- The paper introduces DSDBench, a benchmark that evaluates LLMs in handling complex multi-hop and multi-bug errors in data science code.
- It details a methodology using synthetic error injection and performance metrics such as precision, recall, F1-score, and accuracy.
- Experimental results reveal that while some models perform well on simpler errors, multi-bug scenarios significantly challenge current debugging capabilities.
Why Stop at One Error? Benchmarking LLMs as Data Science Code Debuggers for Multi-Hop and Multi-Bug Errors
Introduction
This paper addresses a critical aspect of software development: debugging. Recent advances in LLMs have propelled their use in automating tasks like code generation and debugging. However, existing benchmarks often focus on syntactic correctness in simple, single-error scenarios, lacking the complexity of real-world applications. The authors introduce DSDBench, a novel benchmark designed to evaluate LLMs in dynamic debugging environments where multi-hop and multi-bug errors are prevalent in data science.
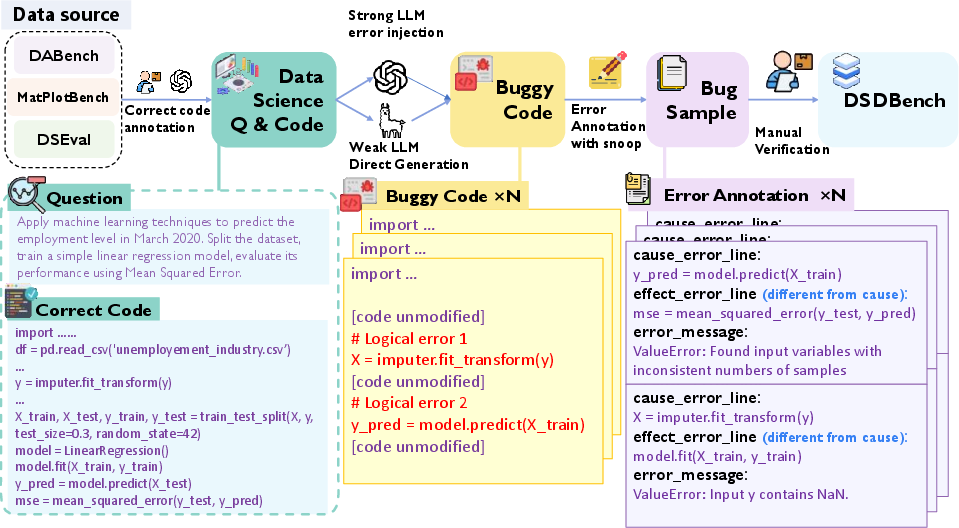
Figure 1: Dataset construction pipeline of DSDBench.
DSDBench Construction
DSDBench is meticulously crafted to evaluate the debugging capabilities of LLMs, targeting data science workflows where bugs often span multiple lines and errors co-occur. The benchmark is built on datasets from existing data science benchmarks, supplemented with synthetic error injections to create realistic multi-error scenarios.
Through automated error injection, utilizing both strong and weak LLMs for diversity, DSDBench incorporates a wide range of error types relevant to data science, including runtime errors from incorrect data manipulations and misuses of popular libraries like pandas and sklearn. The dataset is designed to require models to identify both the source (cause) and manifestation (effect) of errors, demanding comprehensive reasoning over code execution flows.
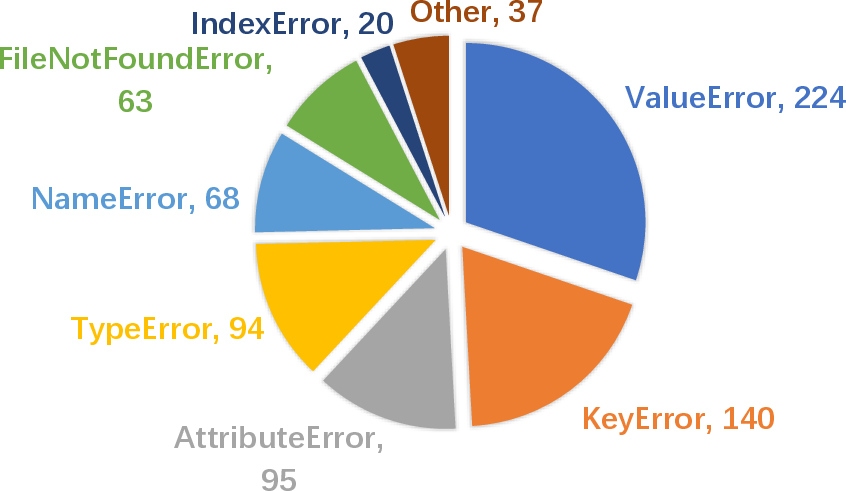
Figure 2: Distribution of different error types. Details of error types are described in Appendix \ref{app:error_type}.
