- The paper's main contribution is developing MGR-LF++, an enhanced late fusion approach integrating contrastive modality alignment and special tokens.
- It presents a detailed GR pipeline that generates semantic IDs from multimodal data, addressing challenges like modality sensitivity and correspondence.
- Empirical results demonstrate that MGR-LF++ outperforms traditional methods by over 20% in metrics such as MRR, NDCG, and Hits@5.
Generative Recommendation with Multimodal Semantics
Introduction to Multimodal Generative Recommendation
The paper "Beyond Unimodal Boundaries: Generative Recommendation with Multimodal Semantics" explores how generative recommendation (GR) systems can be enhanced through the use of multimodal semantics to address the limitations of handling unimodal content (2503.23333). The study investigates the Multimodal Generative Recommendation (MGR) problem, emphasizing the influence of modality choices on the efficacy of GR models.
Traditional GR models utilize semantic IDs based on unimodal data, often resulting in information loss due to the diversity in real-world data. The paper demonstrates that integrating multimodal data can significantly enhance recommendation accuracy, providing a robust framework for combining different types of data in recommendation systems.
Generative Recommendation Pipeline
The authors introduce a typical GR pipeline, outlining key stages like Semantic ID Generation and Sequential Recommendation. In the former, item content features are encoded to produce semantic IDs — these are utilized to represent items in the sequential recommender.
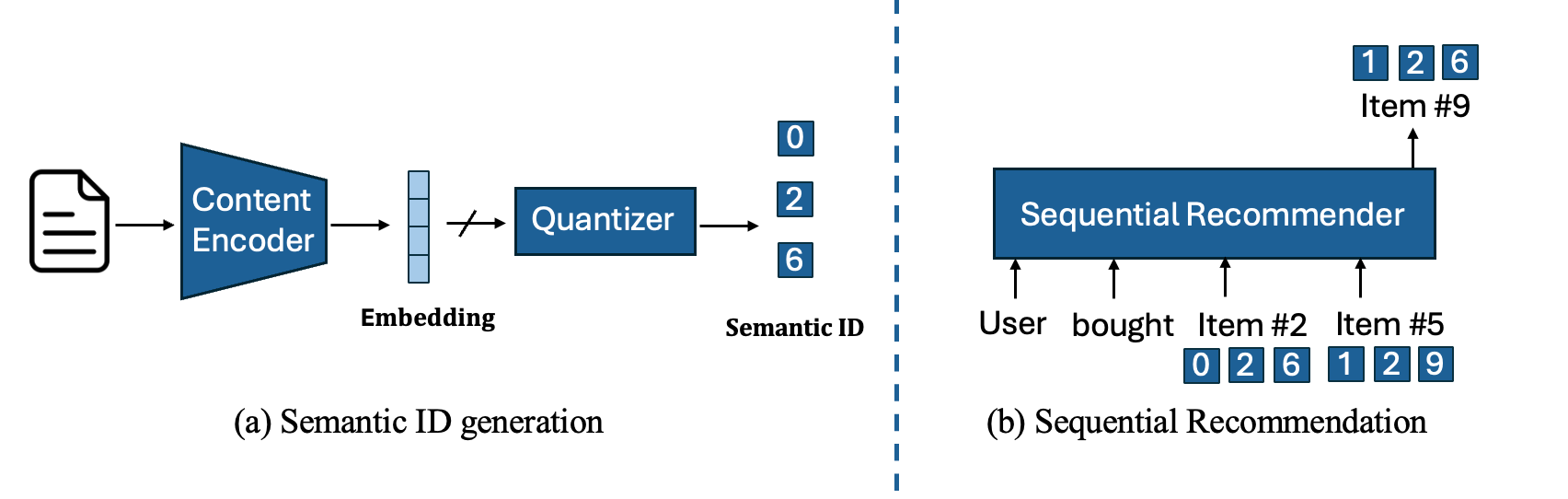
Figure 1: Overview of a Typical Generative Recommendation Pipeline. (a) Each item's semantic ID is generated as a list of discrete IDs based on its content. (b) These generated semantic IDs are then used to represent items within the sequential recommender.
Challenges in Multimodal Generative Recommendation
Modality Sensitivity
A significant challenge identified by the authors is modality sensitivity in GR systems. When modalities such as text and images are fused (early fusion), one tends to dominate, leading to information loss. This is exemplified by how generated semantic IDs might fail to preserve distinctions between visually or textually similar items, negatively impacting recommendation performance.
