Medical Reasoning in LLMs: An In-Depth Analysis of DeepSeek R1
Abstract: Integrating LLMs like DeepSeek R1 into healthcare requires rigorous evaluation of their reasoning alignment with clinical expertise. This study assesses DeepSeek R1's medical reasoning against expert patterns using 100 MedQA clinical cases. The model achieved 93% diagnostic accuracy, demonstrating systematic clinical judgment through differential diagnosis, guideline-based treatment selection, and integration of patient-specific factors. However, error analysis of seven incorrect cases revealed persistent limitations: anchoring bias, challenges reconciling conflicting data, insufficient exploration of alternatives, overthinking, knowledge gaps, and premature prioritization of definitive treatment over intermediate care. Crucially, reasoning length correlated with accuracy - shorter responses (<5,000 characters) were more reliable, suggesting extended explanations may signal uncertainty or rationalization of errors. While DeepSeek R1 exhibits foundational clinical reasoning capabilities, recurring flaws highlight critical areas for refinement, including bias mitigation, knowledge updates, and structured reasoning frameworks. These findings underscore LLMs' potential to augment medical decision-making through artificial reasoning but emphasize the need for domain-specific validation, interpretability safeguards, and confidence metrics (e.g., response length thresholds) to ensure reliability in real-world applications.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
This paper looks at how a very advanced AI, called DeepSeek R1, “thinks” through medical problems. The big question is: does the AI’s step‑by‑step reasoning look like what real doctors do, and can we trust it? The authors study both the AI’s final answers and the way it explains its thinking to see where it does well and where it makes mistakes.
What the researchers wanted to find out
They set out to answer a few clear questions:
- Can DeepSeek R1 solve medical test questions accurately?
- Does its reasoning look like a doctor’s reasoning (for example, weighing clues, comparing options, and following medical rules)?
- What kinds of mistakes does it make, and are those mistakes similar to common human thinking errors?
- Is there a simple signal that tells us when the AI might be less reliable (like when its explanation is unusually long)?
How they tested the AI
They used 100 medical questions from a respected exam-style dataset (MedQA). These questions are like mini patient stories that ask for the best diagnosis or next step in treatment.
What they did:
- They asked DeepSeek R1 to answer each question and to show its step‑by‑step thinking.
- A medical doctor read the AI’s reasoning to judge if it made sense and matched how clinicians think.
- The team checked which answers were right or wrong, looked for patterns in the mistakes, and also measured how long the AI’s explanations were.
- They compared explanation lengths for right vs. wrong answers to see if length could predict reliability.
Simple analogy: Think of the AI as a “medical detective.” The researchers didn’t just grade the final guess—they also looked at the detective’s notes to see how it got there.
What they found and why it matters
Overall performance:
- The AI got 93 out of 100 questions correct. That’s high accuracy.
What its good reasoning looked like:
- It often behaved like a trained clinician: it gathered clues, made a shortlist of possible diagnoses, compared treatments, followed guidelines, and tailored choices to the patient.
Patterns in the 7 error cases: The authors noticed common thinking mistakes. Below is a short list to make them easy to spot.
Here are the main error types the AI showed:
- Anchoring: Sticking too hard to the first idea and ignoring new evidence.
- Trouble handling conflicting data: Not fitting all the clues together.
- Narrow focus: Not considering enough alternative diagnoses.
- Overthinking: Getting lost in details and missing the simple, correct step.
- Skipping steps: Jumping to a final treatment and missing an important immediate step (like starting blood thinners before surgery).
- Misreading labs or mixing up facts: For example, confusing how two similar enzymes behave.
- Cause–effect mix‑ups: Treating a consequence like it was the original cause.
A rare but important glitch:
- In one case, the AI’s reasoning pointed to the correct choice, but the final answer it output was different and wrong. This shows why seeing both the reasoning and the final answer can be helpful—if doctors can view the notes, they might catch such mismatches.
