- The paper demonstrates that integrating multiple large vision encoders via distillation yields an average 2% improvement in the Dice coefficient for VFSS segmentation.
- It employs a novel multi-teacher framework using MLP-based and attention-based loss balancing to optimize feature integration and reduce model complexity.
- The proposed method effectively aggregates specialized expertise from individual medical models, achieving improved segmentation accuracy with efficient inference.
Agglomerating Large Vision Encoders via Distillation for VFSS Segmentation
This essay provides an authoritative overview of a novel framework designed to enhance medical image segmentation by distilling knowledge from multiple large vision encoders. This approach promises a compelling trade-off between model complexity and performance across various segmentation tasks.
Introduction
The introduction of foundation models in medical imaging has demonstrated notable success in segmentation tasks. However, these models often suffer from significant training overheads and inference complexity due to their large encoder size. To address this, lightweight variants of these models have been explored, but they frequently encounter limitations in model capacity and suboptimal training methodologies.
The paper proposes an innovative framework leveraging multi-model knowledge distillation from specialized medical foundation models like MedSAM, RAD-DINO, and MedCLIP. Each model contributes distinct expertise, allowing the resultant agglomerated model to effectively generalize across numerous tasks without the need for explicit retraining for each one. The approach yields an average performance enhancement of 2% in Dice coefficient compared to standard distillation techniques.
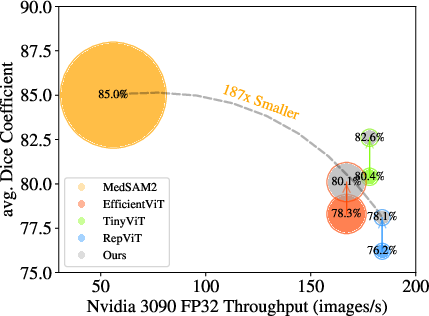
Figure 1: Efficient models have shown performance discrepancies compared to fine-tuned foundation model (MedSAM) during distillation; our approach enhances performance without introducing extra parameters. The size of the circles represents the model size.
Methodology
The framework illustrated in (Figure 2) emphasizes an encoder-decoder architecture facilitating feature integration from multiple teacher models. The encoder is designed to distill comprehensive representations from various pretrained expert models, whereas the decoder processes these representations using SAM's schema to maintain lightweight efficiency.
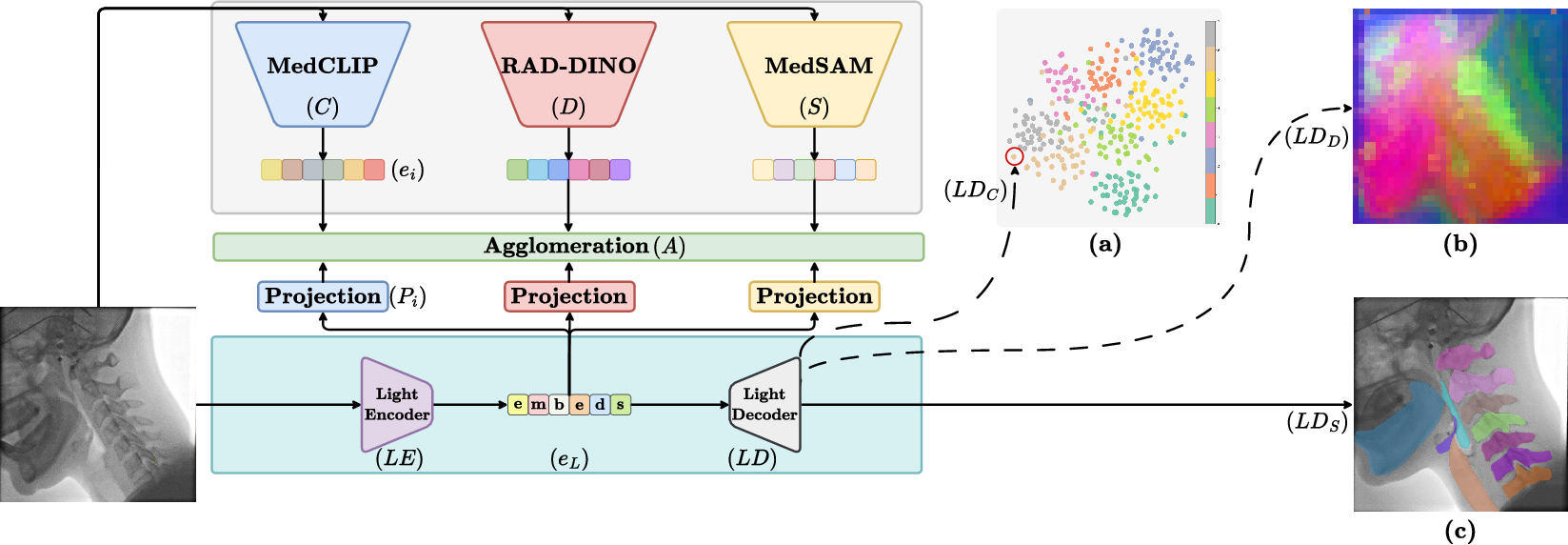
Figure 2: The teacher models' features are agglomerated into student features. The learned representations can be decoded by multiple Light Decoders (LD) for general tasks: (a) Clustering visualization, (b) PCA visualization, and (c) SAM-decoded Instance Segmentation.
