- The paper introduces a transparent RL framework built from scratch that simplifies the training of vision-language models.
- It outlines a clear four-step process including data flow, response collection, trajectory generation, and a PPO-based policy update.
- Experimental results demonstrate that RL outperforms supervised fine-tuning by boosting generalization and reflective reasoning in multimodal tasks.
Rethinking RL Scaling for Vision LLMs: A Transparent Framework and Comprehensive Evaluation
The paper "Rethinking RL Scaling for Vision LLMs: A Transparent, From-Scratch Framework and Comprehensive Evaluation Scheme" (2504.02587) introduces a new framework for applying reinforcement learning (RL) to vision-LLMs (VLMs). Existing approaches to RL in VLMs often rely on complex, engineered systems which hinder reproducibility. This paper proposes a transparent, from-scratch framework with a standardized evaluation scheme to address these issues.
Introduction
Reinforcement learning has been previously applied to LLMs to enhance reasoning capabilities, a practice now extended to VLMs. The primary contribution of this paper is the introduction of a simple, reproducible RL framework built from scratch, using standard libraries. The framework is designed to help both new and experienced researchers understand and participate in RL-based VLM research by providing a clear, accessible baseline.
Framework
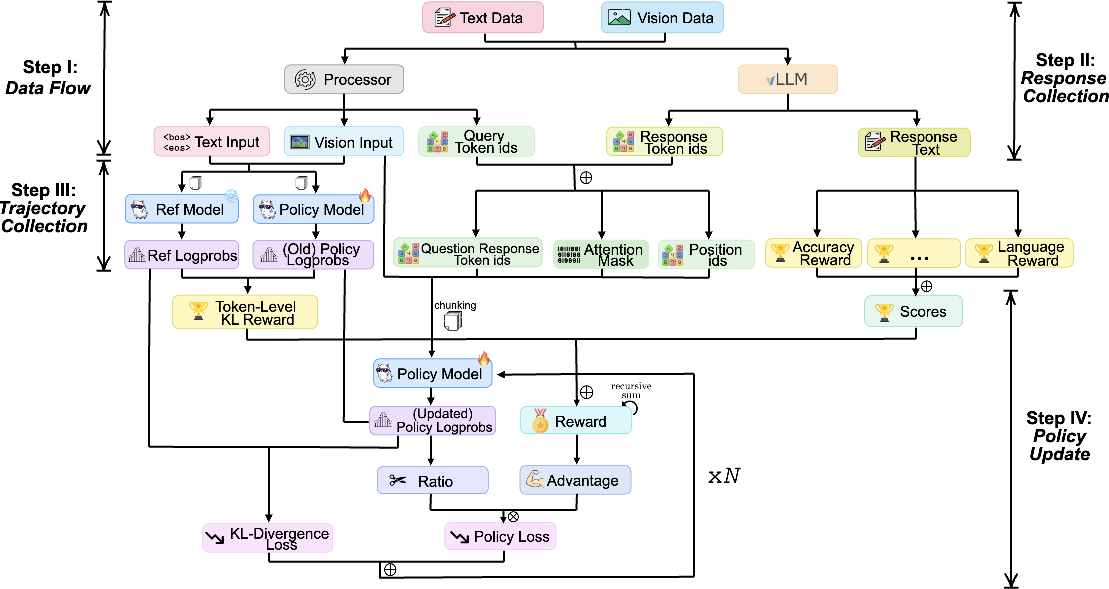
Figure 1: Overview of Maye framework. The process is divided into four steps. Each step integrates various components, including text and vision data, policy models, and reward signals.
The proposed framework is divided into four main steps:
- Data Flow: The process starts with input data processing, converting raw text and visual data into model-friendly formats.
- Response Collection: The next step involves generating responses using the VLM in a structured and efficient manner.
- Trajectory Generation: This involves collecting necessary information to perform RL updates, including rewards and policy gradients.
- Policy Update: Finally, the policy is updated using a variant of the PPO algorithm, ensuring effective learning.
Evaluation Scheme
A comprehensive evaluation scheme is also introduced, addressing the challenges of measuring RL performance in the context of VLMs.