The core tasks DSDBench focuses on are multi-hop error tracing and multi-bug error detection. These tasks require LLMs to not only identify where errors manifest but also trace back to their origins, which can involve following logical dependencies across several lines of code. This challenge is heightened in multi-bug contexts where independent errors interact, making debugging far more complex than isolated error handling.
Evaluation Metrics
DSDBench uses precision, recall, F1-score, and accuracy to evaluate performance across four dimensions: cause line, effect line, error type, and error message. The semantic understanding of error messages is especially critical, as exact string matching is insufficient for capturing the nuanced understanding needed for debugging.
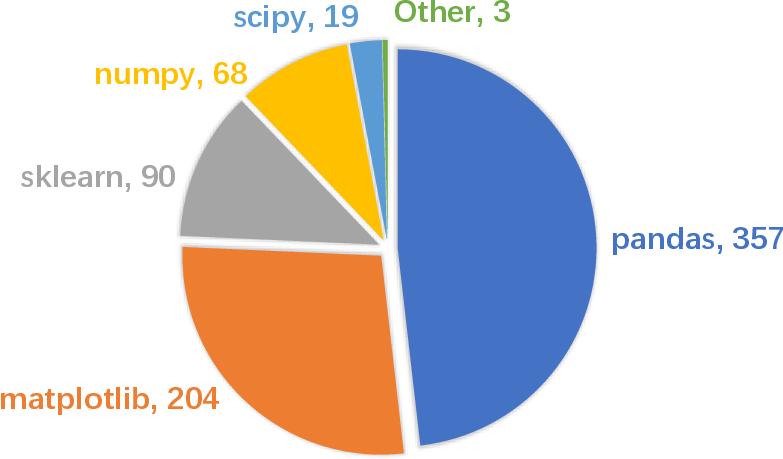
Figure 3: Distribution of different data science libraries.
Experimental Results
The evaluation of various LLMs and LRMs on DSDBench reveals significant gaps in current models' abilities to handle dynamic debugging tasks. While models like DeepSeek-V3 show promise in single-bug scenarios, their performance drops sharply in multi-bug contexts, highlighting the complexity of these tasks.
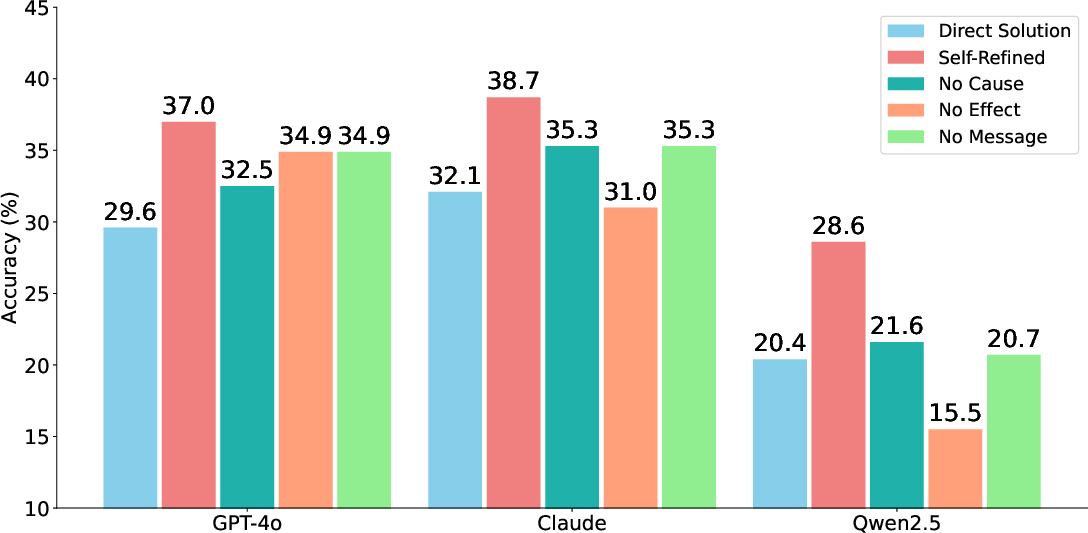
Figure 4: Impact of Self-Refinement.
Despite advancements, many models exhibit a notable deficiency in tracing the execution flow accurately to detect effect lines, with multi-hop errors posing substantial challenges. The introduction of self-refinement techniques shows potential in improving models' debugging capabilities by leveraging identified error lines to guide corrective actions.
Conclusion
DSDBench provides a critical advancement in the evaluation of LLMs for complex, real-world debugging scenarios in data science. By focusing on multi-hop and multi-bug errors, it addresses a previously underserved area, paving the way for more reliable AI-assisted coding tools. Moving forward, the insights from DSDBench can inform the development of more robust models capable of handling the intricate demands of real-world software debugging.
This benchmark sets a new standard in evaluating LLMs' ability to understand and debug complex systems, challenging the field to bridge the evident gap between generation and understanding in AI-assisted programming.