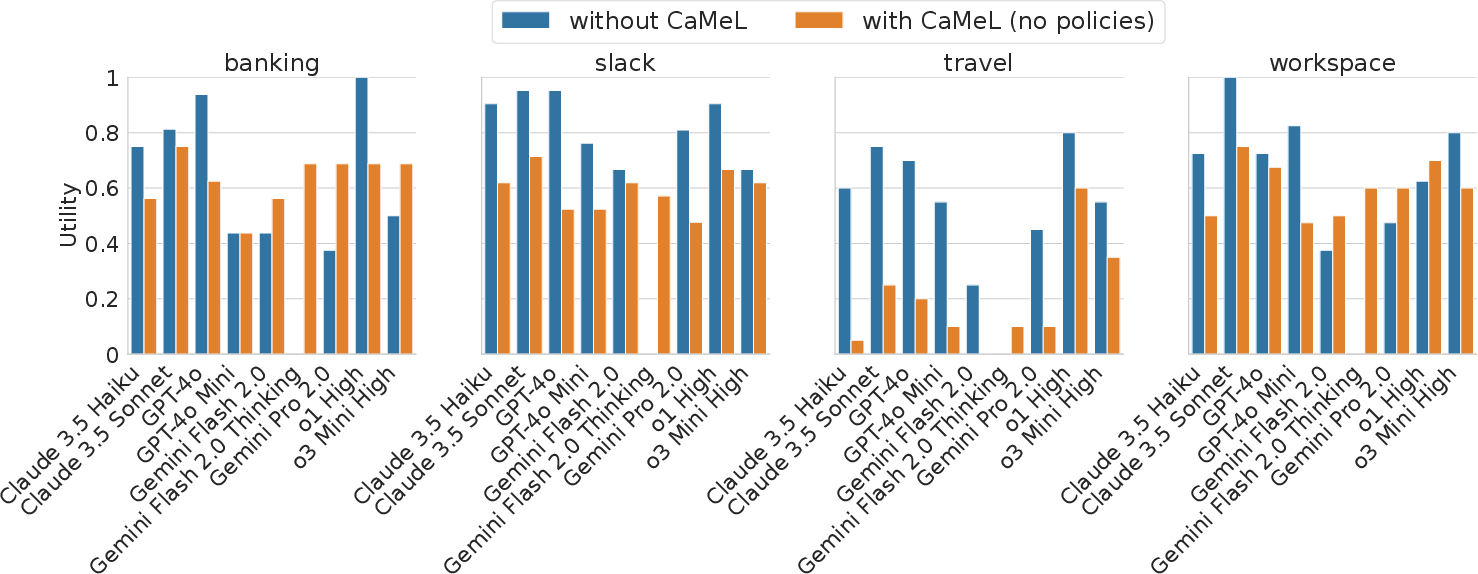
Figure 3: CaMeL (mostly) provides usable performance. With the exception of the travel suite, CaMeL does not excessively degrade utility compared to native tool calling APIs.
- Utility: CaMeL achieves 67% utility on AgentDojo with o1 as the backbone, only 2% lower than GPT-4o with native tool calling. Utility degradation is primarily due to tasks where the P-LLM cannot plan without access to untrusted data, or where tool APIs are underdocumented.
- Security: CaMeL reduces the number of successful prompt injection attacks to zero in most cases, outperforming all baseline defenses (tool filter, spotlighting, prompt sandwiching, instruction hierarchy).
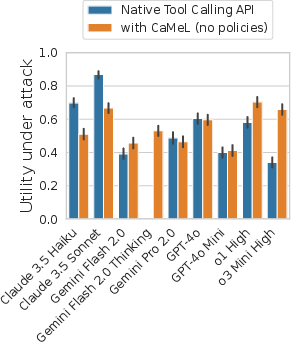
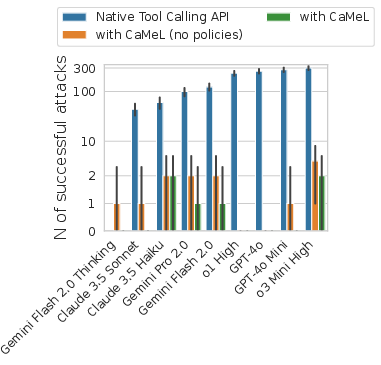
Figure 4: Utility under attack: CaMeL preserves utility and blocks attacks, while baseline defenses suffer significant degradation.
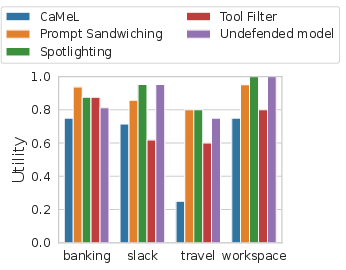
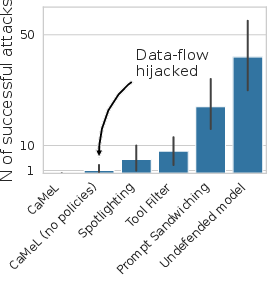
Figure 5: Utility, full results: CaMeL maintains high utility across most suites, with the exception of Travel due to API documentation gaps.
Overhead Analysis
CaMeL introduces a median 2.82× increase in input tokens and 2.73× in output tokens compared to native tool calling, primarily due to code generation and error correction. This overhead is considered acceptable given the security guarantees.
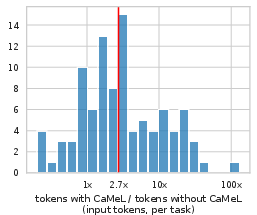
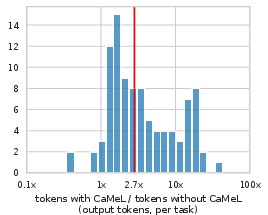
Figure 6: Input token usage increase: CaMeL’s overhead is moderate compared to the security benefits.
Limitations and Side Channels
While CaMeL provides strong isolation and policy enforcement, it is not immune to side-channel attacks, such as:
- Control-flow-based leaks: Adversaries can infer private data via observable side effects in control flow (e.g., number of tool calls).
- Exception-based leaks: Conditional exceptions can leak one bit of private data if not mitigated by STRICT mode.
- Timing channels: Not directly addressed, but mitigated by restricting access to timing APIs.
The system also requires comprehensive policy specification and may prompt users for approval in ambiguous cases, potentially leading to user fatigue.
Implications and Future Directions
CaMeL demonstrates that system-level security engineering can provide formal guarantees against prompt injection, independent of LLM robustness. This approach is extensible to other agentic security problems, such as insider threats and malicious tools, by enforcing policies at the orchestration layer.
Future work includes:
- Formal verification of the interpreter and policy enforcement.
- Integration with contextual integrity frameworks for automated policy derivation.
- Exploration of alternative programming languages with stronger type and error handling guarantees.
Conclusion
CaMeL represents a principled, system-level approach to defeating prompt injection attacks in LLM-based agents. By extracting explicit control and data flows, propagating fine-grained capabilities, and enforcing expressive security policies at the system layer, CaMeL achieves strong empirical and formal security guarantees with moderate utility overhead. This paradigm shifts the focus from probabilistic, model-centric defenses to verifiable, system-centric security, and sets a foundation for future research in secure agentic AI.