- The paper introduces a novel Re4 method integrating reranking-based retrieval and RLFT to optimize functional test script generation.
- It leverages a structured CBR system that maps test intent to functionally equivalent scripts using a refined 4R cycle.
- Experimental results show improved precision, recall, and reduced repetitive generation, enhancing overall testing efficiency.
Optimizing Case-Based Reasoning System for Functional Test Script Generation with LLMs
Introduction
The paper presents a novel approach that leverages LLMs to generate functional test scripts, optimizing a Case-Based Reasoning (CBR) system. This system utilizes a structured case bank and a 4R cycle (Retrieve, Reuse, Revise, Retain) to generate scripts by mapping test intents to functionally equivalent code. The proposed optimization method, Re4, aims to enhance the capabilities of LLMs by introducing reranking-based retrieval finetuning and reinforced reuse finetuning, providing a robust mechanism for improving script generation quality.
Case-Based Reasoning System
In this research, the CBR framework is employed to improve the efficiency of test script generation, a crucial aspect of functional testing. The framework facilitates analogical reasoning by utilizing a case bank that maps test intent descriptions to corresponding test scripts. This is achieved through the classic 4R cycle: Retrieve similar cases, Reuse them to propose a new solution, Revise the solution, and Retain the improved case for future use. The methodological innovation here lies in the integration of LLMs for the Reuse step, enabling more dynamic and context-aware script generation.
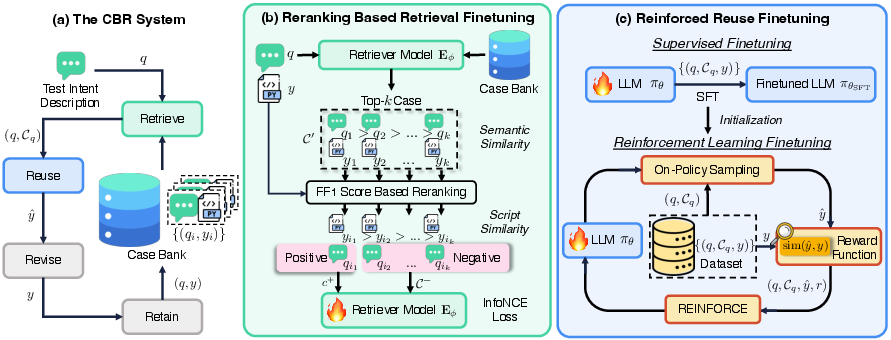
Figure 1: The overall paradigm of the proposed CBR+Re4 for functional test script generation with LLMs: (a) The CBR system; (b) Reranking-based retrieval finetuning; (c) Reinforced reuse finetuning.
Re4 Optimization Method
Reranking-Based Retrieval Finetuning
The Retrieve step is crucial for identifying useful past cases from the case bank. This paper introduces a reranking-based retrieval finetuning method that enhances the retriever model by using pseudo-labels generated via contextually aware reranking. This approach identifies cases with high semantic and script similarity, optimizing the retriever model to better align with the test intent descriptions.
Reinforced Reuse Finetuning
The Reuse step is optimized using a combination of Supervised Finetuning (SFT) and Reinforcement Learning Finetuning (RLFT). The RLFT uses a critic-free online learning approach, REINFORCE, to align LLM outputs with desired script generation behaviors without introducing the noise that SFT might. This strategy mitigates the risk of hallucination by ensuring that generation aligns with the retrieved functions while rewarding precision in function usage.
Experimental Results
The experimental evaluation conducted across datasets from Huawei Datacom demonstrated significant improvements over baseline methods. The CBR+Re4 system outperformed naive approaches and previous bests such as CBR+SFT in terms of function F1 score, precision, and recall.
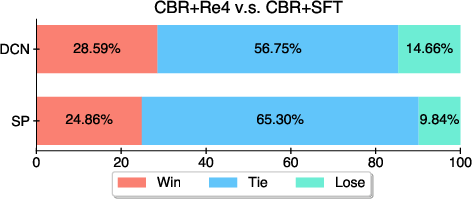
Figure 2: Comparison between CBR+Re4 and CBR+SFT. The win, tie, and lose rates are evaluated by humans.
Discussion of Repetitive Generation Issues
A notable advantage of the proposed optimization is its ability to reduce repetitive generation issues—a common problem observed in generated scripts, where test scripts would redundantly invoke the same functions. By refining alignment through the RLFT stage, the approach penalizes such behaviors, significantly enhancing user experience and system efficiency.
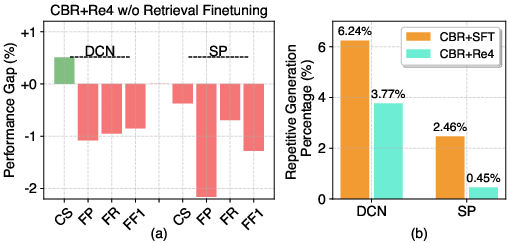
Figure 3: (a) Performance gap in an ablation study of CBR+Re4 w/o retrieval finetuning. (b) Repetitive generation percentage of different methods.
Conclusion
The CBR system optimized with the Re4 method harnesses the capabilities of LLMs to improve functional test script generation, addressing challenges related to script alignment, retrieval precision, and repetitive generation. This work not only exemplifies a significant advancement in utilizing AI for software testing but also opens avenues for further research into optimizing LLMs in dynamic and evolving contexts. Continued exploration is anticipated to finetune LLMs' interactions with case-based systems and improve their adaptiveness in real-world software testing scenarios.