- The paper introduces a unique dataset of 560 Rumble-hosted podcast episodes that exemplify state-sponsored information operations.
- It employs custom scraping, high-fidelity ASR transcription, and rigorous quality control to curate detailed metadata and engagement metrics.
- Findings reveal varied content strategies and targeted disinformation tactics, opening new avenues for research on SSIOs.
The paper "Outsourcing an Information Operation: A Complete Dataset of Tenet Media's Podcasts on Rumble" (2503.19802) presents a rare and comprehensive dataset of state-sponsored information operation (SSIO) content that diverges from traditional ground-truth resources by focusing on paid podcast content produced by U.S.-based media figures, with direct funding and editorial oversight from the Russian government. Through aggregation, transcription, and metadata curation of the entire lifecycle of Tenet Media's 560 Rumble-hosted podcast episodes, the authors address foundational questions in SSIO research, disinformation campaigns, and alternative media infrastructure.
Background, Context, and Novelty
In response to the U.S. Department of Justice's September 2024 disclosure regarding Russian interference in the U.S. election—most notably through Tenet Media—the authors embarked on a timestamped, archivally-grounded collection of all video content uploaded to Rumble from November 2023 to September 2024. Tenet Media operated as a conventional U.S. media company while covertly channeling Russian financial and editorial power to six established right-wing podcast hosts, shifting from traditional troll-farm approaches to an outsourcing model predicated on leveraging pre-existing influencer credibility rather than synthetic identities.
Unlike previous primary datasets focusing on the Internet Research Agency’s activities (e.g., social botnets, sock puppet accounts, or text-based micro-messaging platforms) [e.g., frommer_twitters_2017, arif_acting_2018], this dataset targets the podcast video medium—an increasingly salient yet understudied vector for SSIO execution [balci_podcast_2024]. The operational locus on Rumble, an alternative platform known for weaker moderation and a predominantly conservative user base, represents further departure from the Twitter/Facebook-centric literature [stocking_role_2022].
Dataset Construction and Methodology
The authors engineered a custom automated scraper to exhaustively harvest:
- All video-level metadata (publication date, title, duration, engagement metrics, tags, host/guest attributions)
- All top-level user comments with engagement signals (likes/dislikes, low-score hidden status)
- Video-level thumbnail and auxiliary links for future multimodal analysis
- Full-length, high-fidelity automatic speech recognition (ASR) transcriptions, leveraging a resource-intensive deployment of the Whisper "large-v2" model on institutional GPU clusters, with subsequent comprehensive manual and computational quality control to identify and mitigate hallucinations and artifacts known from ASR literature [koenecke_careless_2024, mittal_towards_2024].
The curated product encapsulates 560 distinct podcast episodes, 300+ hours of video, comprehensive engagement metrics, and reliable lexical representations, all released in a machine-readable format under open-access licensing, compliant with FAIR standards.
Preliminary Quantitative and Thematic Analysis
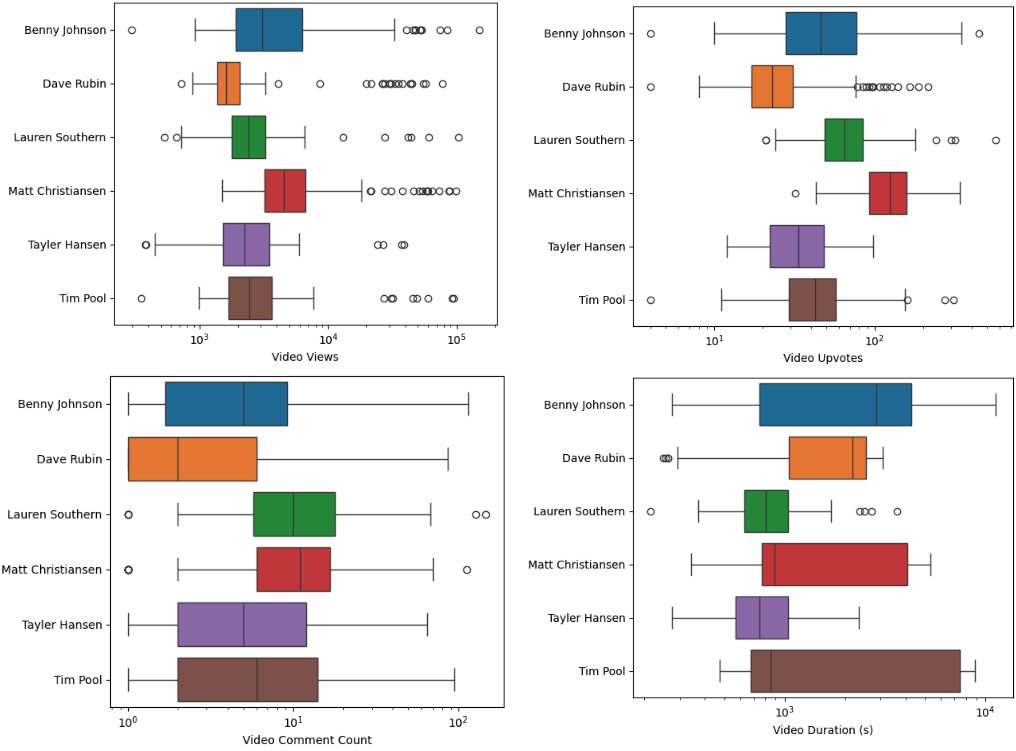
Host-Specific Engagement and Content Properties
The initial analysis underscores substantial host-specific heterogeneity:
These disparities reflect both algorithmic exposure on Rumble and differentiated resonance across political subaudiences.
