- The paper presents a hierarchical framework that decouples short and long-span dependencies using pre-trained segment embeddings and a masked-embedding autoencoder.
- It achieves significant performance improvements on benchmarks like LVU and COIN, with average accuracy gains of 5.3% and over 10% on select tasks.
- The method offers efficient training with reduced memory usage by tokenizing long videos into segment-level embeddings, enabling scalable long video analysis.
LV-MAE: Learning Long Video Representations through Masked-Embedding Autoencoders
Introduction and Motivation
The LV-MAE framework addresses the challenge of long video representation learning by decoupling short-span and long-span dependencies. Existing video models predominantly operate at the frame or patch level, which severely limits scalability due to quadratic attention complexity and high memory requirements. LV-MAE circumvents these limitations by leveraging advanced multimodal encoders (e.g., LanguageBind, InternVideo2) to extract robust short-video segment embeddings, which are then processed by a masked-embedding autoencoder to capture long-range dependencies across extended video sequences.
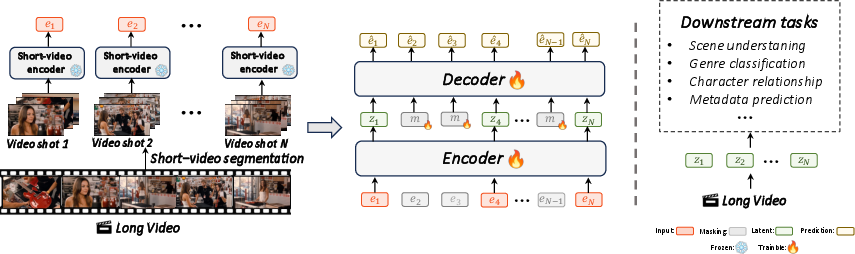
Figure 1: Overview of the LV-MAE method, illustrating the hierarchical processing of long videos via short-video segment embeddings and masked-embedding autoencoding.
This hierarchical approach enables efficient self-supervised pre-training on videos ranging from minutes to hours, with the capacity to process thousands of frames. The method is not constrained by the number of input frames and is highly efficient in terms of both training cost and memory usage.
Methodology
Short-Video Segmentation and Embedding Extraction
A long video V is segmented into N consecutive short clips (typically five seconds each). Each segment is processed by a frozen, pre-trained multimodal encoder (e.g., LanguageBind, InternVideo2), yielding a sequence of embeddings E={ei}i=1N, where ei∈Rd.
Masked-Embedding Autoencoder Architecture
LV-MAE adopts an asymmetric encoder-decoder architecture inspired by MAE [he2022masked]. The encoder receives only the visible (unmasked) embeddings, augmented with positional encodings. The decoder reconstructs the full sequence, including masked tokens represented by a shared, learnable vector, also with positional encodings. The reconstruction loss is the mean squared error (MSE) between the original and reconstructed masked embeddings.
Masking strategies include random masking and semantic masking. Semantic masking selects tokens with low cosine similarity to their predecessors, focusing on salient or distinct video segments to encourage learning of complex dependencies.
Handling Variable-Length Videos
Sequences are capped at 256 tokens, with shorter sequences padded and attention masks applied to prevent padding tokens from influencing training. This design supports arbitrary video lengths while maintaining computational efficiency.
Training Regime
Pre-training is performed on a diverse corpus of over 1,000 long-length movies and TV series, supplemented by public datasets (FineVideo, MovieClips, ActivityNet). The model is trained in a self-supervised manner, requiring no manual annotations. Training efficiency is demonstrated by the drastic reduction in token count: a two-minute video requires only 24 tokens (one per five-second segment), compared to 11,760 tokens for frame-level approaches.
Empirical Results
LV-MAE achieves state-of-the-art performance on three long-video benchmarks: LVU, COIN, and Breakfast. Notably, only a simple classification head (attentive or linear probing) is required for downstream tasks.
