- The paper presents a novel fusion architecture that combines pre-trained foundation features with soft prompt adaptation to enhance 3D object detection performance.
- It integrates a Vision Transformer-based foundational branch with a multi-modal soft-prompt adapter, achieving 1.19% higher NDS and 2.42% improved mAP on nuScenes.
- The approach demonstrates practical robustness with limited training data, paving the way for advanced applications in autonomous driving and robotics.
PF3Det: A Prompted Foundation Feature Assisted Visual LiDAR 3D Detector
Introduction
The paper "PF3Det: A Prompted Foundation Feature Assisted Visual LiDAR 3D Detector" introduces an innovative LiDAR-camera fusion approach for 3D object detection. Traditional methods rely heavily on LiDAR or camera data alone, often resulting in limitations regarding depth precision and semantic richness. By leveraging the strengths of both modalities, PF3Det enhances detection robustness and accuracy through effective fusion techniques, especially in scenarios with limited training data. The research builds on the advancements in foundation models to achieve state-of-the-art performance in multi-modal 3D object detection.
Methodology
PF3Det employs a dual-branch architecture wherein foundational model encoders from large-scale pre-training are integrated into the detection pipeline. The process involves two key modules: the foundational branch and the multi-modal soft-prompt adapter.
- Foundational Branch: Integrates features from large-scale pre-trained models to assist with feature extraction, thereby enriching the semantic understanding of the scene. The model uses a Vision Transformer (ViT-L) as the backbone for extracting global context.
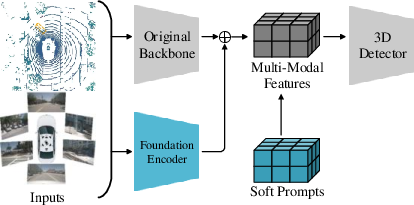
Figure 1: The architecture of our proposed PF3Det. The Foundational branch is added in parallel with the original image backbone. Multi-modal soft-prompt adapter is inserted at the BEV feature level.
- Multi-modal Soft-Prompt Adapter: Introduces learnable soft prompts at various stages of the bird's eye view (BEV) pipeline to enhance feature fusion between LiDAR and camera data. This prompt engineering approach adapts pre-trained networks for downstream tasks without modifying pre-existing weights.
Experimental Results
The model was evaluated on the nuScenes dataset, demonstrating significant improvements over existing benchmarks. PF3Det achieves an increase of 1.19% in the nuScenes detection score (NDS) and a 2.42% improvement in mean Average Precision (mAP) under conditions of limited training data.
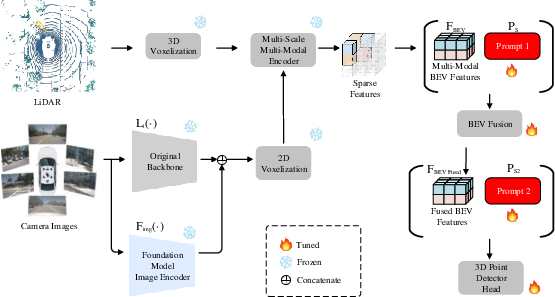
Figure 2: Multi-level multi-modal soft-prompt adapter. Three levels with four sets of soft prompts are tested. And weights after the first prompts are set to be learnable to better fuse features and prompts.
The paper situates its contributions within the context of multi-modal detection and foundation models. Prior approaches have explored various fusion techniques categorized as early, intermediate, and late fusion, each with specific advantages in terms of efficiency and semantic integration. PF3Det builds on this work by employing recent advancements in large-scale pre-trained models, specifically adapting these foundational encoders for improved feature alignment in 3D object detection tasks.
Contributions and Implications
The primary contributions of the PF3Det model include:
- A novel architecture that combines foundational model features with learned prompts for effective multi-modal data fusion.
- Demonstrated state-of-the-art performance on challenging datasets with minimal labeled data requirements.
- Insights into model parameter selection and configuration for optimal performance.
The implications of this work extend to applications in autonomous driving and robotics, where robust and precise object detection is critical, especially in environments with sparse training data. Future research could explore extending this framework to other tasks and modalities, enhancing adaptability and efficiency across various domains.
Conclusion
The PF3Det framework introduces a compelling approach to multi-modal 3D object detection by harnessing the capabilities of foundational models and prompt engineering. Its ability to function effectively with limited labeled data marks a significant advancement in the field, setting a new benchmark for future research in efficient and robust multi-modal fusion techniques.