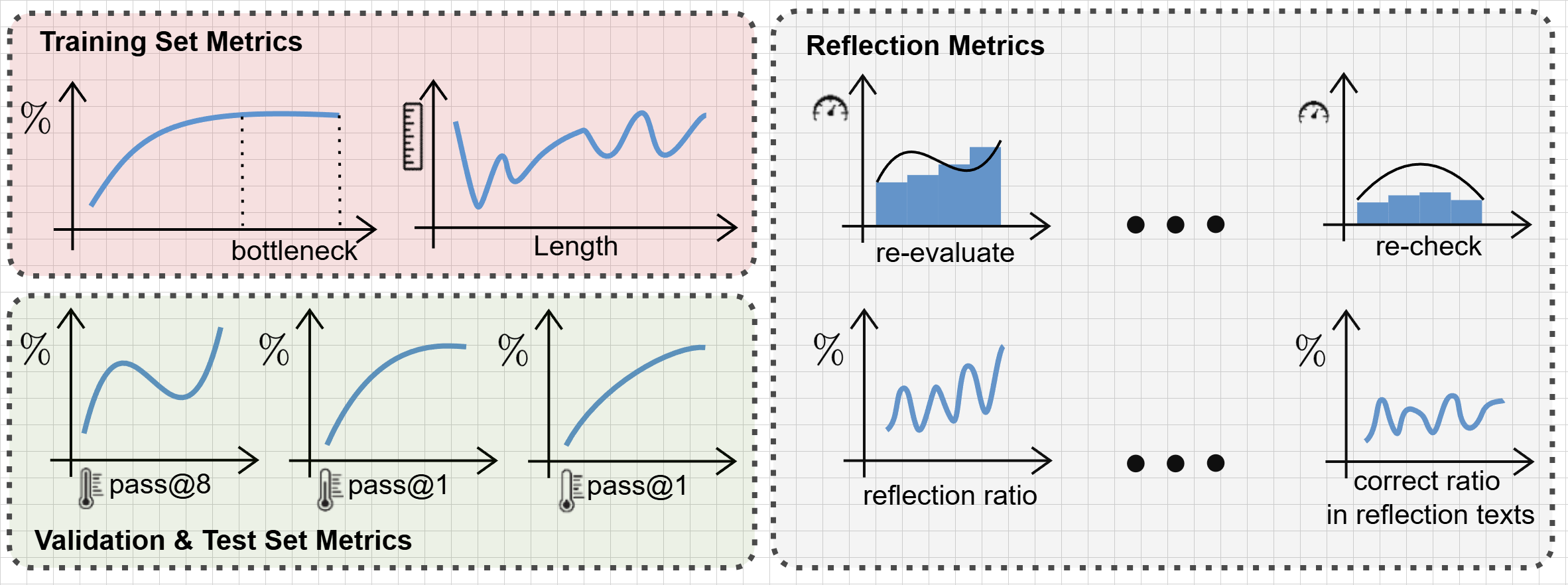
Figure 2: Overview of evaluation metrics.
The evaluation involves:
- Training Set Metrics: Including accuracy and response length, which serve as diagnostic signals during training.
- Validation and Test Set Metrics: Key measures of model capability and generalization performance.
- Reflection Metrics: Tracking model reasoning behaviors, such as identifying instances of self-correction or deeper reasoning during response generation.
Experimental Results
Extensive experiments were performed using the proposed framework, yielding several insights:
- RL Performance: RL consistently outperformed supervised fine-tuning (SFT) in terms of generalization ability on visual reasoning tasks.
- Reflection and Response Length: Training improves model reflection capabilities, often increasing response length, indicative of richer reasoning.
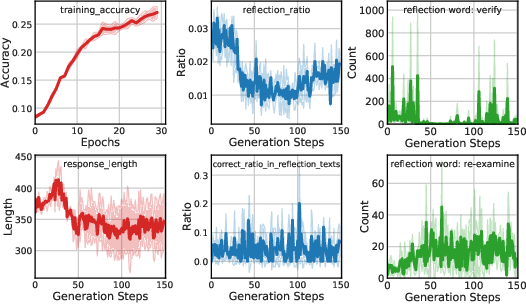
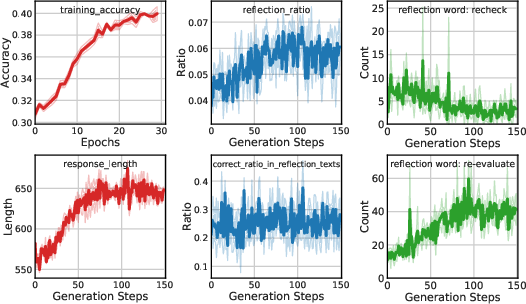
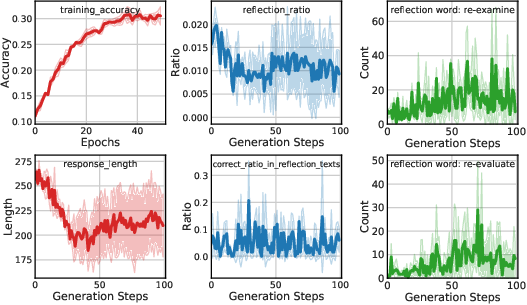
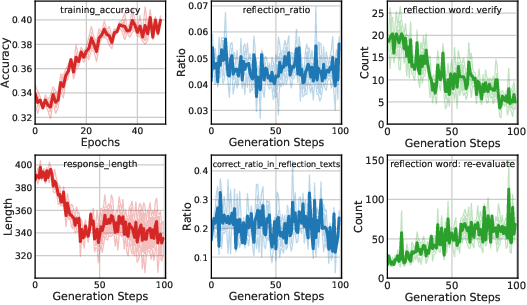
Figure 3: Qwen2-VL-Instruct-7B@mm_math5k.
The results demonstrate that the proposed framework provides a robust starting point for further research into RL for VLMs.
Implications and Future Work
The paper contributes to the field by providing a reproducible baseline and fostering engagement in RL-based VLM research. The framework's transparency and modularity support ease of customization, making it a valuable tool for both educational and research purposes. Future work includes refining the framework for better usability and extending its applicability to new architectures and diverse multimodal tasks.
Conclusion
"Rethinking RL Scaling for Vision LLMs" provides a clear, practical approach to applying reinforcement learning in VLM contexts. It addresses key gaps in reproducibility and evaluation, providing a foundation for future research and development in this area. The paper's findings highlight RL's superior generalization capabilities over traditional methods, marking an important step forward in AI research.