A simple reliability signal:
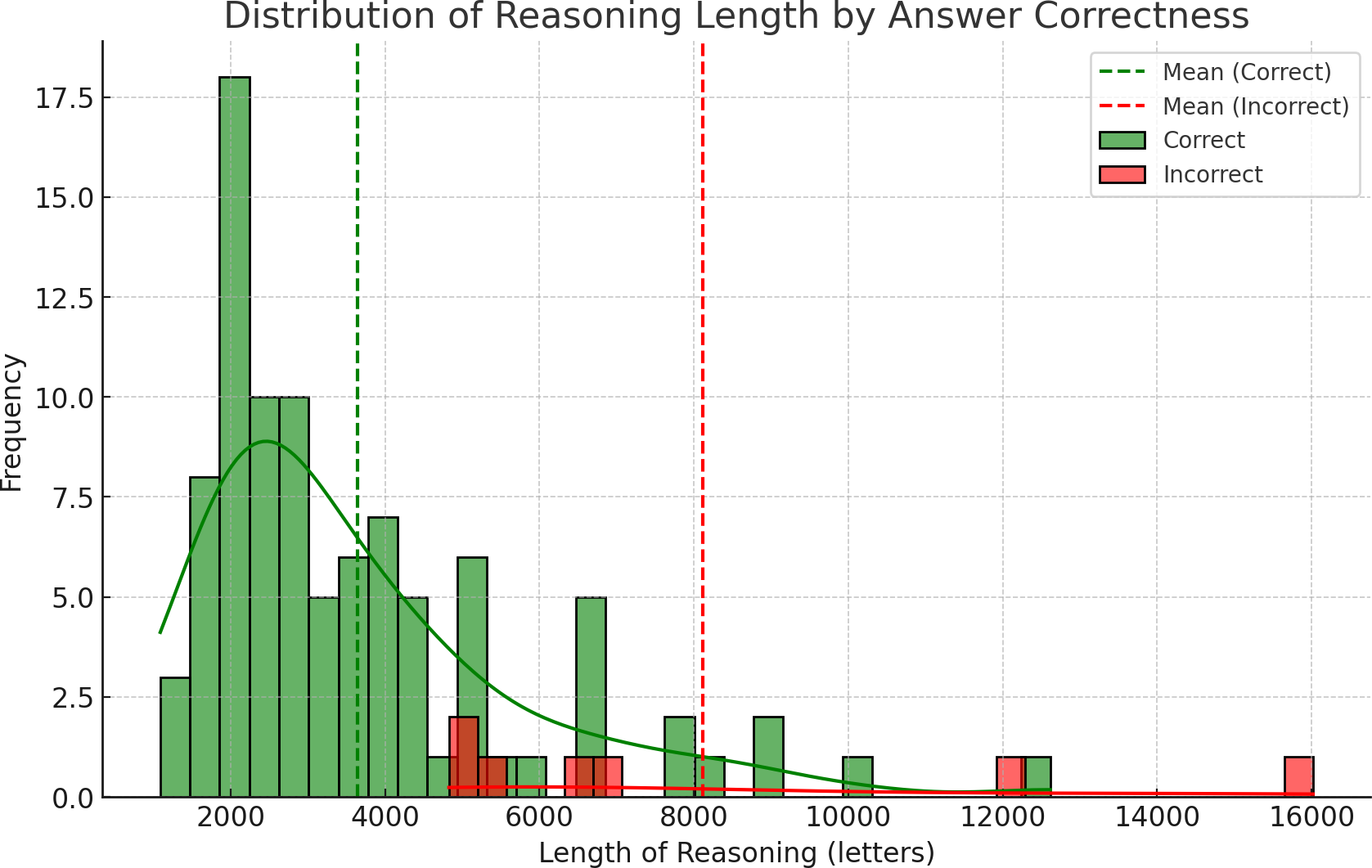
- Wrong answers tended to come with very long explanations. On average, incorrect explanations were more than twice as long as correct ones.
- Shorter explanations (under about 5,000 characters) were usually right. In other words, very long write‑ups can be a warning sign that the AI is uncertain or talking itself into a bad answer.
Why these results matter:
- High accuracy plus understandable reasoning is good news for using AI as a support tool in healthcare.
- Knowing the AI’s typical mistakes helps doctors watch out for them.
- A quick, practical rule of thumb (very long explanation = be cautious) could make AI help safer to use.
What this could mean for the future
- Safer decision support: Because DeepSeek R1 shows its steps, doctors can check how it arrived at a suggestion. This helps reduce the “black box” feeling and can catch errors before they affect patients.
- Training and improvement: The specific mistake patterns give engineers a roadmap to improve the AI (for example, adding trusted medical guidelines during reasoning or fine‑tuning the model on medical logic).
- Helping clinicians learn: The AI’s reasoning could also be a teaching tool for medical students and doctors, showing solid approaches and common pitfalls to avoid.
- Human in the loop: The AI is not perfect and shouldn’t replace doctors. But as a careful assistant—especially one that flags its own uncertainty—it could help clinicians work faster and more safely.
- Simple safety cue: If the AI’s explanation is unusually long, treat it as a yellow light—double‑check or ask it to be concise and try again.
In short: DeepSeek R1 is impressively accurate and often reasons like a doctor, but it can still make human‑like thinking mistakes. Showing its reasoning makes it easier to trust, audit, and improve. With human oversight and continued training, tools like this could become valuable partners in medical care.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps and unanswered questions that future work could address.
- External validity: Does performance and “reasoning quality” transfer from MedQA multiple-choice vignettes to real-world clinical workflows (free-text notes, labs/imaging, incomplete information, time pressure, interruptions, team dynamics)?
- Dataset scope: How does the model perform on substantially larger, more representative, and longitudinal case corpora (e.g., EHR-derived cases, multi-turn encounters, multi-morbidity), beyond n=100 MedQA items?
- Specialty and case-mix effects: Are accuracy and reasoning patterns consistent across specialties, case difficulty, acuity, and ambiguity levels (subgroup analyses and power are missing)?
- Non-English and cross-jurisdictional validity: Do results generalize across languages and region-specific guidelines, where medical standards and terminology differ?
- Temporal validity: How sensitive is reasoning to guideline drift and knowledge updates (time-stamped ground truth, temporal robustness)?