- On LVU, LV-MAE with LanguageBind embeddings outperforms prior methods in seven out of nine tasks, with an average accuracy improvement of 5.3% and improvements exceeding 10% on specific tasks.
- On COIN, LV-MAE surpasses all existing methods using both InternVideo2 and LanguageBind embeddings.
- On Breakfast, LV-MAE achieves the second-best performance.
The model's efficiency is further highlighted by its training time: 2.5 days on a single NVIDIA A10 GPU or 20 hours on 8 A10 GPUs.
Ablation Studies and Model Properties
Masking Ratio
A moderate masking ratio (40–50%) yields optimal performance for attentive probing.
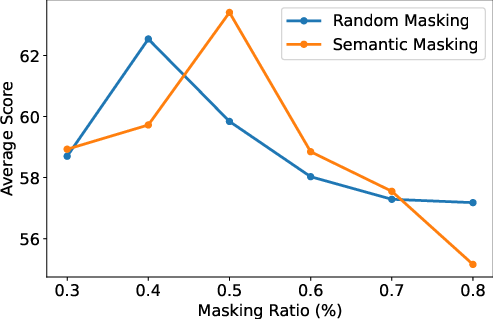
Figure 2: LVU average accuracy as a function of masking ratio, showing optimal results at 40–50% masking.
Masking Strategy
Semantic masking consistently outperforms random masking, particularly for linear probing, indicating that masking salient segments enhances the model's ability to learn long-range dependencies.
Probing Strategies
Attentive probing (AP) consistently outperforms linear probing (LP), especially for tasks requiring fine-grained temporal distinctions. AP's attention mechanism enables retention of subtle, task-specific context.
Model Depth
Increasing encoder depth improves accuracy across all benchmarks, with 32 layers yielding the best results.
Interpretable Predictions
Direct visualization of reconstructed embeddings is challenging due to their abstract nature. LV-MAE leverages the aligned video-language space of the short-video encoder for interpretability. For each reconstructed masked embedding, retrieval is performed against a large set of captions, enabling semantic assessment of reconstruction quality.
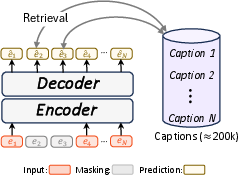
Figure 3: Schematic of interpretable prediction retrieval, matching reconstructed embeddings to captions from the MovieClip dataset.

Figure 4: Examples of interpretable predictions, showing original and retrieved captions for visible and reconstructed masked tokens, respectively.

Figure 5: Additional examples of interpretable predictions, demonstrating semantic alignment between reconstructed embeddings and retrieved captions.
The model's predictions tend to be semantically abstract, capturing the essence of scenes rather than fine details, analogous to the behavior of MAE models in the image domain.
Limitations
LV-MAE's performance is bounded by the quality of the frozen short-video encoder. If the encoder fails to capture relevant content, this limitation propagates to the long-range representation. Additionally, the abstract nature of embeddings complicates direct interpretability, though the proposed caption retrieval strategy provides a practical proxy.
Implications and Future Directions
LV-MAE demonstrates that masked autoencoding over sequences of segment-level embeddings is a scalable and effective paradigm for long video understanding. The approach enables efficient self-supervised pre-training on arbitrarily long videos, unlocking new possibilities for long-form content analysis. The framework is readily extensible to tasks beyond classification, including retrieval and generative modeling.
Potential future developments include:
- Joint fine-tuning of both the short-video encoder and LV-MAE for end-to-end optimization.
- Extension to multimodal generative tasks, leveraging the learned long-range representations.
- Scaling to hour-long or multi-hour videos, facilitated by the efficient tokenization scheme.
Conclusion
LV-MAE introduces a principled, efficient framework for long video representation learning via masked-embedding autoencoders. By decoupling short-span and long-span modeling and leveraging robust pre-trained segment encoders, LV-MAE achieves superior performance on long-video benchmarks with minimal fine-tuning. The method's scalability, efficiency, and interpretability position it as a strong foundation for future research in long-form video analysis and related multimodal tasks.