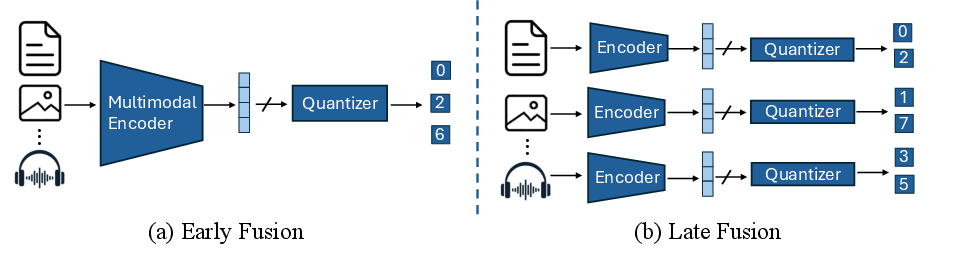
Figure 2: Naive strategies for extending unimodal generative recommendation to multimodal scenarios. Early fusion (MGR-EF) generates a unified list of semantic IDs capturing the semantics across all modalities. Late fusion (MGR-LF) generates separate semantic IDs for each modality and combines them after generation.
Modality Correspondence
In contrast, late fusion approaches generate separate semantic IDs per modality but face challenges in aligning semantic IDs across different modalities. This lack of correspondence can degrade performance significantly since the model struggles to match IDs between modalities effectively.
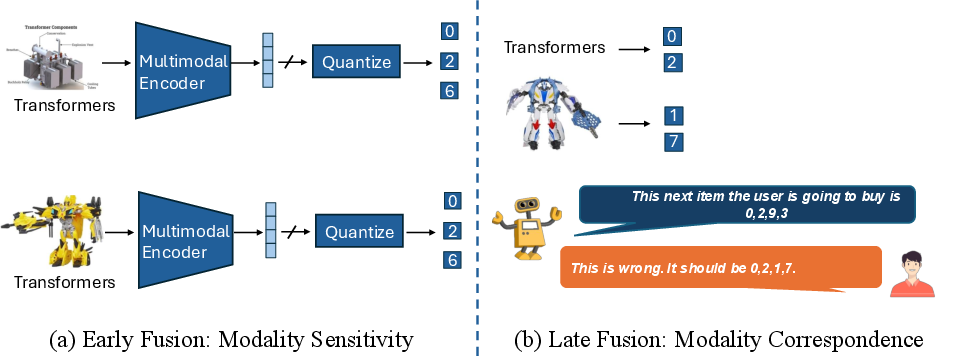
Figure 3: Key challenges in the MGR problem. (a) Modality Sensitivity results in information loss. (b) Modality Correspondence failure in mapping semantic IDs across modalities.
Proposed Solution: MGR-LF++
To address these issues, the authors propose MGR-LF++, an enhanced late fusion framework that integrates:
- Contrastive Modality Alignment: This training paradigm aligns semantic IDs across modalities, enhancing the ability of the model to maintain consistent representations.
- Special Tokens: These tokens denote modality transitions, aiding the autoregressive model in maintaining separate modality-specific information while predicting future recommendations.
Empirical Analysis and Results
The experimental results demonstrate significant improvements, with MGR-LF++ outperforming other methods by greater than 20% in sequential recommendation metrics like MRR, NDCG, and Hits@5.
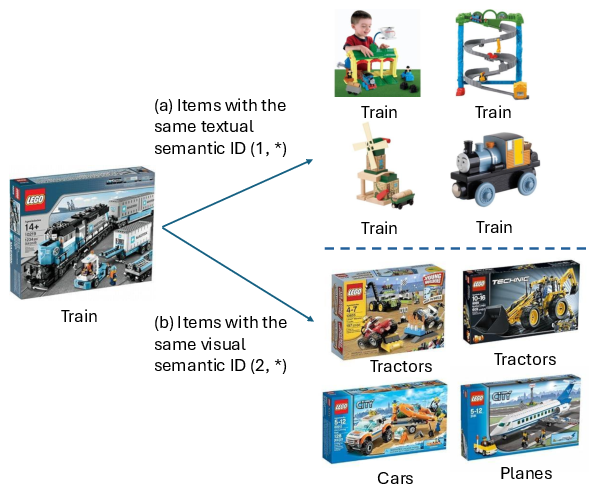
Figure 4: Semantic IDs per modality capture different information, highlighting the need for multimodal approaches.
Conclusion
The findings illuminate the potential for GR systems to harness multimodal data more effectively. By addressing challenges like modality sensitivity and correspondence, the proposed MGR-LF++ framework substantially improves recommendation accuracy. This work provides a foundation for further exploration into multimodal systems, advancing both practical applications and theoretical understandings in the field of AI.
The paper paves the way for subsequent research to develop even more balanced early fusion strategies and larger datasets that incorporate additional modalities beyond text and images. These advancements could push the boundaries of generative recommendation systems, providing more personalized and context-aware user experiences.
Overall, the discussion and results underscore the necessity for continued investigation into multimodal integrations within GR systems to fully capitalize on their potential benefits.