- Contamination risk: To what extent is MedQA content (or near-duplicates) present in training data, and how would decontamination change accuracy and observed “reasoning”?
- Comparative baselines: How does DeepSeek R1 compare to other reasoning/non-reasoning LLMs, earlier DeepSeek variants, and simple heuristics or retrieval baselines under identical conditions?
- Ablations: Which training components (reasoning RL, cot fine-tuning, MoE routing) contribute causally to medical reasoning quality versus answer accuracy?
- Prompt sensitivity: How robust are results to prompt variants (system/instruction phrasing, few-shot exemplars, checklist prompts, self-critique), and which strategies reduce specific error types?
- Sampling and decoding: What is the effect of temperature, top-p, and self-consistency (multi-sample majority vote) on both accuracy and reasoning errors; are gains consistent across specialties?
- Replicability: Are results stable across multiple runs/seeds and API versions; what is the within-item variance in answers and rationales?
- Reasoning-output mismatch: How often does the model’s internal chain-of-thought conclude the correct answer while the final output is wrong (as observed once), and can we detect/mitigate this reliably?
- Faithfulness of explanations: Are reasoning tokens causally faithful to the model’s internal decision process or post-hoc rationalizations (e.g., via input attribution, deletion/insertion tests, causal scrubbing)?
- Human evaluation reliability: With only one clinician annotator, what is the inter-rater reliability of error typologies and bias labels; how do conclusions change with multiple blinded expert raters and adjudication?
- Error taxonomy validity: Are the mapped “cognitive biases” stable, reproducible across prompts/runs, and predictive of future failures; can a standardized coding scheme be validated?
- Severity and safety impact: What is the clinical harm potential of each error class (near-miss vs severe), and how often would a human-in-the-loop detect and correct them in practice?
- Calibration and confidence: Beyond length of reasoning, which confidence signals (log-probabilities, entropy, disagreement across samples, self-rated certainty) best predict correctness and are they well-calibrated?
- Length-as-uncertainty generalization: Does the proposed 5,000-character threshold generalize across datasets, models, prompts, and languages; can it be combined with other signals into a robust risk triage?
- Statistical rigor: With only seven incorrect cases, are parametric tests appropriate; what are effect sizes, confidence intervals, and non-parametric/bootstrapped validations?
- Confounding by question length/difficulty: Does longer reasoning simply reflect longer or harder prompts; analyses controlling for prompt length, complexity, and specialty are missing.
- Task breadth: How does the model perform on open-ended tasks (free-text differential, test selection, management plans), multi-step protocols, and documentation quality (e.g., plan justification, citations)?
- Multi-modal reasoning: Can the model reliably integrate imaging, waveforms, pathology slides, and structured labs; how do reasoning errors change with multi-modal inputs?
- Interaction design: How do multi-turn clarifying questions change accuracy and bias patterns; can the model learn to request missing information safely and efficiently?
- Mitigation strategies: Do targeted interventions (checklists, protocol-enforcement prompts, bias inoculation, tool use, RAG with current guidelines) reduce specific recurring errors (anchoring, protocol violations)?
- RAG efficacy: Which sources (guidelines, pathways, pharmacology databases) and retrieval strategies measurably improve reasoning fidelity without increasing hallucinations?
- Training interventions: Does fine-tuning on curated “reasoning with feedback” datasets or reinforcement learning from clinician preferences reduce bias classes and improve adherence to protocols?
- Consistency checks: Can automated validators (reasoning-output agreement, guideline conformance, unit checks, drug-dosing bounds) reduce unsafe recommendations before output is shown to clinicians?
- Human-AI teaming: Do reasoning traces actually enhance clinician performance, trust calibration, and cognitive load; what UI/UX designs optimize oversight and error detection in simulated and real settings?
- Benchmark design: Can we develop benchmarks that score both answer correctness and reasoning quality (factuality, guideline alignment, completeness, causal coherence) with transparent rubrics?
- Cost, latency, and deployment: What are the computational and latency trade-offs of reasoning models in clinical settings, especially on-prem; are smaller distilled models comparably safe?
- Privacy and governance: How can reasoning traces be handled to avoid PHI leakage; what auditability, logging, and access controls are required for compliance (e.g., GDPR/HIPAA, EU AI Act)?
- Regulatory readiness: What post-market surveillance, update policies, and risk management frameworks are needed for deployment of reasoning LLMs in high-risk care contexts?
- Fairness and bias: How do reasoning and errors vary across patient demographics and social determinants; are there systematic disparities in recommendations or attributions?
- Robustness to adversarial inputs: Are reasoning and outputs stable under subtle prompt perturbations, adversarial examples, or misleading but realistic chart artifacts?
- Longitudinal learning: Can the system adapt to local protocols and outcomes (continual learning) without catastrophic forgetting or privacy risks?
- Transparency of configurations: Exact model versioning, decoding parameters, and prompt templates are not fully specified for reproducibility; a detailed release of code, prompts, and seeds is needed.
Collections
Sign up for free to add this paper to one or more collections.