Multi-Model Agglomeration via Distillation
The framework employs a multi-teacher distillation approach, where features are extracted from input images by various teacher models. The student model learns to project these distinct teacher embeddings into its feature space using specific heads. Loss functions are balanced using either MLP-based or attention-based strategies that adaptively weight contributions from each teacher model during distillation.
Agglomeration Strategies
Two distinctive loss balancing mechanisms are introduced: MLP-based and attention-based. These methods aim to ensure effective knowledge integration from the diverse outputs of teacher models, thereby maximizing the student model's performance in segmentation tasks. Feature normalization is employed to mitigate variations in embedding scales among different teacher models.
Results and Discussion
An empirical comparison (Table 1) reveals that the distilled models, leveraging the agglomeration strategies, achieve superior performance with significantly reduced model complexity compared to conventional and specialist models. The attention-based strategy demonstrates a substantial improvement in the Dice coefficient while maintaining minimized additional training parameters.
Furthermore, an ablation study (Table 2) affirms the efficacy of employing MedCLIP as an encoder in conjunction with other vision models, emphasizing its useful contribution even with high similarity in the training dataset.
Conclusion
In conclusion, the proposed multi-model agglomeration distillation framework significantly advances medical image segmentation by seamlessly integrating expertise from various specialized large models into an efficient student model. This methodological innovation not only enhances segmentation accuracy but also ensures rapid inference capabilities. Future research could explore further applications in diverse medical imaging datasets and investigate sequential teacher embeddings for specific task training.
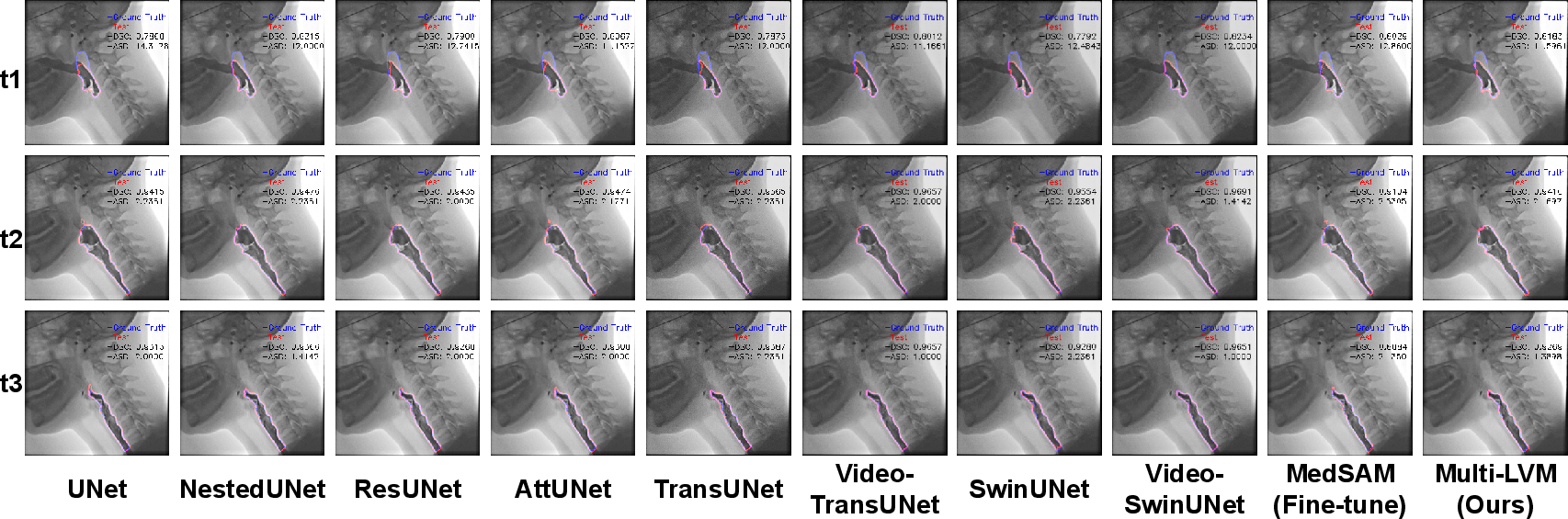
Figure 3: Qualitative results on Pharynx Segmentation comparing Specialist Models to foundation models and our multi-encoder distilled model. The lightweight model evaluated is TinyViT.