Most Engaged Content
Thumbnail analysis and summary statistics reveal that the most engaged episodes consistently addressed U.S. presidential politics, migration fearmongering, and right-wing "culture war" topics. For example, "Will Biden Actually Be REPLACED?" and "NYC Hotels TAKEN OVER By Migrants" accrued the highest comment, upvote, and view counts, respectively.

Figure 2: Tenet media videos with top user engagement: a) most viewed video, b) most commented on video, c) most upvoted video, and d) most downvoted video.
Content Modeling and Named Entity Extraction
Named entity extraction from video titles/descriptions and preliminary BERTopic modeling on full transcriptions show a systematic focus on U.S. political figures (Biden, Trump, Kamala Harris), perennial culture war topics (gender, LGBTQ, protest movements), and anti-establishment framing tied to both U.S. and Canadian domestic politics. The dataset’s entity statistics further disambiguate the operational targeting of audience segments and reinforce SSIO content strategy claims.
Transcription-based topic modeling reveals both structural confirmation with metadata (domination by U.S. election and protest narratives) and introduces additional layers around gender rhetoric, anti-LGBTQ content, and social unrest reportage. These findings are concordant with prior research observing SSIO targeting of wedge issues and exploitation of preexisting political fault lines [simchon_troll_2022, linvill_talking_2022].
The release and descriptive baseline provided by this dataset enable multiple research trajectories:
- State-Sponsored Influence Mechanisms: The ‘outsourcing’ of SSIOs to legacy right-wing influencers, rather than anonymous inauthentic accounts, suggests a maturation in Russian information operations toward more covert, plausible, and scalable models of influence—demanding corresponding shifts in detection and countermeasure methodologies [polychronis_working_2023].
- Alternative Media Platform Risk: The persistence of Tenet Media content on Rumble (after YouTube’s prompt channel removal) exemplifies both the regulatory risk and research opportunity embedded in alternative social media infrastructures, which have become preferred hosts for disinformation campaigns post-deplatforming [balci_dataset_2024].
- Podcast Medium: The dataset’s scale and fidelity represent the first systematic resource for studying video-based SSIO strategies at the content, audience, and engagement levels—a vector previously underexamined relative to text and microblogging platforms [litterer_mapping_2024].
- Engagement Patterns and Algorithmic Vulnerability: The fine-grained engagement data (views/upvotes/comments) allow for empirical study of algorithmic amplification, feedback loops, and user participation in platform-specific contexts, expanding on prior work on content virality and the illusory truth effect [udry_illusory_2024].
- Detection and Countermeasure Research: The high-quality transcriptions can catalyze further research in computational linguistics, rhetorical analysis of SSIO messaging, and the impact of multimodal content (audio/video/thumbnails) on persuasion and belief formation.
Limitations
The dataset’s engagement signal is timestamped (December 2024), and the authors acknowledge residual ASR transcription artifacts, especially in non-dialogic protest footage. Nonetheless, the systematic validation and remediation pipeline mitigate most core reliability threats.
Conclusion
This work provides a crucial, multimodal, open-access dataset for the empirical study of modern, outsourced SSIOs on underregulated alternative video platforms, through the lens of high-credibility paid influencers. Its release marks a significant expansion—both methodological and theoretical—for research into the evolving strategies of state actors in digital information warfare, with meaningful consequences for the future design of detection, auditing, and platform governance in social media ecosystems.